标签:
一、基础功能简介
本团队的爬虫能够从网上搜索相关内容, 并归类,把所爬到的网页或各种类型的文档下载到本地上。

上届团队Beta版本爬虫的主要功能如下:
a)可爬取网页,问答页并进行问答文件分类。
b)设计了一个较为完善的UI界面,可显示爬取的进度:
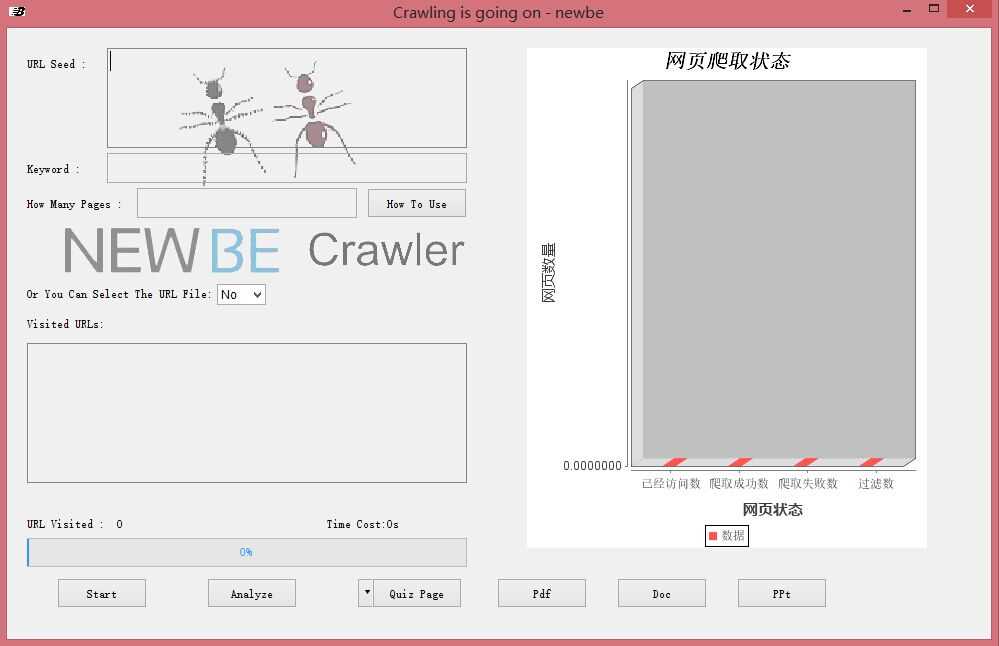
c) 声称能够专门爬取pdf,ppt,doc等文档。
d) 能够对爬取的结果进行分析。
二、更新内容
1.新增功能
1.1 新添了用户自定义关键词的分类功能:
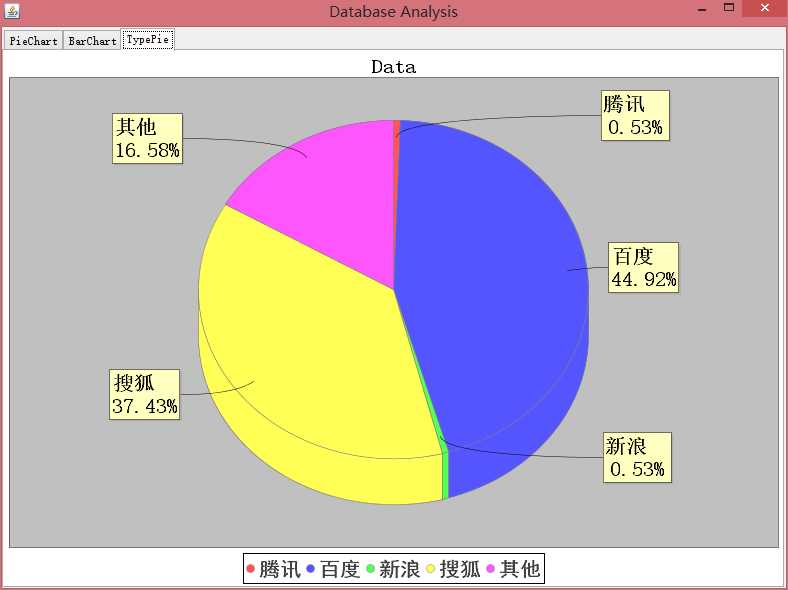
其中腾讯、百度等分类关键词皆由用户自定义设置。
1.2 真正实现了pdf,ppt,doc等文档文件的专门爬取:
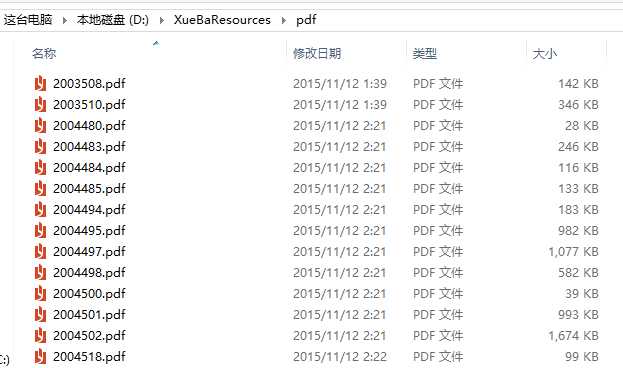
以爬取pdf为例。上届团队的pdf爬取仅仅是对种子网页的pdf进行爬取,其实就是单纯的单次扫描种子页面,没有真正体现爬虫的功能。我们对此进行了极大的升级,专门爬取pdf功能和网页爬取类似,能够进行多级链接的深层pdf爬取,存在专门的pdf文件夹中。升级后的功能爬取效率更高,数目更大。
1.3 UI界面的升级:
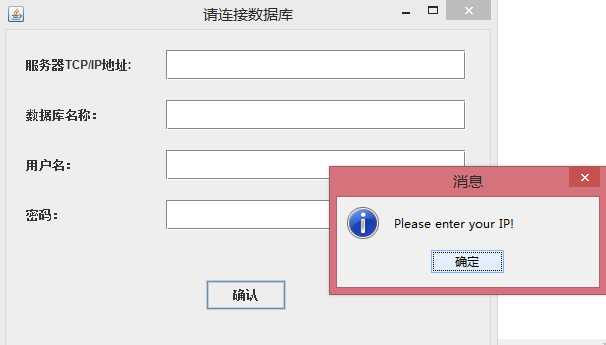
a) 考虑到我们的爬虫需要能够同时为多个用户服务,我们为爬虫设置了一个连接到数据库的验证界面。这样我们通过不同服务器的验证方式就可以连接上不同的数据库,而不是仅为单一服务器进行爬取了。如果没输入验证就点击确认,就会出现如下情况:
b) 考虑到界面的简洁与使用性,我们把爬取进度显示表和基础设置分开。在没有开始爬取时仅显示基础设置界面,开始爬取后自动显示爬取进度界面。除此以外,我们还对界面的按钮进行了重新排版,使之更符合大多数人的使用习惯。
1.4搭建了一个全新的数据库,对数据库的相关操作进行了优化,提高爬取效率。
2.bug修复
2.1 修复了一个多线程Bug,该Bug会导致爬取的网页数超出用户所要求的网页数。
解决前:
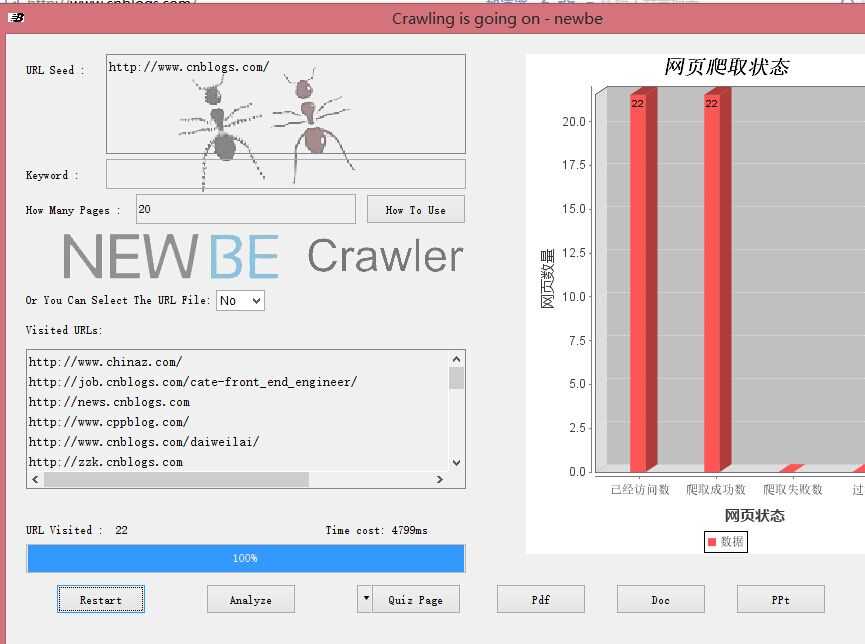
解决后:
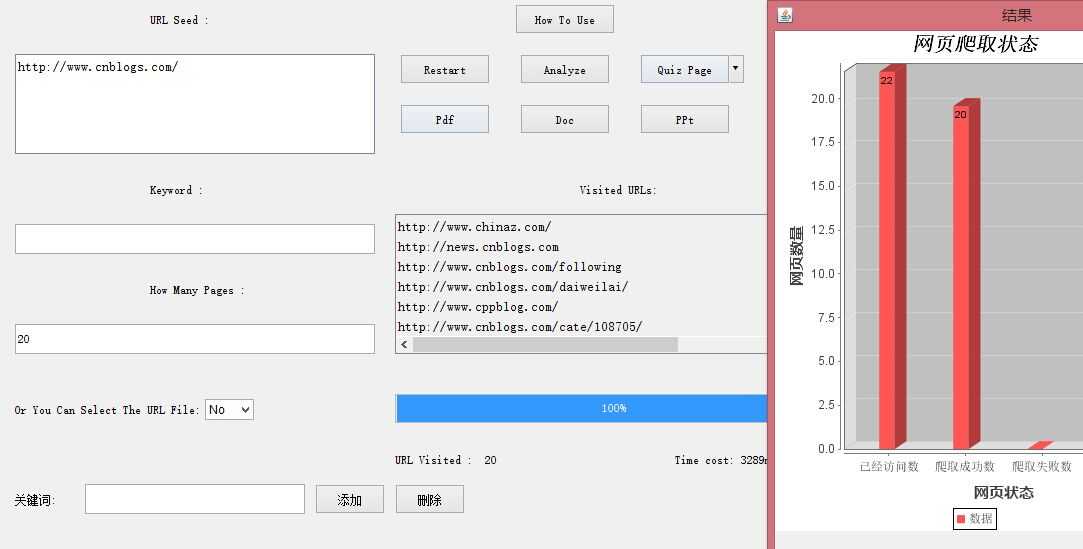
2.2 修复了一个Bug,该Bug会导致只要网址中出现pdf字符串就判断当前页为pdf类型。
2.3 修复了一个Bug,该Bug会导致文档专门性爬取无法开始。
2.4 修复了一个Bug,该Bug会导致用户选择通用爬取时爬虫只识别html和pdf型文件。
3.相关优化
3.1 优化了对数据库数据的统计操作,使得Analyze响应时间更快。
3.2 优化了进行爬取时对进度显示以及对数据库操作的方法,使得单位时间爬取的网页数目更多(详情见测试报告)。
3.3 优化了爬取方式,把网页、pdf、ppt等各文档文件的爬取和下载功能充分联系到一起,提高了爬取效率。同时删减了相应的代码文件,减少了代码量。
三、环境要求
| 操作系统要求 | windows XP、windows 7、windows 8 |
| 运行环境要求 | 最新版本的JRE |
| 数据库要求 | Sql Server 2008及以上 |
四、安装方法
把jar可执行文件复制到本地即可。
五、已知的缺陷与限制
以下缺陷和限制将在Beta版本完善:
a)在运行过程中有时会出现线程异常。
b)尚不支持动态爬取。
c)界面的功能键会因不规范操作而导致卡死。
六、发布方式和发布地址
该版本爬虫部署在服务器10.2.26.60上,可自行拷贝试用。
标签:
原文地址:http://www.cnblogs.com/cnmxfd/p/4957854.html