标签:
一、 数据挖掘的流程
1.明确你的目标,收集相关数据。
2.根据目标分析这些数据,找出输入列、可预测列。
3.选择合适的数据挖掘方法。
4.分析数据挖掘结果,给出建议。
二、常见的数据挖掘方法
有分类、聚类、关联、回归、时间序列分析、离散序列分成、偏差分析、贝叶斯、神经网络等等。
1. 数据挖掘算法之分类
例:某银行每天收到很多信用卡办理的申请,为提高效率和准确性,想应用数据挖掘技术来改善工作,你会怎样考虑呢?
该银行有大量的历史数据,将申请者分为高、中、低三种风险类型,这样输入列就是申请者的学历、收入、职业等信息,而可预测列就是风险类型。这样对历史数据进行数据挖掘后,当有新的申请者提交资料,系统就可以判断该申请者风险类型为高、中还是低了。
以上的算法就是“分类”,该挖掘方法需人工指定类别,然后找出一组属性与该类别的关系,利用这些关系来预测新的情况。
2. 数据挖掘算法之聚类
“聚类”与“分类”很相似,同样是找出一组属性与类别的关系,不同的是这类别不是事先指定的,而是由数据挖掘自己找出分类。
例:某公司收集了很多客户的资料,记录了客户的年龄和收入。该公司相对这些数据进行分析,找出可以重点营销的客户对象。我们可指定输入列为年龄和收入,经过聚类数据挖掘后,发现客户群可以划分为三个群体:低收入年轻客户、高收入中年客户、收入相对低的年老客户。根据这样的分析结果,公司可采取决策,重点针对高收入中年客户进行营销活动。
3. 数据挖掘算法之关联
例:在一家超市里,有一个有趣的现象:尿布和啤酒赫然摆在一起出售。但是这个奇怪的举措却使尿布和啤酒的销量双双增加了。这不是一个笑话,而是发生在美国沃尔玛连锁店超市的真实案例,并一直为商家所津津乐道。原来,美国的妇女们经常会嘱咐她们的丈夫下班以后要为孩子买尿布。而丈夫在买完尿布之后又要顺手买回自己爱喝的啤酒,因此啤酒和尿布在一起购买的机会还是很多的。
上述这个例子经常会被人拿来说,但很少人会举一反三地应用这个例子。我们有很多超市记录了大量的交易数据,只要对这些交易数据做一下关联分析,就很可能会得到不少价值巨大的商业机会。上述这个“尿布+啤酒”的例子,就是应用了关联分析,发现尿布和啤酒两个东西经常被一起卖掉。关联分析主要用来找出某些东西“摆在一起“的机会。我们上网上商城购买东西,你每选择一个商品,就可能会向你推销一堆别的商品,这很可能就是关联分析在“作怪”。
4. 数据挖掘算法之回归
变量X、Y可能存在关系,我们可以将大量的(X、Y)绘制到一张图上,形成一张散点图。如果这些散点更好都在一条直线附近,那么这条直线的方程就可以近似代表X与Y的关系。
所谓的回归,就是要找到一个函数代表变量X1,X2,X3,...与Y的关系,该函数所绘制出来的曲线,能尽量拟合这些“散点”。
5. 数据挖掘算法之时间序列分析
例1:炒股的人都想预测明天是涨还是跌,实际上我们已经积累了大量的历史数据,说不定还是可以预测的!某股票已经连续涨了3天,明天会不会再涨呢?某股票连续跌了7天了,明天应该不会再跌了吧?
例2:很多商家会在某些节假日时,重点销售某些产品,以求可以卖出更多,圣诞节快到了,应该主推什么产品好呢?实际上各商家的收款系统中,记录了大量的与时间相关的销售数据,如果对这些数据做一下时间序列分析,说不定能找到重大商机。
时间序列分析,输入列都是与时间相关的数据,同时需要考虑季节、历史等因素,这样就可以预测某个时间会怎样了。
6. 数据挖掘算法之离散序列分析
某网站对访问者的操作进行了统计,如下:
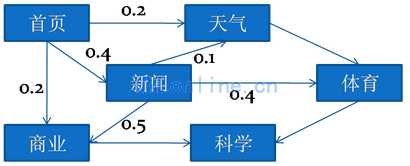
说明:
1.访问者进入首页后,有20%会进入天气页面,40%进入新闻页面,20%进入商业页面。
2.从首页进入新闻页面的机会是40%,而从天气进入新闻的机会是10%。
以上的分析对于优化网站是很有帮助的,上述的分析用到了离散序列分析技术。
离散序列分析,输入列是一系列有“次序”的数据,通过这一系列有次序的数据预测另外一个数据情况。
7. 数据挖掘算法之偏差分析
例1:某银行有信用卡异常使用情况的监控系统,如果发现某些用卡行为与客户往常习惯不一样时,会发出警告。
例2:软件项目管理如果达到CMMI4级或以上的层次,就会使用基线来管理项目,基线上下限范围内可认为是“正常”的,如果超出上下限,则认为是“偏差”,需要分析原因并采取措施。
信用卡每次使用情况,包括时间、地点、金额、商户等信息都会记录下来。利用正常的历史数据对系统进行训练,告诉系统这些是“正常”的使用情况,当出现新的用卡记录与这些正常使用的特征不符时,则可以发出警告。偏差分析的原理就是用正常的数据去训练系统,由系统去判断新数据是否在正常范围?有没有偏差?
8. 数据挖掘算法之贝叶斯
贝叶斯算法是一种根据历史事件发生的概率来推测将来的算法,由伟大的数学家Thomas Bayes所创建的。Thomas Bayes,1702年出生于英国伦敦。
该算法的原理是这样的:如果事情A、事情B、事情C、...、这些事情发生了,那么事情X发生的几率是多少。前面这些事情叫做前提事情,可以是一个到多个,前提事情越多分析起来就越复杂但会更加准确。
举个例子:据说麦当劳当年发现,如果顾客购买了汉堡包和薯条,那么顾客再购买可乐的机会是70%,于是麦当劳就将这三个产品捆绑在一起作为套餐,于是销量大增。对于这个案例,前提事件就是购买汉堡包和购买薯条,要预测的是顾客会不会买可乐,预测结果就是有70%机会会买。我们可以利用贝叶斯原理来进行数据挖掘。
9. 数据挖掘算法之神经网络
人脑其实是由数量庞大的神经细胞组成的,神经细胞庞大的数量及复杂的结构,让人类充满了智慧。人一出世,脑袋是一片空白的,当我们学会了某样东西的时候,我们会对起进行推演和归纳。比方说我们认识了这是一条狗,当我们见到另外一条不同品种狗的时候,我们会判断这也是一条狗。而计算机的判断一般来说就比较死板了,如果有细微的偏差就会认不出来。
神经网络算法其实就是通过计算机来构造类似于人脑的神经细胞网络,通过一些训练,能让该网络能识别某一类事物。文字识别、指纹识别等都是应用了神经网络技术的。
通过数据训练,我们可以在输入列与可预测列之间找到合适的神经网络,然后通过这个网络对新情况进行判断。
三、 数据挖掘技术
数学方面的知识只要是概率与统计方面的知识,回归、时序、决策树、贝叶斯等数据挖掘算法都是依赖于这些数学知识的。
电脑的发展让机器学习发挥出无穷的威力,神经网络、遗传算法是两种倚赖于计算机学习的算法。
数据仓库、数据集市、数据立方体的存储技术等数据库技术的发展,让数据挖掘可以处理越来越大量的数据。
标签:
原文地址:http://www.cnblogs.com/sweetyu/p/4961642.html