标签:
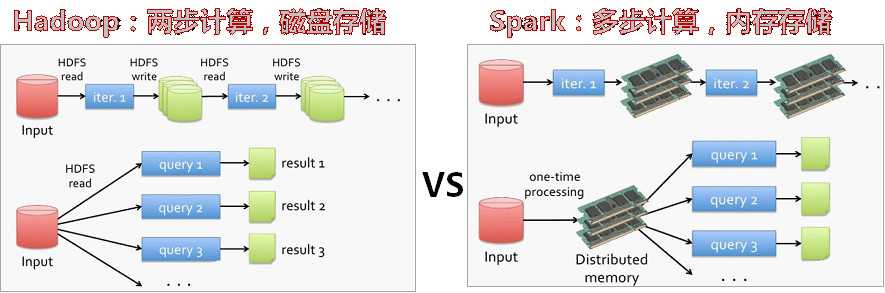
Spark是UC Berkeley AMP 实验室基于map reduce算法实现的分布式计算框架,输出和结果保存在内存中,不需要频繁读写HDFS,数据处理效率更高
Spark适用于近线或准实时、数据挖掘与机器学习应用场景
Spark和Hadoop
容错
–基于血统的容错,数据恢复
–checkpoint

checkpoint是一个内部事件,这个事件激活以后会触发数据库写进程(DBWR)将数据缓冲(DATABUFFER CACHE)中的脏数据块写出到数据文件中。
在数据库系统中,写日志和写数据文件是数据库中IO消耗最大的两种操作,在这两种操作中写数据文件属于分散写,写日志文件是顺序写,因此为了保证数据库的性能,通常数据库都是保证在提交(commit)完成之前要先保证日志都被写入到日志文件中,而脏数据块则保存在数据缓存(buffer cache)中再不定期的分批写入到数据文件中。也就是说日志写入和提交操作是同步的,而数据写入和提交操作是不同步的。这样就存在一个问题,当一个数据库崩溃的时候并不能保证缓存里面的脏数据全部写入到数据文件中,这样在实例启动的时候就要使用日志文件进行恢复操作,将数据库恢复到崩溃之前的状态,保证数据的一致性。检查点是这个过程中的重要机制,通过它来确定,恢复时哪些重做日志应该被扫描并应用于恢复。
一般所说的checkpoint是一个数据库事件(event),checkpoint事件由checkpoint进程(LGWR/CKPT进程)发出,当checkpoint事件发生时DBWn会将脏块写入到磁盘中,同时数据文件和控制文件的文件头也会被更新以记录checkpoint信息。
SparkStreaming
什么是SparkStreaming:
Spark是一个类似于Hadoop的MapReduce分布式计算框架,其核心是弹性分布式数据集(RDD,一个在内存中的数据集合),提供了比MapReduce更丰富的模型,可以在快速在内存中对数据集进行多次迭代,以支持复杂的数据挖掘算法和图形计算算法。 Spark拥有Hadoop MapReduce所具有的优点;但不同于Hadoop MapReduce的是计算任务中间输出和结果可以保存在内存中,从而不再需要读写HDFS,节省了磁盘IO耗,号称性能比Hadoop快100倍。 Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。即SparkStreaming 是基于Spark的流式计算框架。
Spark Streaming的优势在于:
1、能运行在100+的结点上,并达到秒级延迟。
2、使用基于内存的Spark作为执行引擎,具有高效和容错的特性。
3、能集成Spark的批处理和交互查询。
4、为实现复杂的算法提供和批处理类似的简单接口。
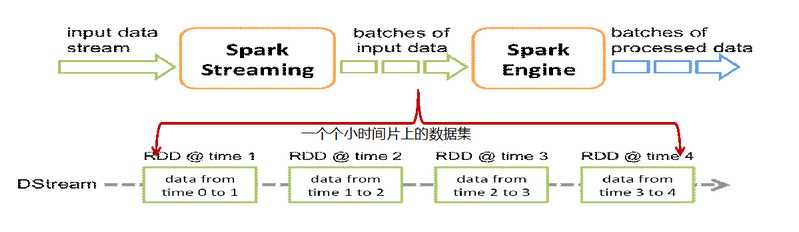
SparkStreaming原理

Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark,也就是把Spark Streaming的输入数据按照batch size(如1秒)分成一段一段的数据(Discretized Stream),每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将Spark Streaming中对DStream的Transformation操作变为针对Spark中对RDD的Transformation操作。
标签:
原文地址:http://www.cnblogs.com/tychyg/p/4950860.html