在分布式存储系统中,将数据分布至多个节点的方式之一是使用哈希算法。假设初始节点数为 N,则传统的对 N 取模的映射方式存在一个问题在于:当节点增删,即 N 值变化时,整个哈希表(Hash Table)需要重新映射,这便意味着大部分数据需要在节点之间移动。
因此现在普遍使用的是被称为一致性哈希(Consistent Hashing)的一类算法。“一致性” 这个定语的意义在于:当增删节点时,只影响到与变动节点相邻的一个或两个节点,散列表的其他部分与原来保持一致。某种程度上可以将其理解为:一致性哈希算法的哈希函数与节点数 N 无关。
其他地方对一致性哈希配图的时候,都会选择一个圆环来解释,但我个人感觉哈希表更加直观:

上图左右分别表示增加一个 “节点 5” 前后的哈希表,哈希函数使用的是 md5 。md5 会根据 key 的值摘要出一个 128 bit 的哈希值(校验和),一般表示为一个 32 位的 16 进制数。这里我们取哈希值第一位的范围来将 key 映射到不同的节点,可以看到在拆分了 “节点 4” 的 md5 首位范围后,只需要将 “节点 4” 原本数据的约一半移动到 “节点 5” 上去就可以了,其他三个节点并未受到影响。
但这里其实仍有改进的空间。
问题在于,上面需要将 “节点 4” 的一半数据搬运到 “节点 5” 上,这个压力会比较大。以一个节点存有 3TB 的数据、节点间网络为千兆网(但只允许搬运进程使用 25% 负载)来算,搬运完 1.5TB 的数据最少需要 (1.5TB * 1024GB/TB * 1024MB/GB) / (125MB/s * 0.25) ≈ 14h;另一方面,“节点 5” 直接分担走了 “节点 4” 数据的一半,如果原来 4 个节点的负载是均衡的(md5 本身是一个很均匀的哈希函数),那么现在就变得不均衡了。
这两个问题有一个公共的解决方法:新增的 “节点 5” 不只从 “节点 4” 搬运数据,而从所有其他节点(或子集)处搬运数据,同时还要继续保持哈希一致性。
这种想法的一个实现方式就是,使用虚拟节点(virtual nodes)。上面 md5 哈希表实际可以分为两段:
当使用虚拟节点时,我们保持第一段不变,但会在第二段将哈希值映射到物理节点的过程中再插入一个虚拟节点中间件,从而将过程变为:
新哈希表的关键之处在于虚拟节点的数量比物理节点数多得多,甚至很多时候会将虚拟节点的数量设置为 “尽可能多”。这样新哈希表的前两段就固定不变了,当增删物理节点时,只是对虚拟节点进行必要的重新分配的过程。
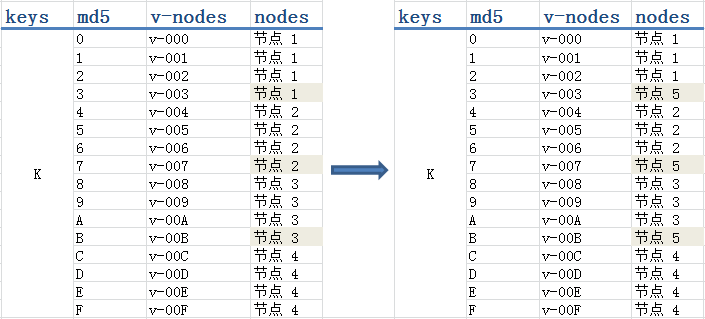
上图中我们依 md5 值的首位划分了 16 个虚拟节点,然后将它们映射到 4 个物理节点。(实际应用中,即使你当下只有 10 个物理节点,也大可以按 md5 的前三位划分出 4096 个虚拟节点)当我们增加物理 “节点 5” 的时候,就从节点 1、2、3 处各拿一个虚拟节点放到 “节点 5” 中。这个过程,“节点 5” 既可以使用 100% 的网络带宽来接收数据;新的哈希表也实现了负载均衡。当然一致性也得到了保证。
这种使用虚拟节点的一致性哈希算法我看到国内有人管它叫分布式一致性哈希(Distributed Consistent Hashing),但这个 “分布式” 叫法显得有些不合适,因为这种改进只涉及到算法的实现而与哈希过程发生的位置无关,并且 google 上也找不到这种叫法。所以一般就称改进的一致性哈希(Improved Consistent Hashing)好了。或者,使用虚拟节点的一致性哈希。
使用虚拟节点改进的一致性哈希算法,布布扣,bubuko.com
原文地址:http://my.oschina.net/lionets/blog/288066