标签:
刘 勇 Email:lyssym@sina.com
简介
在研究文本推荐算法时,需要挖掘关键字之间的规则,其中比较重要的一步是构建关键字的集合,即需要求取一个集合的所有子集。因此本文根据需求,采用3种方式实现该算法,以期对后续算法研究提供帮助。
本文下面从二叉树递归、位图和集合3个角度,对该算法进行研究与实现。
二叉树递归
为简要描述,采用数据集为:A= {1,2,3}。二叉树递归如下图-1所示。
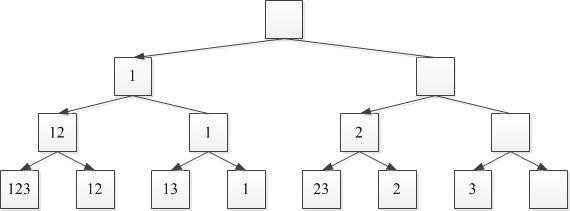
图-1 二叉树递归过程
对图-1采用二叉树递归解释为:集合中每个元素有2中状态,属于某个集合,或者不属于该集合,因此求取子集的过程则为对每个元素进行取舍的过程。如图-1所示,根节点为初始状态,叶子节点为终结状态,除第一层(根节点)为,后续每一层即为对每个元素展开的一次取舍操作。整个过程采用二叉树的先序遍历。
1 import java.util.List; 2 import java.util.ArrayList; 3 4 public class SubSet { 5 private List<List<String>> listList = null; 6 7 public SubSet(List<String> list) 8 { 9 listList = new ArrayList<List<String>>(); 10 int len = list.size(); 11 List<String> dst = new ArrayList<String>(); 12 for (int i = 0; i < len; i++) { 13 generate(list, 0, i, dst); 14 } 15 } 16 17 18 public void generate(List<String> list, int index, int number, List<String> dst) { 19 if (number == -1) { 20 List<String> strList = new ArrayList<String>(); 21 for (String s : dst) 22 strList.add(s); 23 listList.add(strList); 24 return; 25 } 26 27 if (index == list.size()) { 28 return; 29 } 30 String element = list.get(index); 31 dst.add(element); 32 generate(list, index+1, number-1, dst); 33 dst.remove(element); 34 generate(list, index+1, number, dst); 35 } 36 37 38 public void printList() 39 { 40 for (List<String> list : listList) { 41 for (String s : list) { 42 System.out.print(s + "\t"); 43 } 44 System.out.println(); 45 } 46 } 47 }
位图
为描述方便,采用数据集为:A= {1,2,3}。对于任意一个元素,属于某个集合或者不属于该集合。前述集合以“1”为存在于集合,若为“0”则不存在于该集合,采用位图映射为:
{1,2,3}
{0,0,0}-->{}
{0,0,1}-->{3}
{0,1,0}-->{2}
{0,1,1}-->{2,3}
{1,0,0}-->{1}
{1,0,1}-->{1,3}
{1,1,0}-->{1,2}
{1,1,1}-->{1,2,3}
import java.util.List; import java.util.ArrayList; public class BitSet { private List<List<String>> listList= null; public BitSet(List<String> list) { listList = new ArrayList<List<String>>(); int len = list.size(); int mark = 0; long end = (1<<len) -1; // 2^len-1 for (mark = 0; mark <= end; mark++) { List<String> dst = new ArrayList<String>(); for (int i = 0; i < len ; i++) { if ((1<<i & mark) != 0) { // i has one element dst.add((list.get(i))); } } if (dst.size() > 0) { listList.add(dst); } } } public void printList() { for (List<String> list : listList) { for (String s : list) { System.out.print(s + "\t"); } System.out.println(); } } }
集合
为描述方便,采用数据集为:A={1,2,3,4},其根据两个上一级目标集合生成下一级的目标集合,其核心解决方案为通过上一层集合的前K-2个元素相同(K为新集合的元素个数),则将上一层集合元素合并生成新的集合,如A31={1,2,3},A32={1,2,4},则生成新的目标集合A41={1,2,3,4},该方案最大的优点是:使得生成的集合中,元素没有重复。
1 import java.util.ArrayList; 2 import java.util.List; 3 import java.util.Set; 4 import java.util.TreeSet; 5 6 public class SetSet { 7 private List<List<Set<String>>> L = null; 8 9 public SetSet(List<String> set) { 10 List<Set<String>> initSet = createInitSet(set); 11 L = new ArrayList<List<Set<String>>>(); // contains all the subsets 12 L.add(initSet); 13 int k = 2; 14 while (L.get(k-2).size() > 0) { 15 List<Set<String>> Ck = aprioriGen(L.get(k-2), k); 16 L.add(Ck); // add the C(k) and the generate C(k+1) 17 k += 1; 18 } 19 } 20 21 /** 22 * create one list 23 * @param set : the data set 24 * @return the list generated 25 */ 26 public List<Set<String>> createInitSet(List<String> set) 27 { 28 List<Set<String>> list = new ArrayList<Set<String>>(); 29 for (String element : set) { 30 Set<String> e = new TreeSet<String>(); 31 e.add(element); 32 if (!list.contains(e)) 33 list.add(e); 34 } 35 return list; 36 } 37 38 /** 39 * generate the number of k items 40 * @param list : the source list 41 * @param k : the numbers 42 * @return the list with set 43 */ 44 public List<Set<String>> aprioriGen(List<Set<String>> list, int k) 45 { 46 List<Set<String>> retList = new ArrayList<Set<String>>(); 47 int size = list.size(); 48 for (int i = 0; i < size; i++) { 49 Set<String> set1 = list.get(i); 50 for (int j = i+1; j < size; j++) { 51 Set<String> set2 = list.get(j); 52 if (isEquals(getSubclass(list.get(i), k-2), getSubclass(list.get(j), k-2))) { // the 0:k-2 contain the same elements 53 retList.add(getUnion(set1, set2)); 54 } 55 } 56 } 57 return retList; 58 } 59 60 /** 61 * get the union of two sets 62 * @param src : the source set 63 * @param dst : destination set 64 * @return one set 65 */ 66 public Set<String> getUnion(Set<String> src, Set<String> dst) 67 { 68 Set<String> set = new TreeSet<String>(); 69 for (String element : src) 70 set.add(element); 71 72 for (String item : dst) 73 if (!set.contains(item)) 74 set.add(item); 75 76 return set; 77 } 78 79 /** 80 * get the top K elements of the set 81 * @param src : the source set 82 * @param k : the top K 83 * @return the top K elements 84 */ 85 public Set<String> getSubclass(Set<String> src, int k) 86 { 87 Set<String> set = new TreeSet<String>(); 88 int index = 0; 89 for (String s : src) { 90 if (index < k) 91 set.add(s); 92 else 93 break; 94 95 index++; 96 } 97 return set; 98 } 99 100 /** 101 * assert the equals of tow sets 102 * @param src : the source set 103 * @param dst : the destination set 104 * @return if src == dst, return true else return false 105 */ 106 public boolean isEquals(Set<String> src, Set<String> dst) 107 { 108 boolean ret = false; 109 if (src.size() == dst.size()) { 110 if (src.size() == 0) 111 ret = true; 112 else if (src.containsAll(dst)) 113 ret = true; 114 } 115 return ret; 116 } 117 }
由于本文在研究文本推荐时,参考《机器学习实战》,故此先入为主,采用了第三种方法。但是,本文作者并不认为第三种方法效率较高,在大规模数据时,作者倾向于先用方案二(位图运算)。
参考文献
[1] Peter Harrington, Machine Learning in action, 人民邮电出版社, 2015.4.
作者:志青云集
出处:http://www.cnblogs.com/lyssym
如果,您认为阅读这篇博客让您有些收获,不妨点击一下右下角的【推荐】。
如果,您希望更容易地发现我的新博客,不妨点击一下左下角的【关注我】。
如果,您对我的博客所讲述的内容有兴趣,请继续关注我的后续博客,我是【志青云集】。
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。
标签:
原文地址:http://www.cnblogs.com/lyssym/p/4950156.html