标签:
论文的链接:http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Shao_Deeply_Learned_Attributes_2015_CVPR_paper.pdf
这篇文章是通过 Attribute对Crowd Scene的Video进行理解, 并利用CNN学习描述属性的特征。
1. 构建一个新的大规模WWW Crowd的数据集(8257个场景,10000个视频), 并定于了94种属性
2. 构建CNN模型学习Deep Features
属性主要是基于三个方面: Where, Who, Why

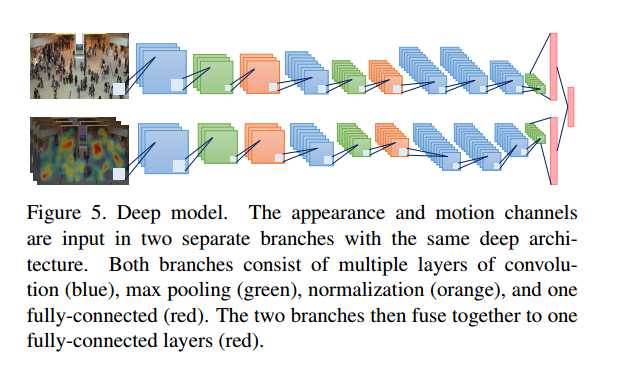
Motion是 根据2014-CVPR-Scene-independent group profiling in crowd这篇论文计算得到。
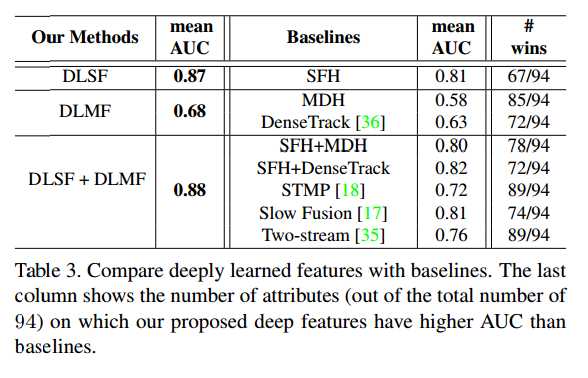
从结果中大概可以得到Appearance的准确率比Motion要高,两者结合其实影响不大。
2015-CVPR-Deeply Learned Attributes for Crowed Scene Understanding
标签:
原文地址:http://www.cnblogs.com/ZhimingLuo/p/4963715.html