标签:
1 过拟合
过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上。出现over-fitting的原因是多方面的:
1 训练数据过少,数据量与数据噪声是成反比的,少量数据导致噪声很大
2 特征数目过多导致模型过于复杂,如下面的图所示:
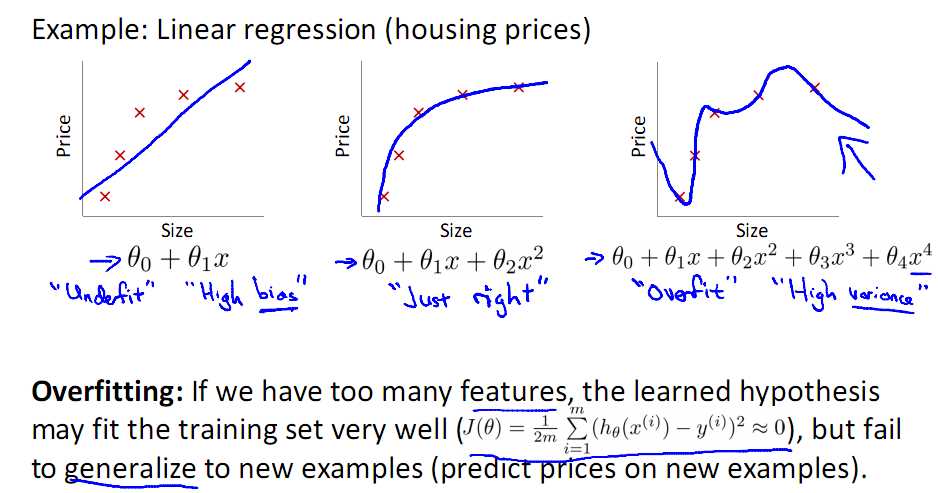
看上图中的多项式回归(Polynomial regression),左边为模型复杂度很低,右边的模型复杂度就过高,而中间的模型为比较合适的模型,对于Logistic有同样的情况
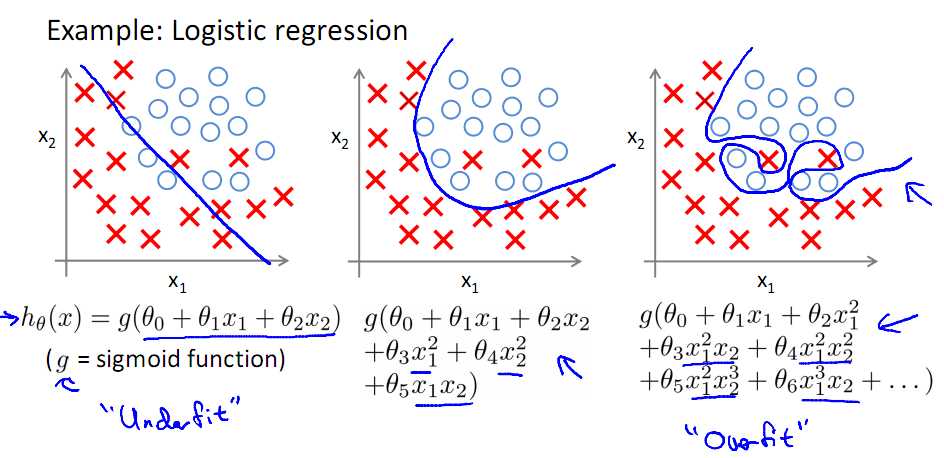
如何避免过拟合
1. 控制特征的数目,可以通过特征组合,或者模型选择算法
2.Regularization,保持所有特征,但是减小每个特征的参数向量θ的大小,使其对分类y所做的共享很小

下面来详细分析正则化
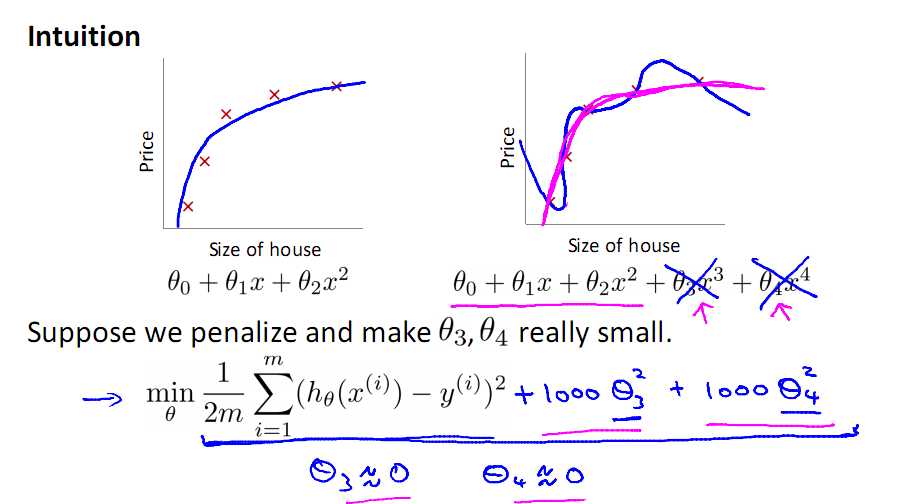
来看多项式拟合的问题,对于右图复杂的模型,只需控制θ3与θ4的大小,即可使得模型达到与作图类似的结果,下面引入线性回归的L2正则的公式

如上过程就是正则化的过程,注意正则化是不带θ0的,其实带不带在实际运用中只会有很小的差异,所以不必在意,现在只需要控制λ的大小,当λ很大时,θ1到θn就会很小,即达到了约束数量庞大的特征的目的。
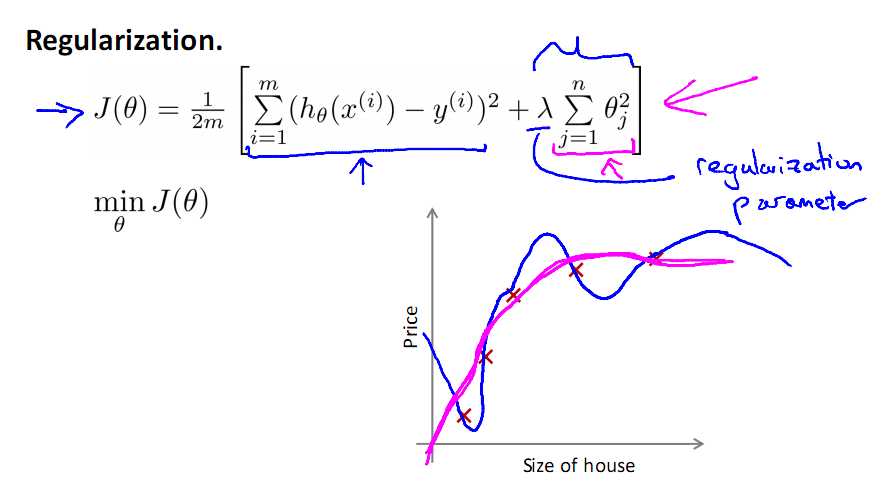
若选择过大的λ,会使得参数向量θ非常小,从而只剩下θ0,使得模型看起来像一条直线

而且,模型会欠拟合,梯度下降也不会收敛,而λ的选择将在特征选择中讲到

带有正则化项的梯度下降算法,首先要特殊处理θ0,

关于Normal Equation 的正则化

并且有一个不错的消息就是括号中的矩阵必定为可逆的
Logistic的正则化
首先看L2正则
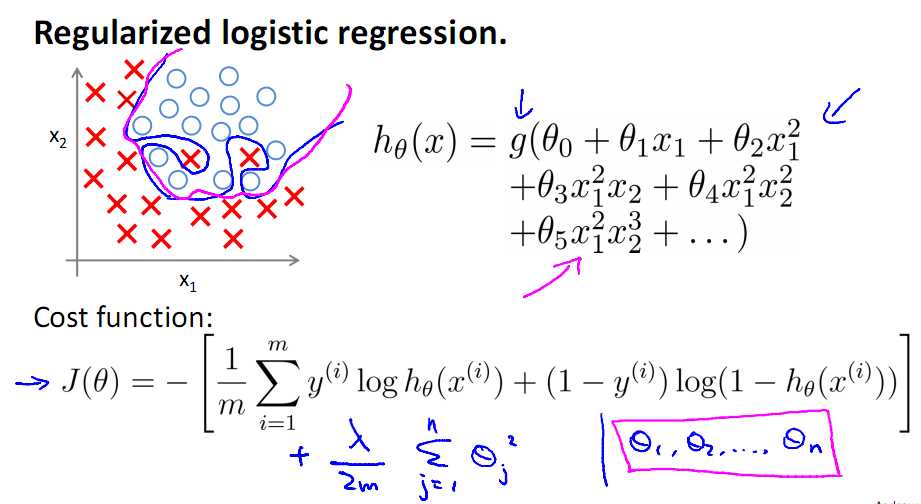
其正则化的Gradient Descent形式:

标签:
原文地址:http://www.cnblogs.com/ooon/p/4964441.html