标签:
Hadoop项目是什么?
Hadoop是一个适合大数据的分布式存储与计算平台。
作者:Doug Cutting;Lucene,Nutch。
受Google三篇论文的启发
Hadoop核心项目
HDFS: Hadoop Distributed File System 分布式文件系统
MapReduce:并行计算框架
Hadoop架构Hdfs架构
(1) 主从结构
•主节点,只有一个: namenode
•从节点,有很多个: datanodes
(2) namenode负责:管理
•接收用户操作请求,可以实现对文件系统的操作(一般的操作方式有两种,命令行方式和Java API方式)
•维护文件系统的目录结构(用来对文件进行分类管理)。
•管理文件与block之间关系(文件被划分成了Block,Block属于哪个文件,以及Block的顺序好比电影剪辑),block与datanode之间关系。
(3) datanode负责:存储
•存储文件
•文件被分成block(block一般是以64M来划分,但每个Block块所占用的空间是文件实际的空间)存储在磁盘上,将大数据划分成相对较小的block块,这样可以充分利用磁盘空间,方便管理。
•为保证数据安全,文件会有多个副本(就好比配钥匙,都是为了预防丢失),这些副本会一块一块复制,分别存储在不同的DataNode上。
MapReduce架构
(1)主从结构
•主节点,只有一个: JobTracker
•从节点,有很多个: TaskTrackers
(2)JobTracker 负责:
•接收客户提交的计算任务
•把计算任务分给TaskTrackers执行
•监控TaskTracker的执行情况
(3)TaskTrackers负责:
•执行JobTracker分配的计算任务
Hadoop的特点
(1) 扩容能力(Scalable):能可靠地(reliably)存储和处理千兆字节(PB)数据。
(2) 成本低(Economical):可以通过普通机器组成的服务器群来分发以及处理数据。这些服务器群总计可达数千个节点。
(3) 高效率(Efficient):通过分发数据,hadoop可以在数据所在的节点上并行地处理它们,这使得处理非常的快速。
(4) 可靠性(Reliable):hadoop能自动地维护数据的多份副本,并且在任务失败后能自动地重新部署计算任务。
Hadoop集群的物理分布
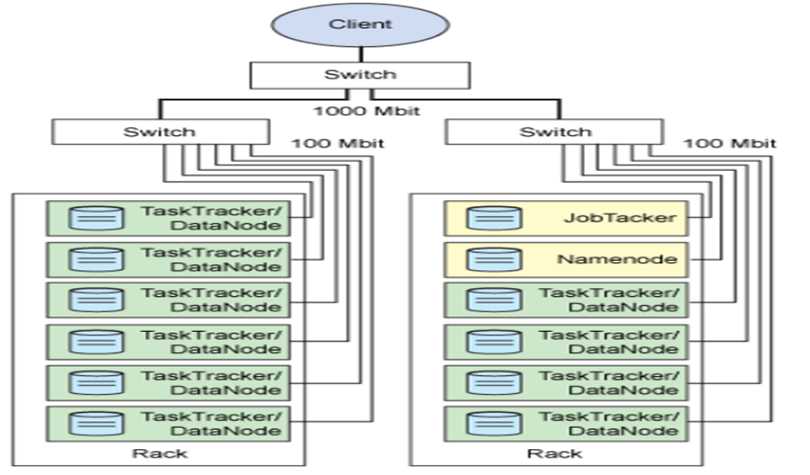
图1 Hadoop集群的物理分布
这里是一个由两个机架组成的机群,图中有两种颜色绿色和黄色,不难看出黄色为主节点(Master),NameNode和JobTracker都独占一个服务器,只有一个是唯一,绿色为从节点(Slave)有多个。而上面所说的JobTracker、NameNode,DataNode,TaskTracker本质都是Java进程,这些进程进行相互调用来实现各自的功能,而主节点与从节点一般运行在不同的java虚拟机之中,那么他们之间的通信就是跨虚拟机的通信。
这些机群上放的都是服务器,服务器本质上就是物理硬件,服务器是主节点还是从节点,主要看是跑的是什么角色或进程,如果上面跑的是Tomcat他就是WEB服务器,跑的是数据库就是数据库服务器,所以当服务器上跑的是NameNode或JobTracker是就是主节点,跑的是DataNode或TaskTracker就是从节点。
为了实现高速通信,我们一般都使用局域网,在内网中可使用千兆网卡、高频交换机、光纤等。
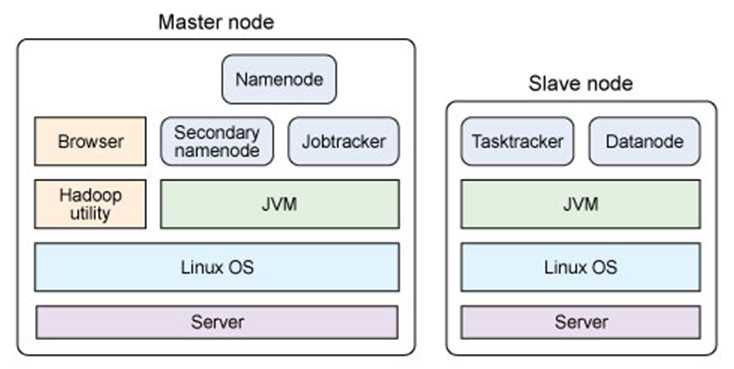
Hadoop集群单节点物理结构
标签:
原文地址:http://www.cnblogs.com/thinkpad/p/4990430.html