标签:
系列文章:《机器学习实战》学习笔记
决策树
我们经常使用决策树处理分类问题,它的过程类似二十个问题的游戏:参与游戏的一方在脑海里想某个事物,其他参与者向他提出问题,只允许提20个问题,问题的答案也只能用对或错回答。问问题的人通过推断分解,逐步缩小带猜测事物的范围。如图1所示的流程图就是一个决策树,长方形代表判断模块(decision block),椭圆形代表终止模块(terminating block),表示已经得出结论,可以终止运行。从判断模块引出的左右箭头称作分支(branch),它可以到达另一个判断模块或终止模块。图1构造了一个假象的邮件分类系统,它首先检测发送邮件域名地址。如果地址为myEmployer.com,则将其放在分类"无聊时需要阅读的邮件"中。如果邮件不是来自这个域名,则检查内容是否包括单词曲棍球,如果包含则将邮件归类到"需要及时处理的朋友邮件",否则将邮件归类到"无须阅读的垃圾邮件"。
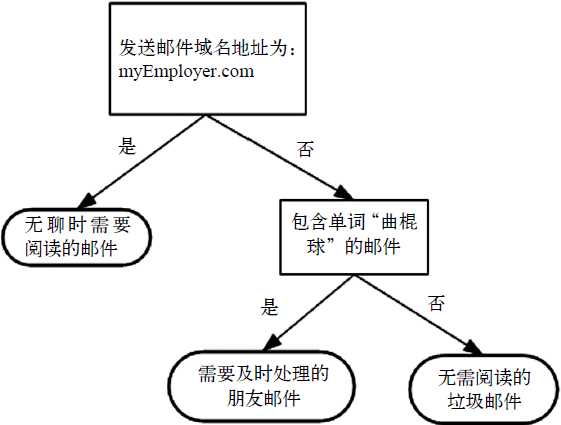
图1 流程图形式的决策树
第2章介绍的k-近邻算法可以完成很多分类任务,但是它最大的缺点就是无法给出数据的内在含义,决策树的主要优势就在于数据形式非常容易理解。
本章构造的决策树算法能够读取数据集合,构建类似图1的决策树。决策树可以在数据集合中提取出一系列规则,规则创建的过程就是机器学习的过程。现在我们已经大致了解决策树可以完成哪些任务,接下来我们将学习如何从一堆原始数据中构造决策树。首先我们讨论构造决策树的方法,以及如何编写构造树的Python代码;接着提出一些度量算法成功率的方法;最后使用递归建立分类器,并且使用Matplotlib绘制决策树图。
在构造决策树时,我们需要解决的第一个问题就是,当前数据集上哪个特征在划分数据分类时起决定性作用。为了找到决定性的特征,划分出最好的结果,我们必须评估每个特征。我们假设已经根据一定的方法选取了待划分的特征,则原始数据集将根据这个特征被划分为几个数据子集。这数据子集会分布在决策点(关键特征)的所有分支上。如果某个分支下的数据属于同一类型,则无需进一步对数据集进行分割。如果数据子集内的数据不属于同一类型,则需要递归地重复划分数据子集的过程,直到每个数据子集内的数据类型相同。
创建分支的过程用伪代码表示如下:
检测数据集中的每个子项是否属于同一类型:
如果是,则返回类型标签
否则:
寻找划分数据集的最好特征
划分数据集
创建分支节点
对划分的每个数据子集:
递归调用本算法并添加返回结果到分支节点中
返回分支节点
标签:
原文地址:http://www.cnblogs.com/qwertWZ/p/4960755.html