标签:
===================
对网站资源进行优化,并使用不同浏览器测试并不是网站设计过程中最有意思的部分,但是这个过程中的很多重复的任务能够使用正确的工具自动完成,从而使效率大大提高,这是让很多开发者觉得有趣的地方。
Gulp是一个构建系统,它能通过自动执行常见任务,比如编译预处理CSS,压缩JavaScript和刷新浏览器,来改进网站开发的过程。通过本文,我们将知道如何使用Gulp来改变开发流程,从而使开发更加快速高效。
Gulp是一个构建系统,开发者可以使用它在网站开发过程中自动执行常见任务。Gulp是基于Node.js构建的,因此Gulp源文件和你用来定义任务的Gulp文件都被写进了JavaScript(或者CoffeeScript)里。前端开发工程师还可以用自己熟悉的语言来编写任务去lint JavaScript和CSS、解析模板以及在文件变动时编译LESS文件(当然这些只是一小部分例子)。
Gulp本身虽然不能完成很多任务,但它有大量插件可用,开发者可以访问插件页面或者在npm搜索gulpplugin就能看到。例如,有些插件可以用来执行JSHint、编译CoffeeScript,执行Mocha测试,甚至更新版本号。
对比其他构建工具,比如Grunt,以及最近流行的Broccoli,我相信Gulp会更胜一筹(请看后面的”Why Gulp?”部分),同时我汇总了一个使用Javascript编写的构建工具清单,可供大家参考。
Gulp是一个可以在GitHub上找到的开源项目。
安装Gulp的过程十分简单。首先,需要在全局安装Gulp包:
npm install -g gulp
然后,在项目里面安装Gulp:
npm install --save-dev gulp
现在我们创建一个Gulp任务来压缩JavaScript文件。首先创建一个名为gulpfile.js的文件,这是定义Gulp任务的地方,它可以通过gulp命令来运行,接着把下面的代码放到gulpfile.js文件里面。
var gulp = require(‘gulp‘), uglify = require(‘gulp-uglify‘); gulp.task(‘minify‘, function () { gulp.src(‘js/app.js‘) .pipe(uglify()) .pipe(gulp.dest(‘build‘)) });
然后在npm里面运行npm install -–save-dev gulp-uglify来安装gulp-uglify,最后通过运行gulp minify来执行任务。假设js目录下有个app.js文件,那么一个新的app.js将被创建在编译目录下,它包含了js/app.js的压缩内容。想一想,到底发生了什么?
我们只在gulpfile.js里做了一点事情。首先,我们加载gulp和gulp-uglify模块:
var gulp = require(‘gulp‘), uglify = require(‘gulp-uglify‘);
然后,我们定义了一个叫minify的任务,它执行时会调用函数,这个函数会作为第二个参数:
gulp.task(‘minify‘, function () { });
最后,也是难点所在,我们需要定义任务应该做什么:
gulp.src(‘js/app.js‘)
.pipe(uglify())
.pipe(gulp.dest(‘build‘))
如果你对数据流非常熟悉(其实大多数前端开发人员并不熟悉),上面所提供的代码对你来说就没有太大意义了。
数据流能够通过一系列的小函数来传递数据,这些函数会对数据进行修改,然后把修改后的数据传递给下一个函数。
在上面的例子中,gulp.src()函数用字符串匹配一个文件或者文件的编号(被称为“glob”),然后创建一个对象流来代表这些文件,接着传递给uglify()函数,它接受文件对象之后返回有新压缩源文件的文件对象,最后那些输出的文件被输入gulp.dest()函数,并保存下来。
整个数据流动过程如下图所示: 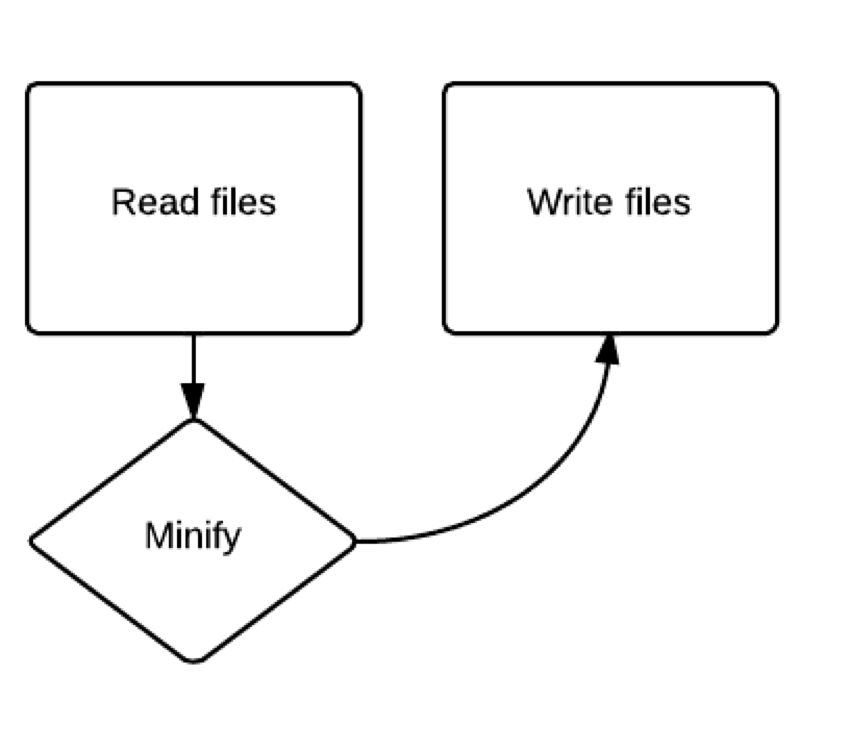
当只有一个任务的时候,函数并不会起太大的作用。然而,仔细思考下面的代码:
gulp.task(‘js‘, function () { return gulp.src(‘js/*.js‘) .pipe(jshint()) .pipe(jshint.reporter(‘default‘)) .pipe(uglify()) .pipe(concat(‘app.js‘)) .pipe(gulp.dest(‘build‘)); });
在运行这段程序之前,你需要先安装gulp,gulp-jshint,gulp-uglify和gulp-concat。
这个任务会让所有的文件匹配js/*.js(比如js目录下的所有JavaScript文件),并且执行JSHint,然后打印输出结果,取消文件缩进,最后把他们合并起来,保存为build/app.js,整个过程如下图所示: 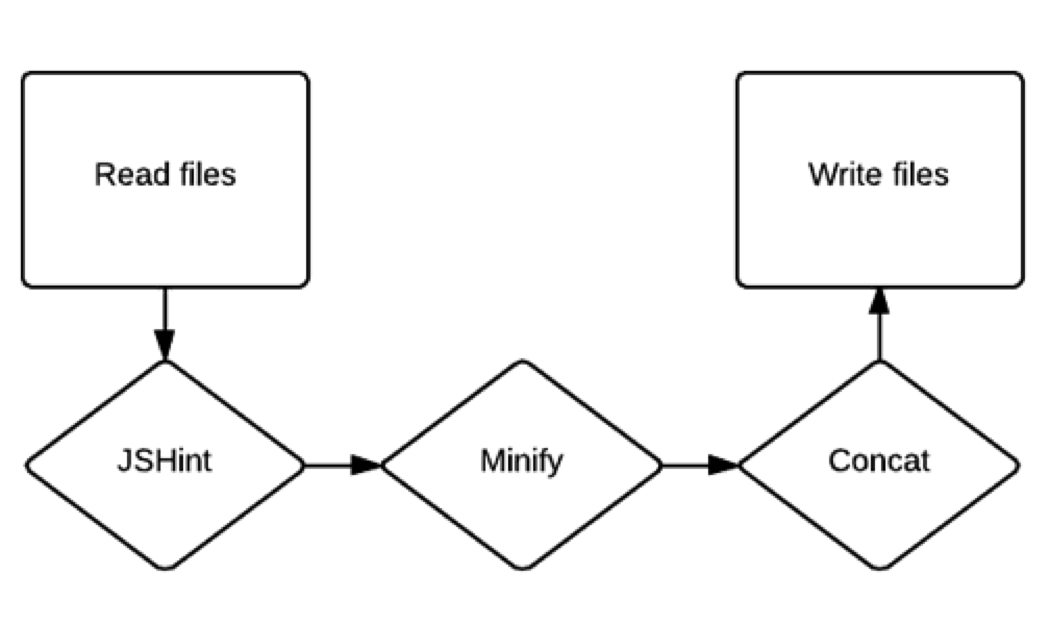
如果你对Grunt 足够熟悉,就会注意到,Gulp和Grunt的工作方式很不一样。Grunt不使用数据流,而是使用文件,对文件执行单个任务然后保存到新的文件中,每个任务都会重复执行所有进程,文件系统频繁的处理任务会导致Grunt的运行速度比Gulp慢。
如果想要获取更加全面的数据流知识,请查看“Stream Handbook”.
gulp.src()方法输入一个glob(比如匹配一个或多个文件的字符串)或者glob数组,然后返回一个可以传递给插件的数据流。
Gulp使用node-glob来从你指定的glob里面获取文件,这里列举下面的例子来阐述,方便大家理解:
此外,Gulp也有很多其他的特征,但并不常用。如果你想了解更多的特征,请查看Minimatch文档。
js目录下包含了压缩和未压缩的JavaScript文件,现在我们想要创建一个任务来压缩还没有被压缩的文件,我们需要先匹配目录下所有的JavaScript文件,然后排除后缀为.min.js的文件:
gulp.src([‘js/**/*.js‘, ‘!js/**/*.min.js‘])
gulp.task()函数通常会被用来定义任务。当你定义一个简单的任务时,需要传入任务名字和执行函数两个属性。
gulp.task(‘greet‘, function () { console.log(‘Hello world!‘); });
执行gulp greet的结果就是在控制台上打印出“Hello world”.
一个任务有时也可以是一系列任务。假设要定义一个任务build来执行css、js、imgs这三个任务,我们可以通过指定一个任务数组而不是函数来完成。
gulp.task(‘build‘, [‘css‘, ‘js‘, ‘imgs‘]);
这些任务不是同时进行的,所以你不能认为在js任务开始的时候css任务已经结束了,也可能还没有结束。为了确保一个任务在另一个任务执行前已经结束,可以将函数和任务数组结合起来指定其依赖关系。例如,定义一个css任务,在执行前需要检查greet任务是否已经执行完毕,这样做就是可行的:
gulp.task(‘css‘, [‘greet‘], function () { // Deal with CSS here });
现在,当执行css任务时,Gulp会先执行greet任务,然后在它结束后再调用你定义的函数。
你可以定义一个在gulp开始运行时候默认执行的任务,并将这个任务命名为“default”:
gulp.task(‘default‘, function () { // Your default task });
Gulp上有超过600种插件供你选择,你可以在插件页面或者npm上搜索gulpplugin来浏览插件列表。有些拥有“gulpfriendly”标签的插件,他们不能算插件,但是能在Gulp上正常运行。 需要注意的是,当直接在npm里搜索时,你无法知道某一插件是否在黑名单上(你需要滚动到插件页面底部才能看到)。
大多数插件的使用都很方便,它们都配有详细的文档,而且调用方法也相同(通过传递文件对象流给它),它们通常会对这些文件进行修改(但是有一些插件例外,比如validators),最后返回新的文件给下一个插件。
让我们用前面的js任务来详细说明一下:
var gulp = require(‘gulp‘), jshint = require(‘gulp-jshint‘), uglify = require(‘gulp-uglify‘), concat = require(‘gulp-concat‘); gulp.task(‘js‘, function () { return gulp.src(‘js/*.js‘) .pipe(jshint()) .pipe(jshint.reporter(‘default‘)) .pipe(uglify()) .pipe(concat(‘app.js‘)) .pipe(gulp.dest(‘build‘)); });
这里使用了三个插件,gulp-jshint,gulp-uglify和gulp-concat。开发者可以参考插件的README文档,插件有很多配置选项,而且给定的初始值通常能满足需求。细心的读者可能会发现,程序中JSHint插件执行了2次,这是因为第一次执行JSHint只是给文件对象附加了jshint属性,并没有输出。你可以自己读取jshint的属性或者传递给默认的JSHint的接收函数或者其他的接收函数,比如jshint-stylish.
其他两个插件的作用很清楚:uglify()函数压缩代码,concat(‘app.js’)函数将所有文件合并到一个叫app.js的文件中。
我发现gulp-load-plugin模块十分有用,它能够自动地从package.json中加载任意Gulp插件然后把它们附加到一个对象上。它的基本用法如下所示:
var gulpLoadPlugins = require(‘gulp-load-plugins‘), plugins = gulpLoadPlugins();
你可以把所有代码写到一行,但是我并不推荐这样做。
在执行那些代码之后,插件对象就已经包含了插件,并使用“驼峰式”的方式进行命名(例如,gulp-ruby-sass将被加载成plugins.rubySass),这样就可以很方便地使用了。例如,前面的js任务简化为如下:
var gulp = require(‘gulp‘), gulpLoadPlugins = require(‘gulp-load-plugins‘), plugins = gulpLoadPlugins(); gulp.task(‘js‘, function () { return gulp.src(‘js/*.js‘) .pipe(plugins.jshint()) .pipe(plugins.jshint.reporter(‘default‘)) .pipe(plugins.uglify()) .pipe(plugins.concat(‘app.js‘)) .pipe(gulp.dest(‘build‘)); });
假设package.json文件如下面所示:
{ "devDependencies": { "gulp-concat": "~2.2.0", "gulp-uglify": "~0.2.1", "gulp-jshint": "~1.5.1", "gulp": "~3.5.6" } }
这个例子虽然已经够短了,但是使用更长更复杂的Gulp文件会把它们简化成一两行代码。
三月初发布的Gulp-load-plugins0.4.0版本添加了延迟加载功能,提高了插件的性能,因为插件在使用的时候才会被加载进来,你不用担心package.json里未被使用的插件影响性能(但是你需要把他们清理掉)。换句话说,如果你在执行任务时只需要两个插件,那么其他不相关的插件就不会被加载。
Gulp可以监听文件的修改动态,然后在文件被改动的时候执行一个或多个任务。这个特性十分有用(对我来说,这可能是Gulp中最有用的一个功能)。你可以保存LESS文件,接着Gulp会自动把它转换为CSS文件并更新浏览器。
使用gulp.watch()方法可以监听文件,它接受一个glob或者glob数组(和gulp.src()一样)以及一个任务数组来执行回调。
让我们看看下面,build任务可以将模板转换成html格式,然后我们希望定义一个watch任务来监听模板文件的变化,并将这些模板转换成html格式。watch函数的使用方法如下所示:
gulp.task(‘watch‘, function () { gulp.watch(‘templates/*.tmpl.html‘, [‘build‘]); });
现在,当改变一个模板文件时,build任务会被执行并生成HTML文件,也可以给watch函数一个回调函数,而不是一个任务数组。在这个示例中,回调函数有一个包含触发回调函数信息的event对象:
gulp.watch(‘templates/*.tmpl.html‘, function (event) { console.log(‘Event type: ‘ + event.type); // added, changed, or deleted console.log(‘Event path: ‘ + event.path); // The path of the modified file });
Gulp.watch()的另一个非常好的特性是返回我们熟知的watcher。利用watcher来监听额外的事件或者向watch中添加文件。例如,在执行一系列任务和调用一个函数时,你就可以在返回的watcher中添加监听change事件:
var watcher = gulp.watch(‘templates/*.tmpl.html‘, [‘build‘]); watcher.on(‘change‘, function (event) { console.log(‘Event type: ‘ + event.type); // added, changed, or deleted console.log(‘Event path: ‘ + event.path); // The path of the modified file });
除了change事件,还可以监听很多其他的事件:
Watcher对象也包含了一些可以调用的方法:
当一个文件被修改或者Gulp任务被执行时可以用Gulp来加载或者更新网页。LiveReload和BrowserSync插件就可以用来实现在游览器中加载更新的内容。
LiveReload结合了浏览器扩展(包括Chrome extension),在发现文件被修改时会实时更新网页。它可以和gulp-watch插件或者前面描述的gulp-watch()函数一起使用。下面有一个gulp-livereload仓库中的README文件提到的例子:
var gulp = require(‘gulp‘), less = require(‘gulp-less‘), livereload = require(‘gulp-livereload‘), watch = require(‘gulp-watch‘); gulp.task(‘less‘, function() { gulp.src(‘less/*.less‘) .pipe(watch()) .pipe(less()) .pipe(gulp.dest(‘css‘)) .pipe(livereload()); });
这会监听到所有与less/*.less相匹配的文件的变化。一旦监测到变化,就会生成css并保存,然后重新加载网页.
BroserSync在浏览器中展示变化的功能与LiveReload非常相似,但是它有更多的功能。
当你改变代码的时候,BrowserSync会重新加载页面,或者如果是css文件,会直接添加进css中,页面并不需要再次刷新。这项功能在网站是禁止刷新的时候是很有用的。假设你正在开发单页应用的第4页,刷新页面就会导致你回到开始页。使用LiveReload的话,你就需要在每次改变代码之后还需要点击四次,而当你修改CSS时,插入一些变化时,BrowserSync会直接将需要修改的地方添加进CSS,就不用再点击回退。
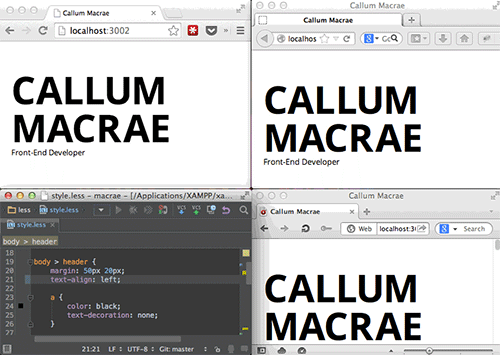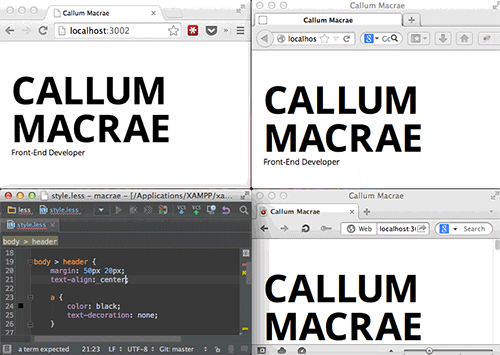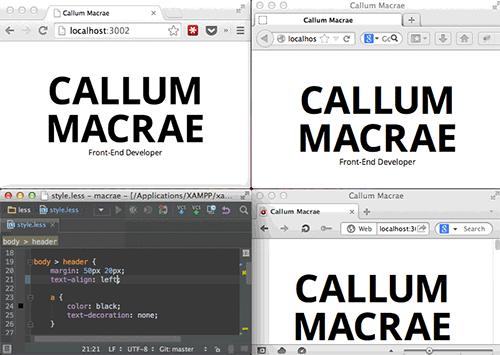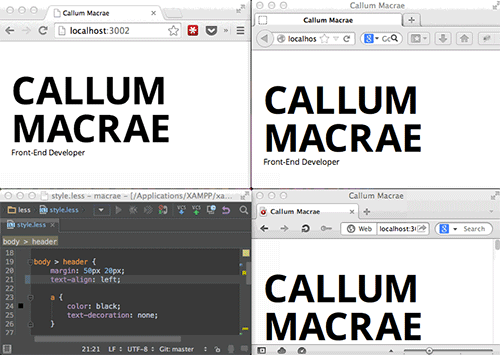
BrowserSync提供了一种在多个浏览器里测试网页的很好方式(查看大图)。
BrowserSync也可以在不同浏览器之间同步点击翻页、表单操作、滚动位置。你可以在电脑和iPhone上打开不同的浏览器然后进行操作。所有设备上的链接将会随之变化,当你向下滚动页面时,所有设备上页面都会向下滚动(通常还很流畅!)。当你在表单中输入文本时,每个窗口都会有输入。当你不想要这种行为时,也可以把这个功能关闭。
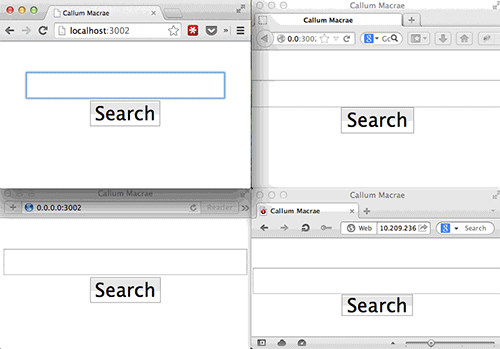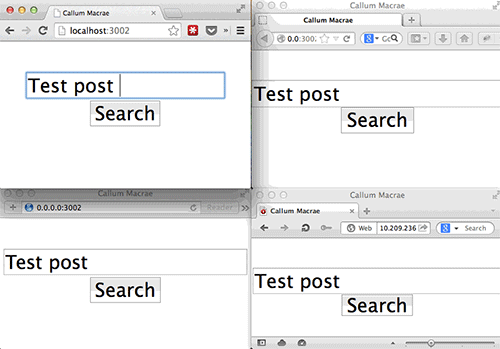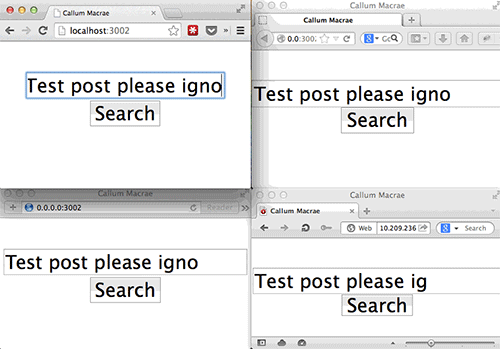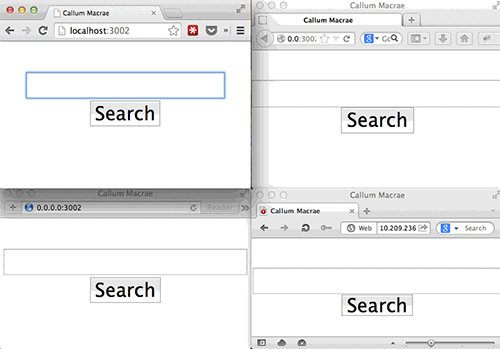
BrowserSync不需要使用浏览器插件,因为它本身就可以给你提供文件。(查看大图)
BrowserSync不需要使用浏览器插件,因为它本身就可以为你提供文件服务(如果文件是动态的,则为他们提供代理服务)和用来开启浏览器和服务器之间的socket的脚本服务。到目前为止这个功能的使用都十分顺畅。
实际上BrowserSync对于Gulp并不算一种插件,因为BrowserSync并不像一个插件一样操作文件。然而,npm上的BrowserSync模块能在Gulp上被直接调用。
首先,需要通过npm安装一下:
npm install --save-dev browser-sync
然后gulpfile.js会启动BrowserSync并监听文件:
var gulp = require(‘gulp‘), browserSync = require(‘browser-sync‘); gulp.task(‘browser-sync‘, function () { var files = [ ‘app/**/*.html‘, ‘app/assets/css/**/*.css‘, ‘app/assets/imgs/**/*.png‘, ‘app/assets/js/**/*.js‘ ]; browserSync.init(files, { server: { baseDir: ‘./app‘ } }); });
执行gulp browser-sync后会监听匹配文件的变化,同时为app目录提供文件服务。
此外BrowserSync的开发者还写了很多关于BrowserSync+Gulp仓库的其他用途。
前面提到过,Gulp是为数不多的使用JavaScript开发的构建工具之一,也有其他不是用JavaScript开发的构建工具,比如Rake,那么我们为什么要选择Gulp呢?
目前最流行的两种使用JavaScript开发的构建工具是Grunt和Gulp。Grunt在2013年非常流行,因为它彻底改变了许多人开发网站的方式,它有上千种插件可供用户使用,从linting、压缩、合并代码到使用Bower安装程序包,启动Express服务都能办到。这些和Gulp的很不一样,Gulp只有执行单个小任务来处理文件的插件,因为任务都是JavaScript(和Grunt使用的大型对象不同),根本不需要插件,你只需用传统方法启动一个Express服务就可以了。
Grunt任务拥有大量的配置,会引用大量你实际上并不需要的对象属性,但是Gulp里同样的任务也许只有几行。让我们看个简单的Gruntfile.js,它规定一个将LESS转换为CSS的任务,然后执行Autoprefixer:
grunt.initConfig({ less: { development: { files: { "build/tmp/app.css": "assets/app.less" } } }, autoprefixer: { options: { browsers: [‘last 2 version‘, ‘ie 8‘, ‘ie 9‘] }, multiple_files: { expand: true, flatten: true, src: ‘build/tmp/app.css‘, dest: ‘build/‘ } } }); grunt.loadNpmTasks(‘grunt-contrib-less‘); grunt.loadNpmTasks(‘grunt-autoprefixer‘); grunt.registerTask(‘css‘, [‘less‘, ‘autoprefixer‘]);
与Gulpfile.js文件进行对比,它们执行的任务相同:
var gulp = require(‘gulp‘), less = require(‘gulp-less‘), autoprefix = require(‘gulp-autoprefixer‘); gulp.task(‘css‘, function () { gulp.src(‘assets/app.less‘) .pipe(less()) .pipe(autoprefix(‘last 2 version‘, ‘ie 8‘, ‘ie 9‘)) .pipe(gulp.dest(‘build‘)); });
因为Grunt比Gulp更加频繁地操作文件系统,所以使用数据流的Gulp总是比Grunt快。对于一个小的LESS文件,gulpfile.js通常需要6ms,而gruntfile.js则需要大概50ms——慢8倍多。这只是个简单的例子,对于长的文件,这个数字会增加得更显著。
标签:
原文地址:http://www.cnblogs.com/Midaoi/p/4969812.html