标签:
A Convex Optimization Framework for Active Learning
Active learning is the problem of progressively selecting and annotating the most informative unlabeled samples, in order to obtain a high classification performance.
目前AL方法存在的问题有:
1.大部分AL算法在预训练分类器之前,都一次只选择一个样本;这就导致计算复杂且无法利用并行标注系统;
2.一次可以选择多个样本的算法,又可能存在着样本重叠覆盖的问题,或者是要求解非凸问题.
更重要的问题是,之前的AL算法是专门为特定的分类器而设计的,例如:SVM. 本文的算法可以用于任何分类器,应用范围更加广泛.
本文主要贡献:
本文在凸优化的基础上提出了一种AL框架,可以同时选择多个样本进行标注,可以和任何类型的分类器相结合,包括基于稀疏表示的分类器.利用分类器的不确定性和样本的多样性来引导选择最具有信息性的无标签数据,并且有最小的信息重叠.
文章的主要框架:
2. Dissimilarity-based Sparse Modeling Representative Selection (DSMRS)
3. Active Learning via Convex Programming
we use the two principles of classifier uncertainty and sample diversity to define confidence scores for unlabeled samples.
3.1. Classifier Uncertainty (分类器的不确定性)
Now, for a generic classifier, we define its confidence about the predicted label of an unlabeled sample. Consider data in L different classes. For an unlabeled sample i,
we consider the probability vector p i = p i1 · · · p iL , where p ij denotes the probability that sample i belongs to class j. We define the classifier confidence score of point i
as:
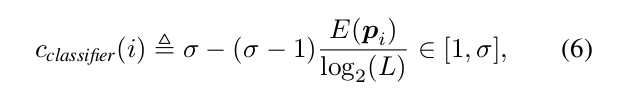
其中delta>1,E(.)代表熵函数(Entropy function).
对于置信度较高的样本,分类器置信度得分最低,即为1;
对于置信度较低的样本,分类器置信度得分最高,为delta.
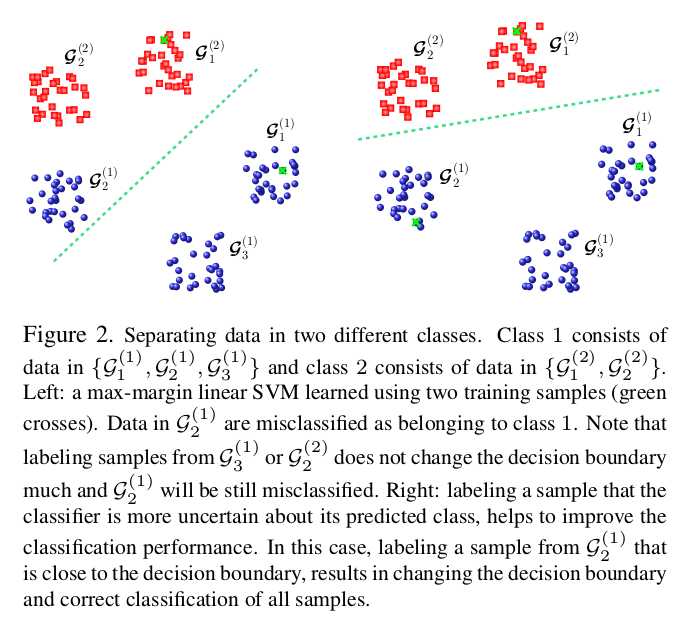
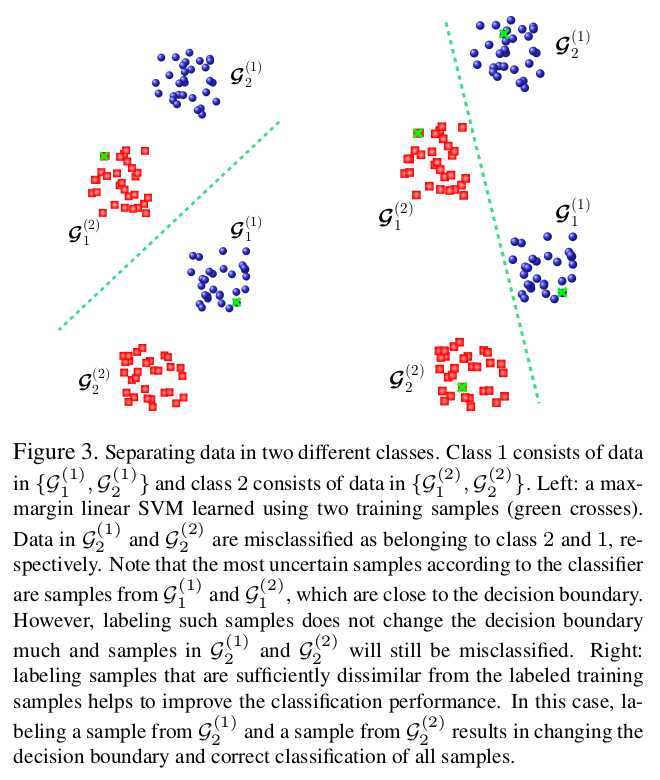
该图片说明了选择低置信度样本的必要性和有效性.绿色的x表示标注的数据.
3.2. Sample Diversity 样本的多样性;
More specifically, sample diversity states that informative points for classification are the ones that are sufficiently dissimilar from the labeled training samples (and
from themselves in the batch mode setting).
该图说明了标注样本多样性的优势.
从左图可以看出,只标注离分界面最近的样本,仍然无法正确进行分类,但是选择那些跟训练样本不同的sample进行标注,则可以得到较好的分类效果.
论文阅读之 A Convex Optimization Framework for Active Learning
标签:
原文地址:http://www.cnblogs.com/wangxiaocvpr/p/4958368.html