标签:
阅读目录:
接上篇,离线计算是对已经入库的数据进行计算,在查询时对批量数据进行检索、磁盘读取展示。 而实时计算是在数据产生时就对其进行计算,然后实时展示结果,一般是秒级。 举个例子来说,如果有个大型网站,要实时统计用户的搜索内容,这样就能计算出热点新闻及突发事件了。 按照以前离线计算的做法是不能满足的,需要使用到实时计算。
小明作为有理想、有追求的程序员开始设计其解决方案了,主要分三部分。
其流程图如下:
通常都介绍Storm是一个分布式的、高容错的实时计算系统。 “分布式”是把数据分布到多台上进行计算,“高容错”下面谈,这里主要细节介绍下“实时计算”的实现。
storm有个角色叫topology,它类似mapreduce的job,是一个完整的业务计算任务抽象。 上章谈到hadoop的缺点在于数据源单一依赖HDFS,storm中Spout角色的出现解决了这个问题。 在Spout内部我们可以读取任意数据源的数据,比如Redis、消息队列、数据库等等。 而且spout可以是多个,这样更好的分类,比如可以SpoutA读取kafka,SpoutB读取Redis。 示例如下:
public class CalcPriceSpout : BaseRichSpout { private SpoutCollector Collector; public override void NexData() { //读取各种数据源,Redis、消息队列、数据库等 Collector.emit("消息") } }
代码中NexData是storm的核心方法,它一直被storm循环调用着, 在方法里我们实时读取kafka的消息,然后把消息通过Collector组件发射到各个计算节点里,它类似小和尚中的Master。 这样应用每产生一条数据,会实时收集到kafka,然后被NextData消费,发射到节点开始计算。 NextData读取的消息时在内存中,然后直接通过网络流动到节点机器上的内存中开始计算,不会持久化到磁盘上。
因为速度比较快,所以叫实时计算,也有叫持续计算,意思是可以非常快的一直进行计算,至于叫什么都可以。
主流的流式计算有S4、StreamBase、Borealis,其storm也具有流式计算的特性。 流式计算是指“数据能像液体水一样不断的在各个节点间流动,每个节点都可以对“数据(液体水)”进行计算,然后产生新的数据,继续像水一样流动”。如图:
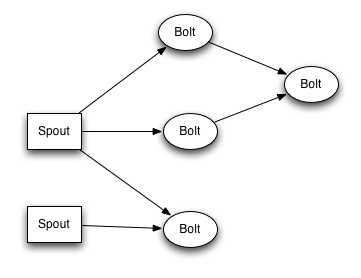
图中Spout就是水龙头,它不断的通过NextData产生数据,然后流动各个Bolt中。 Bolt是各个计算节点上的计算逻辑,它拿到数据后开始计算,完成后流向另外一个,直到完成。 其Bolt也可以是任意个,这比Mapreduce只能分成Map、Reduce两部分好多了。 这样可以在BlotA中计算中间值,然后通过这个中间值去任意数据源拉取数据后,在流动到下一步处理逻辑中, 这个中间值直接在内存中,通过网络流动BlotB上。 其大大增加了其适用范围和灵活度,Spout和bolt的数据流动构成了一个有向无环图。 Bolt示例代码如下。
public class CalcProductPriceBolt : BaseRichBolt { private BoltCollector Collector; public override void Execute(Tuple<string, string> input) { //Result=计算计算计算。 //Collector.Emit("Reulst"); 流动到另外一个节点 } }
数据流动图:
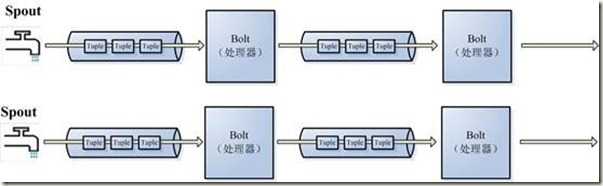
结合上篇,发现Hadoop离线计算的计算要求是把业务逻辑包上传到平台上,数据导入到HDFS上,这样才能进行计算。 其产生的结果数据是展示之前就计算好的,另外它的计算是按批次来的,比如很多公司的报表,都是每天凌晨开始计算前一天的数据,以便于展示。 其数据是不动的,计算逻辑也是不动的。
Storm的流式计算同样是把计算逻辑包上传到平台上,由平台调度,计算逻辑是不动的。 但数据可以是任意来源的,不断在计算节点进行流动。 也即是说在数据产生的时刻,就开始进行流动计算,它展示的结果数据是实时变化的。 其数据是流动的,计算逻辑是不动的。storm把产生的每条数据当成一个消息来处理,其内部也是通过消息队列组件zeromq来完成的。
storm提供了各级别的可靠性保证,一消息从Spout流动到boltA,在流动boltB, 那storm会通过唯一值不断异或的设计去监测这个消息的完成情况,这个监测是一个和业务逻辑类似的bolt,不过它是有storm自身实现的,叫Acker,它的任务就是接收各个消息任务的完成状态,然后告诉Spout这个消息是否已经完全处理。下面是几种异常处理情况:
下篇写消息保证机制及改造小和尚的设计。
标签:
原文地址:http://www.cnblogs.com/mushroom/p/4962788.html