首页
Web开发
Windows程序
编程语言
数据库
移动开发
系统相关
微信
其他好文
会员
首页
>
其他好文
> 详细
Hadoop2.7.1配置NameNode+ResourceManager高可用原理分析
时间:
2015-11-11 20:53:09
阅读:
409
评论:
0
收藏:
0
[点我收藏+]
标签:
关于NameNode高可靠需要配置的文件有core-site.xml和hdfs-site.xml
关于ResourceManager高可靠需要配置的文件有yarn-site.xml
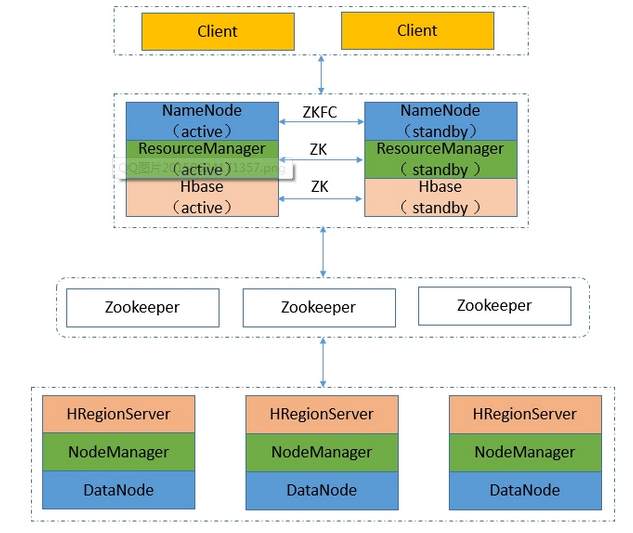
逻辑结构:
NameNode-HA工作原理:
在一个典型的HA集群中,最好有2台独立的机器的来配置NameNode角色,无论在任何时候,集群中只能有一个NameNode作为Active状态,而另一个是Standby状态,Active状态的NameNode负责集群中所有的客户端操作,这么设置的目的,其实HDFS底层的机制是有关系的,同一时刻一个文件,只允许一个写入方占用,如果出现多个,那么文件偏移量便会混乱,从而导致数据格式不可用,当然状态为Standby的NameNode这时候仅仅扮演一个Slave的角色,以便于在任何时候Active的NameNode挂掉时,能够第一时间,接替它的任务,成为主NameNode,达到一个热备份的效果,在HA架构里面SecondaryNameNode这个冷备角色已经不存在了,为了保持从NameNode时时的与主NameNode的元数据保持一致,他们之间交互通过一系列守护的轻量级进程JournalNode,当任何修改操作在主NameNode上执行时,它同时也会记录修改log到至少半数以上的JornalNode中,这时状态为Standby的NameNode监测到JournalNode里面的同步log发生变化了会读取JornalNode里面的修改log,然后同步到自己的的目录镜像树里面,当发生故障时,Active的NameNode挂掉后,Standby的NameNode会在它成为Active NameNode前,读取所有的JournalNode里面的修改日志,这样就能高可靠的保证与挂掉的NameNode的目录镜像树一致,然后无缝的接替它的职责,维护来自客户端请求,从而达到一个高可用的目的。
为了达到快速容错的掌握全局的目的,Standby角色也会接受来自DataNode角色汇报的块信息,前面只是介绍了NameNode容错的工作原理,下面介绍下,当引入Zookeeper之后,为啥可以NameNode-HA可以达到无人值守,自动切换的容错。
在主备切换上Zookeeper可以干的事:
(1)失败探测 在每个NameNode启动时,会在Zookeeper上注册一个持久化的节点,当这个NameNode宕机时,它的会话就会终止,Zookeeper发现之后,就会通知备用的NameNode,Hi,老兄,你该上岗了。
(2)选举机制, Zookeeper提供了一个简单的独占锁,获取Master的功能,如果那个NameNode发现自己得到这个锁,那就预示着,这个NameNode将被激活为Active状态
当然,实际工作中Hadoop提供了ZKFailoverController角色,在每个NameNode的节点上,简称zkfc,它的主要职责如下:
(1)健康监测,zkfc会周期性的向它监控的NameNode发送健康探测命令,从而来确定某个NameNode是否处于健康状态,如果机器宕机,心跳失败,那么zkfc就会标记它处于一个不健康的状态
(2)会话管理, 如果NameNode是健康的,zkfc就会在zookeeper中保持一个打开的会话,如果NameNode同时还是Active状态的,那么zkfc还会在Zookeeper中占有一个类型为短暂类型的znode,当这个NameNode挂掉时,
这个znode将会被删除,然后备用的NameNode,将会得到这把锁,升级为主NameNode,同时标记状态为Active,当宕机的NameNode,重新启动时,它会再次注册zookeper,发现已经有znode锁了,便会自动变为Standby状态,如此往复循环,保证高可靠,需要注意,目前仅仅支持最多配置2个NameNode。
(3)master选举,如上所述,通过在zookeeper中维持一个短暂类型的znode,来实现抢占式的锁机制,从而判断那个NameNode为Active状态。
core-site.xml里面
Xml代码
<
configuration
>
<
property
>
<
name
>
fs.default.name
</
name
>
<
value
>
hdfs://ns1
</
value
>
</
property
>
<
property
>
<
name
>
hadoop.tmp.dir
</
name
>
<
value
>
/ROOT/server/data-hadoop/hadooptmp
</
value
>
</
property
>
<
property
>
<
name
>
io.compression.codecs
</
name
>
<
value
>
org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.co
mpress.SnappyCodec
</
value
>
</
property
>
<
property
>
<
name
>
fs.trash.interval
</
name
>
<
value
>
0
</
value
>
<
description
>
Number of minutes between trash checkpoints.
If zero, the trash feature is disabled.
</
description
>
</
property
>
<!-- ha的zk的配置 -->
<
property
>
<
name
>
ha.zookeeper.quorum
</
name
>
<
value
>
h1:2181,h2:2181,h3:2181
</
value
>
</
property
>
</
configuration
>
hdfs-site.xml里面
Xml代码
<?
xml
version
=
"1.0"
encoding
=
"UTF-8"
?>
<?
xml-stylesheet
type
=
"text/xsl"
href
=
"configuration.xsl"
?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--
>
<!-- Put site-specific property overrides in this file. -->
<
configuration
>
<
property
>
<
name
>
dfs.replication
</
name
>
<
value
>
1
</
value
>
</
property
>
<!-- 集群数量小于3时,副本数大于1时,建议启用 -->
<!--
<
property
>
<
name
>
dfs.client.block.write.replace-datanode-on-failure.enable
</
name
>
<
value
>
false
</
value
>
</
property
>
--
>
<
property
>
<
name
>
dfs.namenode.name.dir
</
name
>
<
value
>
file:///ROOT/server/data-hadoop/nd
</
value
>
</
property
>
<
property
>
<
name
>
dfs.datanode.data.dir
</
name
>
<
value
>
/ROOT/server/data-hadoop/dd
</
value
>
</
property
>
<
property
>
<
name
>
dfs.permissions
</
name
>
<
value
>
false
</
value
>
</
property
>
<
property
>
<
name
>
dfs.nameservices
</
name
>
<
value
>
ns1
</
value
>
</
property
>
<
property
>
<
name
>
dfs.ha.namenodes.ns1
</
name
>
<
value
>
h1,h2
</
value
>
</
property
>
<
property
>
<
name
>
dfs.namenode.rpc-address.ns1.h1
</
name
>
<
value
>
h1:9000
</
value
>
</
property
>
<
property
>
<
name
>
dfs.namenode.http-address.ns1.h1
</
name
>
<
value
>
h1:50070
</
value
>
</
property
>
<
property
>
<
name
>
dfs.namenode.rpc-address.ns1.h2
</
name
>
<
value
>
h2:9000
</
value
>
</
property
>
<
property
>
<
name
>
dfs.namenode.http-address.ns1.h2
</
name
>
<
value
>
h2:50070
</
value
>
</
property
>
<
property
>
<
name
>
dfs.namenode.shared.edits.dir
</
name
>
<
value
>
qjournal://h1:8485;h2:8485;h3:8485/ns1
</
value
>
</
property
>
<
property
>
<
name
>
dfs.ha.automatic-failover.enabled.ns1
</
name
>
<
value
>
true
</
value
>
</
property
>
<
property
>
<
name
>
dfs.client.failover.proxy.provider.ns1
</
name
>
<
value
>
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
</
value
>
</
property
>
<
property
>
<
name
>
dfs.journalnode.edits.dir
</
name
>
<
value
>
/ROOT/server/data-hadoop/journaldata
</
value
>
</
property
>
<
property
>
<
name
>
dfs.ha.fencing.methods
</
name
>
<
value
>
sshfence
</
value
>
</
property
>
<
property
>
<
name
>
dfs.ha.fencing.ssh.private-key-files
</
name
>
<
value
>
/home/webmaster/.ssh/id_rsa
</
value
>
</
property
>
<
property
>
<
name
>
dfs.webhdfs.enabled
</
name
>
<
value
>
true
</
value
>
</
property
>
<
property
>
<
name
>
dfs.blocksize
</
name
>
<
value
>
134217728
</
value
>
</
property
>
<
property
>
<
name
>
dfs.namenode.handler.count
</
name
>
<
value
>
20
</
value
>
</
property
>
<
property
>
<
name
>
dfs.datanode.max.xcievers
</
name
>
<
value
>
2048
</
value
>
</
property
>
</
configuration
>
yarn-site.xml里面:
Xml代码
<?
xml
version
=
"1.0"
?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--
>
<
configuration
>
<!--启用RM高可用-->
<
property
>
<
name
>
yarn.resourcemanager.ha.enabled
</
name
>
<
value
>
true
</
value
>
</
property
>
<!--RM集群标识符-->
<
property
>
<
name
>
yarn.resourcemanager.cluster-id
</
name
>
<
value
>
ns1
</
value
>
</
property
>
<
property
>
<!--指定两台RM主机名标识符-->
<
name
>
yarn.resourcemanager.ha.rm-ids
</
name
>
<
value
>
h1,h2
</
value
>
</
property
>
<!--RM故障自动切换-->
<
property
>
<
name
>
yarn.resourcemanager.ha.automatic-failover.recover.enabled
</
name
>
<
value
>
true
</
value
>
</
property
>
<!--RM故障自动恢复-->
<
property
>
<
name
>
yarn.resourcemanager.recovery.enabled
</
name
>
<
value
>
true
</
value
>
</
property
>
<!--RM主机1-->
<
property
>
<
name
>
yarn.resourcemanager.hostname.h1
</
name
>
<
value
>
h1
</
value
>
</
property
>
<!--RM主机2-->
<
property
>
<
name
>
yarn.resourcemanager.hostname.h2
</
name
>
<
value
>
h2
</
value
>
</
property
>
<!--RM状态信息存储方式,一种基于内存(MemStore),另一种基于ZK(ZKStore)-->
<
property
>
<
name
>
yarn.resourcemanager.store.class
</
name
>
<
value
>
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
</
value
>
</
property
>
<!--使用ZK集群保存状态信息-->
<
property
>
<
name
>
yarn.resourcemanager.zk-address
</
name
>
<
value
>
h1:2181,h2:2181,h3:2181
</
value
>
</
property
>
<!--向RM调度资源地址-->
<
property
>
<
name
>
yarn.resourcemanager.scheduler.address.h1
</
name
>
<
value
>
h1:8030
</
value
>
</
property
>
<
property
>
<
name
>
yarn.resourcemanager.scheduler.address.h2
</
name
>
<
value
>
h2:8030
</
value
>
</
property
>
<!--NodeManager通过该地址交换信息-->
<
property
>
<
name
>
yarn.resourcemanager.resource-tracker.address.h1
</
name
>
<
value
>
h1:8031
</
value
>
</
property
>
<
property
>
<
name
>
yarn.resourcemanager.resource-tracker.address.h2
</
name
>
<
value
>
h2:8031
</
value
>
</
property
>
<!--客户端通过该地址向RM提交对应用程序操作-->
<
property
>
<
name
>
yarn.resourcemanager.address.h1
</
name
>
<
value
>
h1:8032
</
value
>
</
property
>
<
property
>
<
name
>
yarn.resourcemanager.address.h2
</
name
>
<
value
>
h2:8032
</
value
>
</
property
>
<!--管理员通过该地址向RM发送管理命令-->
<
property
>
<
name
>
yarn.resourcemanager.admin.address.h1
</
name
>
<
value
>
h1:8033
</
value
>
</
property
>
<
property
>
<
name
>
yarn.resourcemanager.admin.address.h2
</
name
>
<
value
>
h2:8033
</
value
>
</
property
>
<!--RM HTTP访问地址,查看集群信息-->
<
property
>
<
name
>
yarn.resourcemanager.webapp.address.h1
</
name
>
<
value
>
h1:8088
</
value
>
</
property
>
<
property
>
<
name
>
yarn.resourcemanager.webapp.address.h2
</
name
>
<
value
>
h2:8088
</
value
>
</
property
>
<
property
>
<
name
>
yarn.resourcemanager.scheduler.class
</
name
>
<
value
>
org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
</
value
>
</
property
>
<
property
>
<
name
>
yarn.nodemanager.aux-services
</
name
>
<
value
>
mapreduce_shuffle
</
value
>
</
property
>
<
property
>
<
name
>
yarn.nodemanager.aux-services.mapreduce.shuffle.class
</
name
>
<
value
>
org.apache.hadoop.mapred.ShuffleHandler
</
value
>
</
property
>
<
property
>
<
description
>
Classpath for typical applications.
</
description
>
<
name
>
yarn.application.classpath
</
name
>
<
value
>
$HADOOP_CONF_DIR
,$HADOOP_COMMON_HOME/share/hadoop/common/*
,$HADOOP_COMMON_HOME/share/hadoop/common/lib/*
,$HADOOP_HDFS_HOME/share/hadoop/hdfs/*
,$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*
,$YARN_HOME/share/hadoop/yarn/*
</
value
>
</
property
>
<!-- Configurations for NodeManager -->
<
property
>
<
name
>
yarn.nodemanager.resource.memory-mb
</
name
>
<
value
>
5632
</
value
>
</
property
>
<
property
>
<
name
>
yarn.scheduler.minimum-allocation-mb
</
name
>
<
value
>
1408
</
value
>
</
property
>
<
property
>
<
name
>
yarn.scheduler.maximum-allocation-mb
</
name
>
<
value
>
5632
</
value
>
</
property
>
</
configuration
>
mapred-site.xml里面内容
Xml代码
<?
xml
version
=
"1.0"
?>
<?
xml-stylesheet
type
=
"text/xsl"
href
=
"configuration.xsl"
?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--
>
<!-- Put site-specific property overrides in this file. -->
<
configuration
>
<
property
>
<
name
>
mapreduce.framework.name
</
name
>
<
value
>
yarn
</
value
>
</
property
>
<
property
>
<
name
>
mapreduce.jobtracker.address
</
name
>
<
value
>
h1:8021
</
value
>
</
property
>
<
property
>
<
name
>
mapreduce.jobhistory.address
</
name
>
<
value
>
h1:10020
</
value
>
</
property
>
<
property
>
<
name
>
mapreduce.jobhistory.webapp.address
</
name
>
<
value
>
h1:19888
</
value
>
</
property
>
<
property
>
<
name
>
mapred.max.maps.per.node
</
name
>
<
value
>
2
</
value
>
</
property
>
<
property
>
<
name
>
mapred.max.reduces.per.node
</
name
>
<
value
>
1
</
value
>
</
property
>
<
property
>
<
name
>
mapreduce.map.memory.mb
</
name
>
<
value
>
1408
</
value
>
</
property
>
<
property
>
<
name
>
mapreduce.map.java.opts
</
name
>
<
value
>
-Xmx1126M
</
value
>
</
property
>
<
property
>
<
name
>
mapreduce.reduce.memory.mb
</
name
>
<
value
>
2816
</
value
>
</
property
>
<
property
>
<
name
>
mapreduce.reduce.java.opts
</
name
>
<
value
>
-Xmx2252M
</
value
>
</
property
>
<
property
>
<
name
>
mapreduce.task.io.sort.mb
</
name
>
<
value
>
512
</
value
>
</
property
>
<
property
>
<
name
>
mapreduce.task.io.sort.factor
</
name
>
<
value
>
100
</
value
>
</
property
>
</
configuration
>
启动方式:假设你是新的集群,如果不是,请参考文末的官网url链接
1,先在集群中启动N/2+1个JornalNode进程,写ssh脚本执行命令:hadoop-daemon.sh start journalnode
2 ,然后在第一台NameNode上应执行hdfs namenode -format格式化集群
3,然后在第二台NameNode上执行hdfs namenode -bootstrapStandby同步第一台NameNode元数据
4,在第一台NameNode上执行命令hdfs zkfc -formatZK格式化zookeeper
5,第一台NameNode上启动zkfc执行命令:hadoop-daemon.sh start zkfc
6,在第二台NameNode上启动zkfc执行命令:hadoop-daemon.sh start zkfc
7,执行start-dfs.sh启动所有的NameNode,DataNode,JournalNode(注意如果已经启动就会跳过)
8,执分别访问两台机器的50070端口,查看NameNode状态,其中一个为Active,一个为Standby即为正常
9,测试容错,找到状态为Active的NameNode的pid进程,并kill掉,查看standby是否会自动晋级为active,如果
一切安装完毕,则会自动切换,如果没切换,注意查看zkfc和namenode的log
感谢并参考的文章:
http://hadoop.apache.org/docs/r2.7.1/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
http://lizhenliang.blog.51cto.com/7876557/1661354
http://www.cnblogs.com/781811964-Fighter/p/4930067.html
Hadoop2.7.1配置NameNode+ResourceManager高可用原理分析
标签:
原文地址:http://my.oschina.net/u/1027043/blog/529087
踩
(
0
)
赞
(
0
)
举报
评论
一句话评论(
0
)
登录后才能评论!
分享档案
更多>
2021年07月29日 (22)
2021年07月28日 (40)
2021年07月27日 (32)
2021年07月26日 (79)
2021年07月23日 (29)
2021年07月22日 (30)
2021年07月21日 (42)
2021年07月20日 (16)
2021年07月19日 (90)
2021年07月16日 (35)
周排行
更多
分布式事务
2021-07-29
OpenStack云平台命令行登录账户
2021-07-29
getLastRowNum()与getLastCellNum()/getPhysicalNumberOfRows()与getPhysicalNumberOfCells()
2021-07-29
【K8s概念】CSI 卷克隆
2021-07-29
vue3.0使用ant-design-vue进行按需加载原来这么简单
2021-07-29
stack栈
2021-07-29
抽奖动画 - 大转盘抽奖
2021-07-29
PPT写作技巧
2021-07-29
003-核心技术-IO模型-NIO-基于NIO群聊示例
2021-07-29
Bootstrap组件2
2021-07-29
友情链接
兰亭集智
国之画
百度统计
站长统计
阿里云
chrome插件
新版天听网
关于我们
-
联系我们
-
留言反馈
© 2014
mamicode.com
版权所有 联系我们:gaon5@hotmail.com
迷上了代码!