标签:
redis中的hash也是我们使用中的高频数据结构,它的构造基本上和编程语言中的HashTable,Dictionary大同小异,如果大家往后有什么逻辑需要用
Dictionary存放的话,可以根据场景优先考虑下redis哦,起码可以装装逼嘛,现在我默认你已经有装逼的冲动了,打开redis手册,看看有哪些我们用得到
的装逼方法。
一:常用方法
只要是一个数据结构,最基础的永远是CURD,redis中的insert和update,永远只需要set来替代,比如下面的Hset,如下图:

前面几篇文章我都没有挑选一个方法仔细讲解,其实也没什么好讲解的,就好似C#中的一个类的一个方法而已,知道传递一些啥参数就OK了,就比如要
说的HSet,它的格式如下:

接下来我在CentOS里面操作一下,
[administrator@localhost redis-3.0.5]$ src/redis-cli 127.0.0.1:6379> clear 127.0.0.1:6379> hset person name jack (integer) 1 127.0.0.1:6379> hset person age 20 (integer) 1 127.0.0.1:6379> hset person sex famale (integer) 1 127.0.0.1:6379> hgetall person 1) "name" 2) "jack" 3) "age" 4) "20" 5) "sex" 6) "famale" 127.0.0.1:6379> hkeys person 1) "name" 2) "age" 3) "sex" 127.0.0.1:6379> hvals person 1) "jack" 2) "20" 3) "famale" 127.0.0.1:6379>
或许有人看了上面的console有一点疑惑,那就是前面有几个参数,比如person,name啦,然后才是value,如果你看了第一篇的话,你大概就明白了,
其实在redis的这个层面,它永远只有一个键,一个值,这个键永远都是字符串对象,也就是SDS对象,而值的种类就多了,有字符串对象,有队列对象,
还有这篇的hash对象,往后的有序集合对象等等,如果你还不明白的话,转化为C#语言就是。
1 var person=new Dictionary<string,string>(); 2 person.Add("name","jack"); 3 ....
调用方法就是这么的简单,关键在于时不时的需要你看一看手册,其实最重要的是了解下它在redis源码中的原理就好了。
二:探索原理
hash的源代码是在dict.h源代码里面,枚举如下:
typedef struct dictEntry { void *key; union { void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next; } dictEntry; typedef struct dictType { unsigned int (*hashFunction)(const void *key); void *(*keyDup)(void *privdata, const void *key); void *(*valDup)(void *privdata, const void *obj); int (*keyCompare)(void *privdata, const void *key1, const void *key2); void (*keyDestructor)(void *privdata, void *key); void (*valDestructor)(void *privdata, void *obj); } dictType; /* This is our hash table structure. Every dictionary has two of this as we * implement incremental rehashing, for the old to the new 0. */ typedef struct dictht { dictEntry **table; unsigned long size; unsigned long sizemask; unsigned long used; } dictht; typedef struct dict { dictType *type; void *privdata; dictht ht[2]; long rehashidx; /* rehashing not in progress if rehashidx == -1 */ int iterators; /* number of iterators currently running */ } dict; /* If safe is set to 1 this is a safe iterator, that means, you can call * dictAdd, dictFind, and other functions against the dictionary even while * iterating. Otherwise it is a non safe iterator, and only dictNext() * should be called while iterating. */ typedef struct dictIterator { dict *d; long index; int table, safe; dictEntry *entry, *nextEntry; /* unsafe iterator fingerprint for misuse detection. */ long long fingerprint; } dictIterator;
上面就是我们使用hash的源代码数据结构,接下来我来撸一撸其中的逻辑关系。
1. dict结构
1 typedef struct dict { 2 dictType *type; 3 void *privdata; 4 dictht ht[2]; 5 long rehashidx; /* rehashing not in progress if rehashidx == -1 */ 6 int iterators; /* number of iterators currently running */ 7 } dict;
这个结构是hash的真正的底层数据结构,可以看到其中有5个属性。
<1> dictType *type
可以看到它的类型是dictType,从上面你也可以看到,它是有枚举结构定义的,如下:
1 typedef struct dictType { 2 unsigned int (*hashFunction)(const void *key); 3 void *(*keyDup)(void *privdata, const void *key); 4 void *(*valDup)(void *privdata, const void *obj); 5 int (*keyCompare)(void *privdata, const void *key1, const void *key2); 6 void (*keyDestructor)(void *privdata, void *key); 7 void (*valDestructor)(void *privdata, void *obj); 8 } dictType;
从上面这个数据结构中你可以看到里面都是一些方法,但是有一个非常重要的方法,那就是第一个hashFunction,可以看到它就是计算hash值的,
跟C#中的dictionary中求hash值一样一样的。
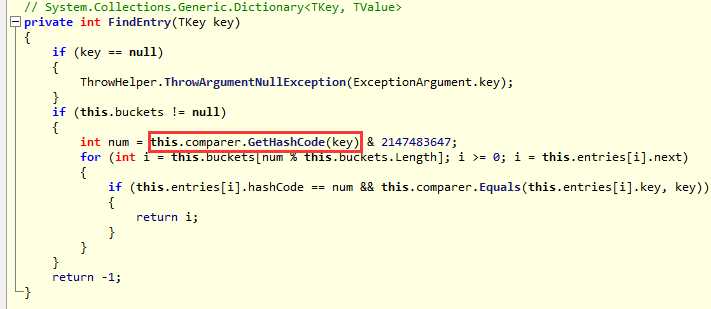
<2> dictht ht[2]
你可能会疑问,为什么这个属性是2个大小的数组呢,其实正真使用的是ht[0],而ht[1]是用于扩容hash表时的暂存数组,这一点也很奇葩,
同时也很精妙,redis为什么会这么做呢???仔细想想你可能会明白,扩容有两种方法,要么一次性扩容,要么渐进性扩容,后面这种扩容是什
么意思呢?就是我在扩容的同时不影响前端的CURD,我慢慢的把数据从ht[0]转移到ht[1]中,同时rehashindex来记录转移的情况,当全部转移
完成之后,将ht[1]改成ht[0]使用,就这么简单。
2. dicth结构
1 typedef struct dictht { 2 dictEntry **table; 3 unsigned long size; 4 unsigned long sizemask; 5 unsigned long used; 6 } dictht;
<1> dictEntry **table;
从上面这个结构体中,你可以看到一个非常重要的属性: dictEntry **table, 其中table是一个数组,数组类型是dictEntry,既然是一个数组,
那后面的三个属性就好理解了,size是数组的大小,sizemask和数组求模有关,used记录数组中已使用的大小,现在我们把注意力放在dictEntry这
个数组实体类型上面。
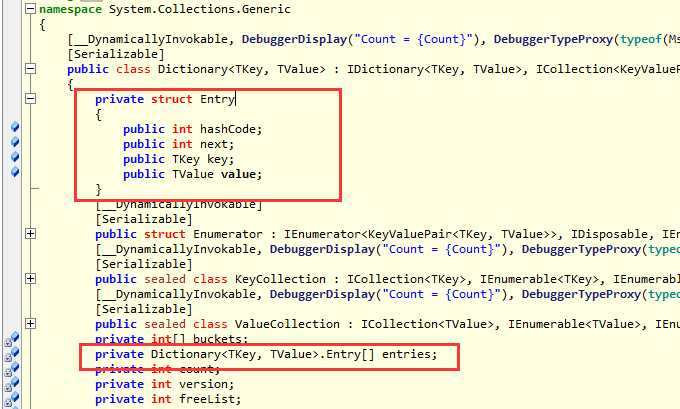
3. dictEntry结构
1 typedef struct dictEntry { 2 void *key; 3 union { 4 void *val; 5 uint64_t u64; 6 int64_t s64; 7 double d; 8 } v; 9 struct dictEntry *next; 10 } dictEntry;
从这个数据结构上面你可以看到有三个大属性。
第一个就是: *key:它就是hash表中的key。
第二个就是: union的*val 就是hash的value。
第三个就是: *next就是为了防止hash冲突采用的挂链手段。
这个原理和C#中的Dictionary还是一样一样的。
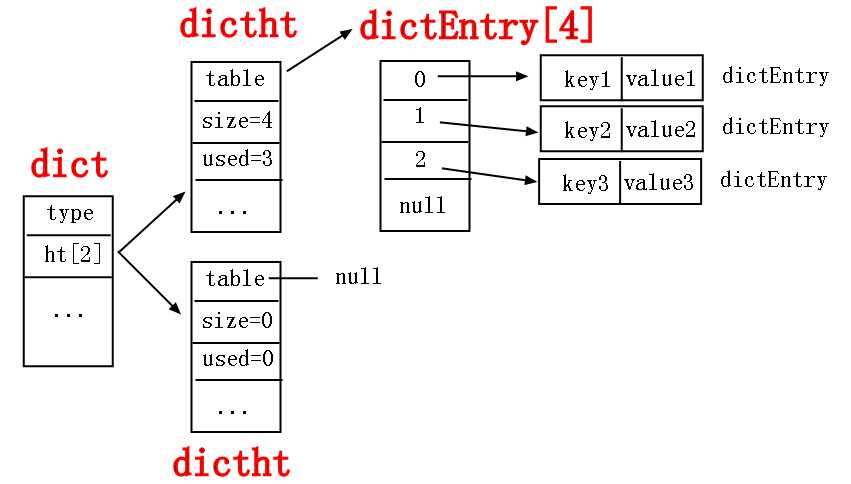
不知道你看懂了没有,如果总结上面描述的话,我可以画出如下的hash结构图。
好了,就此打住,去公司了。
标签:
原文地址:http://www.cnblogs.com/huangxincheng/p/4973594.html