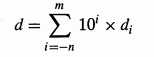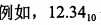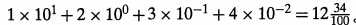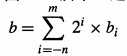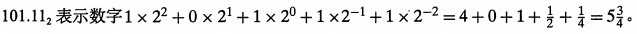标签:
二进制小数
10进制表示方式
2进制表示方式
可以看出二进制小数的小数点没左移一位,相当于除2
但二进制只能表示能写成x*2^y的小数
对于其他值只能近似的表示
IEEE浮点表示
IEEE标准采用类似于科学计数法的方式表示浮点小数,即我们将每一个浮点数表示为 V = (-1)s * M * 2E 。
s 符号位
M 尾数,是个二进制小数,取值范围为[1,2)(规格化的值),[0,1)(非规格化的值)
E 阶码
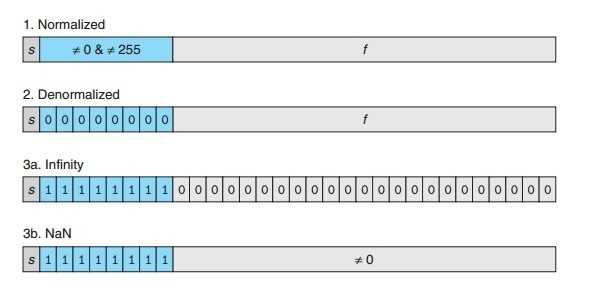
浮点数的位表示被分为三个部分
s 1个符号位
exp k位的阶码字段 用于表示E
frac n位的小数字段 用于表示M
浮点数编码分为三种
规格化
非规格化
特殊值(无穷大,非数字NaN)
规格化
最常见的格式,这种格式的阶码字段的位模式不是全0也不是全1
上面说了,阶码就是2E的E
是2的指数,所以E可正可负
阶码的值是用移码表示的,这里实际是想用无符号的值来表示有符号的数.
补充
所谓移码,简单的说就是偏移数的取值范围
补码表示的负数,在比较时候很不直观。
比如
010101,101011
容易认为后者较大,但事实相反
所谓移码就是对于w位的补码,给它加上2w。即可,这可以算是用“无符号表示有符号”。这样之后就能很直观的比较两个移码的大小。
移码的缘由是阶码
所以,要给阶码表示的值减去上一个偏移量Bias,使得原本无符号的阶码能够表示有无符号值
Bias=2^(k-1)-1 k为阶码位长度
Bias单精度为127,Bias双精度为1023
这里可以看到阶码字段的取值范围变为了[-126,127]。
那么-127和128去哪了?
取-127代表趋近于0的数,128代表无穷大或溢出的数。
那么现在阶码E=e-Bias,其中e是阶码字段代表的数
另外规格化的数字尾数 M=1.阶码字段 ,即隐含的以1开头的小数,即并未保存这个1,而计算时默认开头有1。
为什么这样做呢?
这样的目的是为了多一个精度位。我们通过阶码调整尾码,使之总是1开头的小数,例如1.01010101......,。但尾码字段却不记录这个开头1,所以我们多了一位去记录小数,这样数字将更精确。
阶码使用移码表示的好处
易比较
可表示特殊值
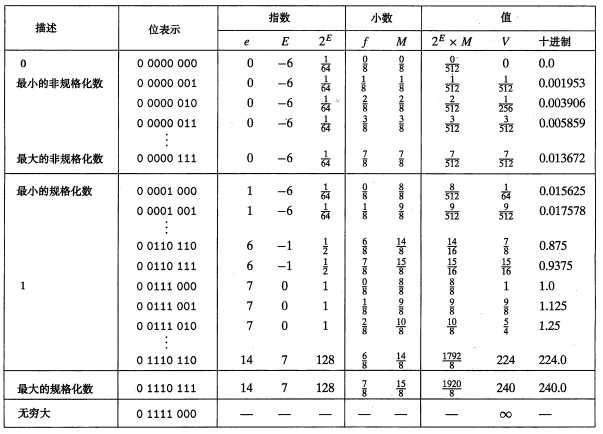
非规格化
阶码字段全为0
此时尾码开头不再有隐含1。
非格式化的两个用途
由于格式化数的尾码开头默认有个1,所以格式化数不可能表示0
但此时阶码值为E=1-Bias,而不会像格式化值一样E=-Bias。
之所以会多加1,是为了非格式化能够平滑地转换为格式化数。
举个例子
假定的8位浮点格式的示例,其中有k=4的阶码位和n=3的小数位。偏置量2^(4-1)-1=7。
由于格式化数硬生生地在尾码的开头加了个1即偏移了一个位,但非格式化却没这个1,于是要给E加一个1。
特殊值
当阶码全为1的时候出现。
当小数域全0时,表示无穷。符号位s为0是正无穷,1是负无穷。
当小数域非0时结果是NAN(非数字)
舍入
IEEE有四种不同的舍入方式
- 向偶数舍入(大部分像四舍五入,但.5会偏向偶数,比如4.5-->4,3.5-->4)
- 向零舍入
- 向下舍入
- 向上舍入
除了向偶数舍入,其余三种都产生实际值的确界。即舍入的结果都一定或大于或小于原值。
而向偶数舍入多用于统计。
书上没有具体的实现
浮点运算
浮点加法不具有结合性
a+b+c!=a+(b+c)
对于编译器默认的优化策略,将可能出现问题
x=a+b+c;
y=b+c+d;
优化
t=b+c;
x=a+t;
y=t+d;
案例
把12345[11000000111001]变成IEEE单精度浮点数
- 将2进制小数点左13位,12345=1.1000000111001X2^13
- 去掉开头1,末尾加10个0,以此构造小数字段,[10000001110010000000000]
- 为了构造阶码,13加上偏置量127,得140[10001100]
- 加上开头的符号位0
- 最后得[0 10001100 10000001110010000000000]
《深入理解计算机系统》2.4浮点数
标签:
原文地址:http://www.cnblogs.com/Recoding/p/4948489.html