标签:
第三部分 正则表达式和grep
本章主要通过一些应用实例,来对正则表达式进行说明。
1 正则表达式
正则表达式就是字符串的表达式。它能通过具有意义的特殊符号表示一列或多列字符串。
grep是linux系统下常用的正则表达式工具,可以使用grep来检索文本等输入流的字符串。
参考下面表格
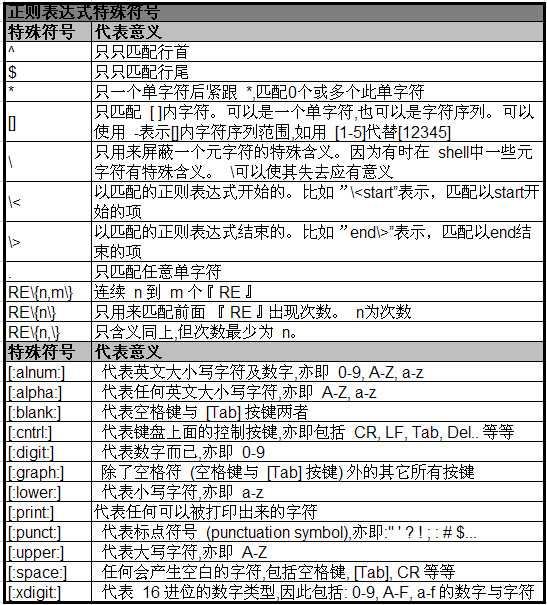
基本格式
grep [OPTIONS] PATTERN [FILE...]
格式说明
PATTERN : 匹配模式。可以是字符串,也可以是正则表达式。
[FILE...] : 是grep搜索的文件(集)
[OPTIONS] : 是grep的选项。常用的选项有以下选项。
-c : 只输出匹配行的计数。
-I : 不区分大 小写(只适用于单字符)。
-h : 查询多文件时不显示文件名。
-l : 查询多文件时只输出包含匹配字符的文件名。
-n : 显示匹配行及 行号。
-s : 不显示不存在或无匹配文本的错误信息。
-v : 显示不包含匹配文本的所有行。
-r : 当FILE中包含文件夹名时,遍历该文件夹的所有子目录;默认情况下,不会遍历子目录。
下面以input.txt为例,对grep进行说明。input.txt的文本内容如下:

"Open Source" is a good mechanism to develop programs.
apple is my favorite food.
Football game is not use feet only.
this dress doesn‘t fit me.
However, this dress is about $ 3183 dollars.^M
GNU is free air not free beer.^M
Her hair is very beauty.^M
I can‘t finish the test.^M
Oh! The soup taste good.^M
motorcycle is cheap than car.
This window is clear.
the symbol ‘*‘ is represented as start.
Oh!
My god!
The gd software is a library for drafting programs.^M
You are the best is mean you are the no. 1.
The world <Happy> is the same with "glad".
I like dog.
google is the best tools for search keyword.
goooooogle yes!
go! go! Let‘s go
(01), 查找包含“the”的行,并显示行号。
$ grep -n "the" input.txt
说明:-n表示显示“行号”
(02), 不区分大小写,查找包括“the”的行,并显示行号。
$ grep -in "the" input.txt
说明:-n表示显示“行号”;-i表示不区分大小写,即ignore大小写。
(03), 查找不包括“the”的行,统计行数。
$ grep -cv "the" input.txt
说明:-c表示统计(count);-v表示不匹配的项。
(04), 查找“当前目录”及其“所有子目录”中包含“the”的文件,并显示“the”在其中的行号。
$ grep -rn "the" .
说明:-r表示递归查找;-n表示显示行号。
(05), 查找匹配“t?st”的项,其中?为任意字符。
$ grep -n "t.st" input.txt
说明:.表示匹配任意字符
(06), 查找包含数字的行
$ grep -n "[0-9]" input.txt
或
$ grep -n "[[:digit:]]" input.txt
说明:[0-9]表示0-9之间的一个数字;[[:digit:]]也表示0-9之间的一个数字
(07), 查找以the开头的行
$ grep -n "^the" input.txt
说明:"^the"表示以the开头
(08), 查找以小写字母结尾的行。
$ grep -n "[a-z]$" input.txt
说明:[a-z]表示一个小写字母,$表示结束符;[a-z]$表示以小写字母结束的项。
(09), 查找空白行。
$ grep -n "^$" input.txt
说明:^表示开头,如^t表示以字母t开头;$表示结尾,如e$表示以e结尾。^$表示空白行。
(10), 查找以字母g开头的单词
$ grep -n "\<g" input.txt
说明:\<表示单词的开始,\<g表示以g开始的单词。
(11), 查找字符串为go的单词。注意:不能包括goo,good等字符串
$ grep -n "\<go\>" input.txt
说明:\<表示单词的开始,\>表示单词结尾。\<go\>表示以字母g开头,以字母o结尾。
(12), 查找包括2-5个字母o的行。
$ grep -n "o\{2,5\}" input.txt
说明:pattern\{n,m\}表示n到m个pattern。o\{2,5\}表示2-5个字母o。
(13), 查找包括2个以上字母o(包括2个)的行。
$ grep -n "ooo*" input.txt
或
$ grep -n "oo\+" input.txt
或
$ grep -n "o\{2,\}" input.txt
说明:
ooo*: 前面两个oo表示匹配2个字母o,后面的o*表示匹配0到多个字母o。
oo\+: 第一个字母o表示匹配单个字母o;最后的“o\+”一起发挥作用,其中,\+是转义后的+,表示1到多个;而o\+表示1到多个字母o。
pattern\{n,\}表示多于n个pattern。o\{2,\}表示多于2个字母o。
egrep是扩展的grep,即它的功能比grep更多一些。"egrep"等价于"grep -e"。
egrep相比与grep,支持括号“()”以及操作符“|”(表示或)。
仍然以上面的input.txt为输入文本进行说明
(01), 查找包含the或者this的行
$ egrep -n "the|this" input.txt
说明:-n表示输出匹配项的行号,"the|this"表示包括the或者包括this的项。
(02), 查找包含the或者this的行
$ egrep -vn "(the|this)" input.txt
说明:-n表示输出匹配项的行号,"the|this"表示包括the或者包括this的项;-v表示匹配的对立面。即 -v "the|this"表示既不包括the又不包括this的项。
标签:
原文地址:http://www.cnblogs.com/winner-0715/p/4994324.html