标签:
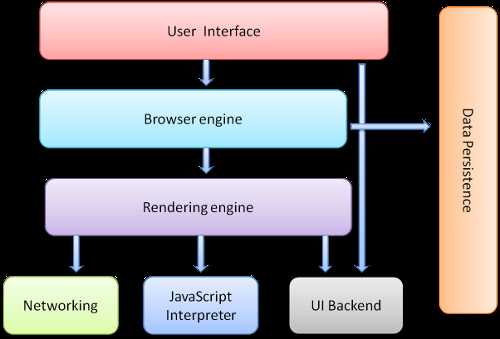
一、浏览器主要构成
1. 用户界面 - 包括地址栏、后退/前进按钮、书签目录等,也就是你所看到的除了用来显示你所请求页面的主窗口之外的其他部分。
2. 浏览器引擎 - 用来查询及操作渲染引擎的接口。
3. 渲染引擎 - 用来显示请求的内容,例如,如果请求内容为html,它负责解析html及css,并将解析后的结果显示出来。
4. 网络 - 用来完成网络调用,例如http请求,它具有平台无关的接口,可以在不同平台上工作。
5. UI后端 - 用来绘制类似组合选择框及对话框等基本组件,具有不特定于某个平台的通用接口,底层使用操作系统的用户接口。
6. JS解释器 - 用来解释执行JS代码。
7. 数据存储 - 属于持久层,浏览器需要在硬盘中保存类似cookie的各种数据,HTML5定义了web database技术,这是一种轻量级完整的客户端存储技术
二、渲染引擎
本文所讨论的浏览器——Firefox、Chrome和Safari是基于两种渲染引擎构建的,Firefox使用Geoko——Mozilla自主研发的渲染引擎,Safari和Chrome都使用webkit。
Webkit是一款开源渲染引擎,它本来是为Linux平台研发的,后来由Apple移植到Mac及Windows上,相关内容请参考http://webkit.org。
渲染引擎首先通过网络获得所请求文档的内容,通常以8K分块的方式完成。
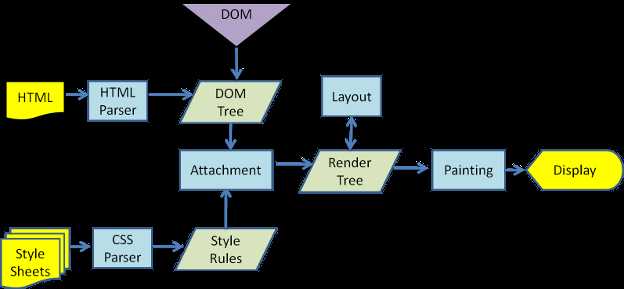
下面是渲染引擎在取得内容之后的基本流程:
解析html以构建dom树 -> 构建render树 -> 布局render树 -> 绘制render树

渲染引擎开始解析html,并将标签转化为内容树中的dom节点。接着,它解析外部CSS文件及style标签中的样式信息。这些样式信息以及html中的可见性指令将被用来构建另一棵树——render树。
Render树由一些包含有颜色和大小等属性的矩形组成,它们将被按照正确的顺序显示到屏幕上。
Render树构建好了之后,将会执行布局过程,它将确定每个节点在屏幕上的确切坐标。再下一步就是绘制,即遍历render树,并使用UI后端层绘制每个节点。
值得注意的是,这个过程是逐步完成的,为了更好的用户体验,渲染引擎将会尽可能早的将内容呈现到屏幕上,并不会等到所有的html都解析完成之后再去构建和布局render树。它是解析完一部分内容就显示一部分内容,同时,可能还在通过网络下载其余内容。
webkit:
Gecko:
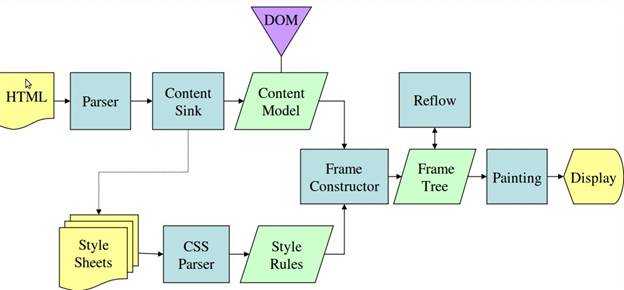
图4:Mozilla的Geoko渲染引擎主流程
从图3和4中可以看出,尽管webkit和Gecko使用的术语稍有不同,他们的主要流程基本相同。Gecko称可见的格式化元素组成的树为frame树,每个元素都是一个frame,webkit则使用render树这个名词来命名由渲染对象组成的树。Webkit中元素的定位称为布局,而Gecko中称为回流。Webkit称利用dom节点及样式信息去构建render树的过程为attachment,Gecko在html和dom树之间附加了一层,这层称为内容接收器,相当制造dom元素的工厂。
三、DOM解析
HTML的DOM Tree解析如下:
<html>
<head>
<title>Web page parsing</title>
</head>
<body>
<div>
<h1>Web page parsing</h1>
<p>This is an example Web page.</p>
</div>
</body>
</html>
上面这段HTML会解析成这样:
下面是另一个有SVG标签的情况。
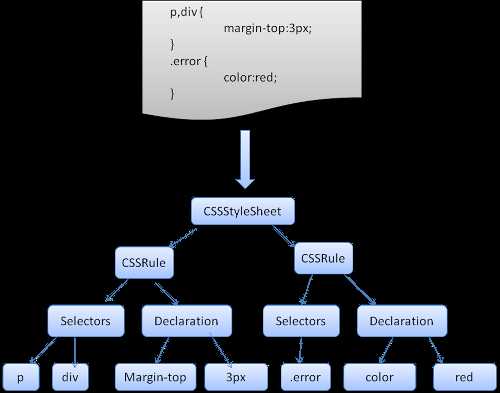
四、CSS解析
Webkit使用Flex和Bison解析生成器从CSS语法文件中自动生成解析器。回忆一下解析器的介绍,Bison创建一个自底向上的解析器,Firefox使用自顶向下解析器。它们都是将每个css文件解析为样式表对象,每个对象包含css规则,css规则对象包含选择器和声明对象,以及其他一些符合css语法的对象。
web的模式是同步的,开发者希望解析到一个script标签时立即解析执行脚本,并阻塞文档的解析直到脚本执行完。如果脚本是外引的,则网络必须先请求到这个资源——这个过程也是同步的,会阻塞文档的解析直到资源被请求到。这个模式保持了很多年,并且在html4及html5中都特别指定了。开发者可以将脚本标识为defer,以使其不阻塞文档解析,并在文档解析结束后执行。Html5增加了标记脚本为异步的选项,以使脚本的解析执行使用另一个线程。
Webkit和Firefox都做了这个优化,当执行脚本时,另一个线程解析剩下的文档,并加载后面需要通过网络加载的资源。这种方式可以使资源并行加载从而使整体速度更快。需要注意的是,预解析并不改变Dom树,它将这个工作留给主解析过程,自己只解析外部资源的引用,比如外部脚本、样式表及图片,也就是不会使外部脚本操作DOM树。
样式表采用另一种不同的模式。理论上,既然样式表不改变Dom树,也就没有必要停下文档的解析等待它们,然而,存在一个问题,脚本可能在文档的解析过程中请求样式信息,如果样式还没有加载和解析,脚本将得到错误的值,显然这将会导致很多问题,这看起来是个边缘情况,但确实很常见。Firefox在存在样式表还在加载和解析时阻塞所有的脚本,而Chrome只在当脚本试图访问某些可能被未加载的样式表所影响的特定的样式属性时才阻塞这些脚本。
标签:
原文地址:http://www.cnblogs.com/shytong/p/4987032.html