标签:
本文包含以下几个部分:
SVM简介
在进行下面的内容时我们认为你已经具备了数据挖掘的基础知识。
SVM是新近出现的强大的数据挖掘工具,它在文本分类、手写文字识别、图像分类、生物序列分析等实际应用中表现出非常好的性能。SVM属于监督学习算法,样本以属性向量的形式提供,所以输入空间是Rn的子集。
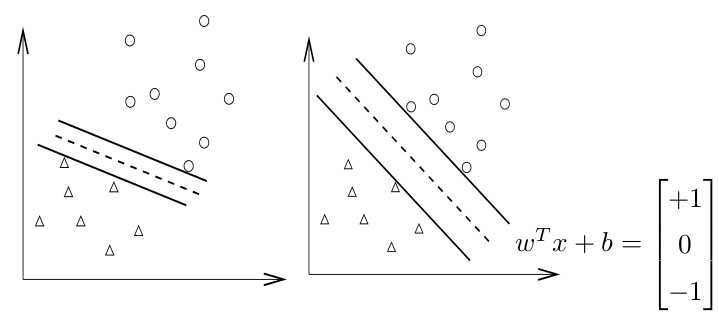
如图1所示,SVM的目标是找到两个间距尽可能大的边界平面来把样本本点分开,以”最小化泛化误差“,即对新的样本点进行分类预测时,出错的几率最小。落在边界平面上的点称为支持向量。Vapnik证明如果可以找到一个较小的支持向量集,就可以保证得到很好的泛化能力----也就是说支持向量的个数越少越好。
数据点通常在输入空间是线性不可分的,我们把它映射到更高维的特征空间,使其线性可分----这里的映射函数我们称之为核函数。特征空间的超平面对应输入空间的一个非线性的分离曲面,因此称为非线性分离器。
SVM分类器的输出是u=w*x-bw是分类平面的法矢,x是输入向量,b是常量,u代表分类。即SVM的目的就是计算出wb。最大化margin(两个分类平面之间的距离)等价于求下面的二次优化问题:
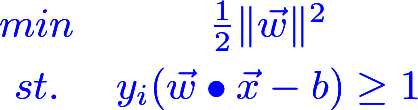
对于非线性分类器就要把x映射到特征空间,同时考虑误差的存在(即有些样本点会越过分类边界),上述优化问题变为:
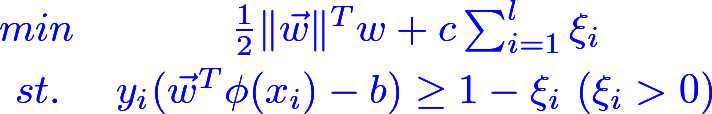
从输入空间是映射到特征空间的函数称为核函数,LibSVM中使用的默认核函数是RBF(径向基函数radial basis function)
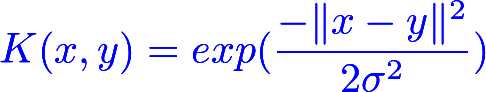
这样一来就有两个参数需要用户指定:gamma。实际上在LibSVM中用户需要给出一个gamma的区间,LibSVM采用交叉验证cross-validation accuracy的方法确定分类效果最好的gamma。
举个例子说明什么是交叉验证,假如把训练样本集拆成三组,然后先拿 train model predict 3 以得到正确率; 再来拿 3 train predict 1 ,最后 1,3 train predict 2 ,最后取预测精度最高的那组c和gamma。
有时属于不同分类的样本数是不平衡的,所以有人提出(二次优化)的目标函数应该为:
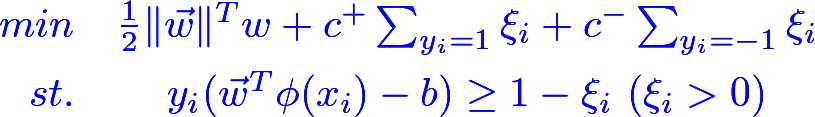
LibSVM中允许用户指定权重值
对于文本分类采用最简单的线性分类器即可,因为输入的文档向量矩阵高度稀疏,可以认为不需要映射到特征空间,在输入空间就线性可分, 这样我们就不需要使用核函数了----然而我的实践证明这个结论并不总是正确的。
LibSVM的安装
但要求电脑上装有1.5版本以上的java,并且设置好了$classpath全局变量。
LibSVM的使用
我们只讲Linux下Java版的使用,在有的VM上,java版的libsvm运行速度可逼近C++版的运行速度。
cd /path/to/libsvm-3.1/java
java -classpath libsvm.jar svm_scale <arguments>
java -classpath libsvm.jar svm_train <arguments>
java -classpath libsvm.jar svm_predict <arguments>
java -classpath libsvm.jar svm_toy
LibSVM要求处理的文件数据都满足如下格式:
rlabel1 index1:value1 index2:value2 …...
rlabel2 index1:value1 index2:value2 …...
下面的脚本是我用于转换成LibSVM要求的文件格式用的,作个备份:
#!/usr/bin/perl $file="/home/orisun/libsvm/testvec"; $file2="/home/orisun/libsvm/testvec_svmfmt"; #$file="/home/orisun/libsvm/trainvec"; #$file2="/home/orisun/libsvm/trainvec_svmfmt"; open VFILE,"$file"; open FFILE,">$file2"; while(<VFILE>){ chomp; my @cont=split; $no=$cont[0]; my $rlable; #$rlable=int($no%1000); if($no eq "C39"){ $rlable=0; }elsif($no eq "C31"){ $rlable=1; }elsif($no eq "C32"){ $rlable=2; }elsif($no eq "C38"){ $rlable=3; }elsif($no eq "C34"){ $rlable=4; }elsif($no eq "C19"){ $rlable=5; } print FFILE "$rlable\t"; for($i=1;$i<@cont;$i++){ if($cont[$i]!=0){ print FFILE "$i:$cont[$i]\t"; } } print FFILE "\n"; }
libsvm在存储中存储数据时默认采用的是float,而不是double。当你原始数据精度要求很高时这确实是个问题。
rlabel表示分类,为一个数字。Index开始递增,表示输入向量的序号,value是输入向量相应维度上的值,如果value该项可以不写。下面是一个示例文件:
3.2 31.6
1.5 24.2 30.5
5.1 21.6 32.0
5.4
svm_scale用于把输入向量按列进行规范化(或曰缩放)。
Usage: svm-scale [options] data_filename
options:
-l lower : x scaling lower limit (default -1)
-u upper : x scaling upper limit (default +1)
-y y_lower y_upper : y scaling limits (default: no y scaling)
-s save_filename : save scaling parameters to save_filename
-r restore_filename : restore scaling parameters from restore_filename
举个例子,比如我运行:java svm_scale -l 0 -u 1 -s range train > train.scale则输入文件是train,输出文件是 train.scale,把输入向量的各列都缩放到的范围内,range文件中保存了相关的缩放信息。
Train文件原来的内容:
1 1:0 2:0
1 1:3 2:4
1 1:5 2:9
1 1:12 2:1
1 1:8 2:7
0 1:9 2:8
0 1:6 2:12
0 1:10 2:8
0 1:8 2:5
0 1:14 2:8
range文件自动生成:
0.000000000000000 1.000000000000000
1 0.000000000000000 14.00000000000000
2 0.000000000000000 12.00000000000000
train.scale文件自动生成:
1.0
1.0 1:0.21428571428571427 2:0.3333333333333333
1.0 1:0.35714285714285715 2:0.75
1.0 1:0.8571428571428571 2:0.08333333333333333
1.0 1:0.5714285714285714 2:0.5833333333333334
0.0 1:0.6428571428571429 2:0.6666666666666666
0.0 1:0.42857142857142855 2:1.0
0.0 1:0.7142857142857143 2:0.6666666666666666
0.0 1:0.5714285714285714 2:0.4166666666666667
0.0 1:1.0 2:0.6666666666666666
然后我再运行:java svm_scale -r range test > test.scale意思是说从range文件中读取缩放信息运用于test文件,输出test.scale文件。
向量规范化后我们train一下训练样本,以生成支持向量。
运行:java svm_train -s 0 -c 5 -t 2 -g 0.5 -e 0.01 train.scale
对于文本分类svm_train中有几个选项会用到:
-s svm_type : set type of SVM (default 0)
0 -- C-SVC
-t kernel_type : set type of kernel function (default 2)
0 -- linear: u‘*v
2 -- radial basis function: exp(-gamma*|u-v|^2)
-g gamma : set gamma in kernel function (default 1/num_features) num_features是输入向量的个数
-c cost : set the parameter C of C-SVC, epsilon-SVR, and nu-SVR (default 1)
-m cachesize : set cache memory size in MB (default 100) 使用多少内存
-e epsilon : set tolerance of termination criterion (default 0.001)
-h shrinking : whether to use the shrinking heuristics, 0 or 1 (default 1)
-wi weight : set the parameter C of class i to weight*C, for C-SVC (default 1) 当各类数量不均衡时为每个类分别指定
-v n: n-fold cross validation mode交叉验证时分为多少组
-q : quiet mode (no outputs)
会生成train.scale.model文件,内容如下:
svm_type c_svc
kernel_type rbf
gamma 0.5
nr_class 2
total_sv 9
rho -0.5061570424019811
label 1 0
nr_sv 4 5
2.7686973549711875 1:0.21428571428571427 2:0.3333333333333333
5.0 1:0.35714285714285715 2:0.75
5.0 1:0.8571428571428571 2:0.08333333333333333
5.0 1:0.5714285714285714 2:0.5833333333333334
-5.0 1:0.6428571428571429 2:0.6666666666666666
-2.4351637665059895 1:0.42857142857142855 2:1.0
-5.0 1:0.7142857142857143 2:0.6666666666666666
-5.0 1:0.5714285714285714 2:0.4166666666666667
-0.3335335884651968 1:1.0 2:0.6666666666666666
nr_class代表训练样本集有几类,rho是判决函数的常数项nr_sv是各个类中落在边界上的向量个数,下面枚举了所有的支持向量,每个支持向量前面都有一个数字,代表什么我现在也不清楚。
当train C-SVM时会有类似下面的输出:
optimization finished, #iter = 219
nu = 0.431030
obj = -100.877286, rho = 0.424632
nSV = 132, nBSV = 107
Total nSV = 132
obj是对SSVM问题的优化目标函数的值。rho是决策函数中的常数项b。nSV是支持向量的个数,nBSV是边界支持向量的个数(i.e., alpha_i = C)。
如果“自由支持向量”个数很多,很可能是因为过拟合了。如果输入数据的attribute在一个很大的范围内分布,最好scale一下。
采用时默认的核函数RBF是比较好的,if RBF is used with model selection, then there is no need to consider the linear kernel.
如果预测的准确率太低,如何提高一下?使用python目录下的grid.py进行模型选择以找到比较好的参数。
grid.py是一种用于RBF核函数的C-SVM分类的参数选择程序。用户只需给定参数的一个范围,grid.py采用交叉验证的方法计算每种参数组合的准确度来找到最好的参数。
Usage: grid.py [-log2c begin,end,step] [-log2g begin,end,step] [-v fold]
[-svmtrain pathname] [-gnuplot pathname] [-out pathname] [-png pathname]
[additional parameters for svm-train] dataset
The program conducts v-fold cross validation using parameter C (and gamma)= 2^begin, 2^(begin+step), ..., 2^end.
首先sudo apt-get install gnuplot
然后编译C++版本的LibSVM,生成svm-train二进制可执行文件。
cd /path/to/libsvm-3.1
make
举个例子就都明白了:python grid.py -log2c -5,5,1 -log2g -4,0,1 -v 5 -svmtrain /home/orisun/develop/libsvm-3.1/svm-train -m 500 traincev_svmfmt_part1
-m 500是使用svm_train时可以使用的参数。
最后输出两个文件:dataset.png绘出了交叉验证精度的轮廓图,dataset.out对于每一组log2(c)和log2(gamma)对应的CV精度值。
如果训练时间过长,你可能需要:
1.指定更大有cache size。(-m)
2.使用更宽松的stopping tolerance。(-e)
当使用一个很大有-e时,你可能需要检查一下-h 0 (no shrinking) or -h 1 (shrinking)哪个更快。
3.如果上面的方法还不行就需要裁剪训练集。使用tools目录下的subset.py来随机获得训练集的一个子集。
Usage: subset.py [options] dataset number [output1] [output2]
This script selects a subset of the given data set.
options:
-s method : method of selection (default 0)
0 -- stratified selection (classification only)
1 -- random selection
output1 : the subset (optional)
output2 : the rest of data (optional)
If output1 is omitted, the subset will be printed on the screen.
当迭代次数很高时使用shrinking是有帮助的,而当使用一个很大的-e时,迭代次数会减少,最好把shrinking关掉。
当指定一个很大-m时Linux会报"段错误“,很可能是内存溢出了。对于32位的机子最大的可编址内存是4G。同时Linux系统按照3:1来划分用户空间:核空间,所以用户空间只有最大只有3G,而可动态分配的内存最大只有2G。当你使用一个接近2G的-m时内存就会耗尽。
解决办法:
1.换64位的机子。
2.如果你的机子支持Intel‘s PAE (Physical Address Extension),你可以在Linux内核中开启HIGHMEM64G选项,这样核空间和用户空间的划分就是4G:4G。
3.安装"tub”软件,它可以消除动态分配内存只有2G的限制。tub可以在这里获取 http://www.bitwagon.com/tub.html。
在svm_train的过程中如果不想看到中间输出可以使用-q选项。
如果你是在编程代码中使用libsvm库,可以这样:
1.声明一个空的输出函数:void print_null(const char *s) {}
2.把它赋给libsvm库中的输出函数:svm_print_string = &print_null;
在处理多类分类问题时,libsvm采用的是one-against-one,而不是one-against-the rest,实际上后者的性能要好,而之所以采用前者仅仅是因为它快。
交叉验证是为了选择更好的参数,做完交叉验证后并不会输出model文件,此时你需要re-train the whole data without the -v option。
如果你有多核/共享内存的计算机,libsvm还允许你采用OpenMP进行并行编程。
预测时如果开启-b则会耗费更长的时间,并且开启-b和提高预测的准确率并没有绝对的关系。
最后可以预测分类了,运行:java svm_predict test.scale train.scale.model result
test.scale 是待预测的文件, train.scale.model是利用训练文本集生成的model文件,最终会生成result文件,内容如下:
1.0
1.0
0.0
1.0
0.0
0.0
0.0
0.0
1.0
0.0
由于在 test.scale中我已标记了正确的rlable,所以 svm_predict还会报告正确率Accuracy = 70.0% (7/10) (classification)。在实际的分类问题中,我们当然是无法提前知道待分类文件中的rlabel中,可以任意标记一个数字,这时候还会给出Accuracy ,不过它是毫无意义的。
在使用svm_toy时只支持3种颜色,最大分类数是3。如果想有更多分类,需要修改原代码svm-toy.cpp。如果直接从文件中load数据,要求向量是2维的,并且每一维都在(0,1),同时rlabel只能是1、2、3(甚至不能是1.0、2.0、3.0)。
下面是使用svn_toy的一个截图:

LibSVM库函数的调用
库函数在"libsvm"包中。
在Java版中以下函数可以调用:
public class svm {
public static final int LIBSVM_VERSION=310;
public static svm_model svm_train(svm_problem prob, svm_parameter param);
public static void svm_cross_validation(svm_problem prob, svm_parameter param, int nr_fold, double[] target);
public static int svm_get_svm_type(svm_model model);
public static int svm_get_nr_class(svm_model model);
public static void svm_get_labels(svm_model model, int[] label);
public static double svm_get_svr_probability(svm_model model);
public static double svm_predict_values(svm_model model, svm_node[] x, double[] dec_values);
public static double svm_predict(svm_model model, svm_node[] x);
public static double svm_predict_probability(svm_model model, svm_node[] x, double[] prob_estimates);
public static void svm_save_model(String model_file_name, svm_model model) throws IOException
public static svm_model svm_load_model(String model_file_name) throws IOException
public static String svm_check_parameter(svm_problem prob, svm_parameter param);
public static int svm_check_probability_model(svm_model model);
public static void svm_set_print_string_function(svm_print_interface print_func);
注意在Java版中svm_node[]的最后一个元素的索引不是-1.
用户可以自定义自己的输出格式,通过:
your_print_func = new svm_print_interface()
public void print(String s)
// your own format
svm.svm_set_print_string_function(your_print_func);
标签:
原文地址:http://www.cnblogs.com/fclbky/p/4955267.html