标签:
神经网络是如何一步步进行计算的,以及对计算过程的向量化
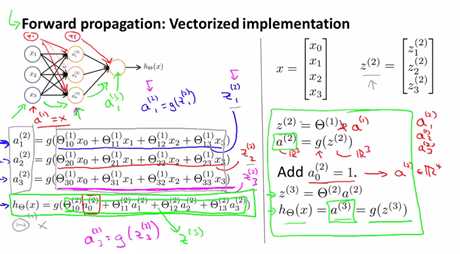
Z1(2),Z2(2),Z3(2) are just weighted linear combination of input value x1,x2,x3.上图右边灰色框里面的为Z(2),为3*1矩阵。
a1(2)=g(Z1(2))......a(2)为3*1的矩阵,对Z(2) 里面的每个元素应用g函数.
上述的计算我们可以分为两步,一步是计算Z(2),一步是计算a(2),如上图所示。
我们将input的x定义为a(1),所以将x写成a(1)(将其做为第一层的activations).
增加bias unit,a0(2)=1,则a(2)为4*1矩阵.
最后的结果,计算z(3),和a(3)=hΘ(x)=g(z(3)).
这个计算的过程也称为forward propagation,因为它的计算从input到output是一层一层推进(activation)的.我们将其计算过程向量化了,若我们按照右边绿色框中的进行计算的话,用矩阵与向量进行计算,这样计算更高效。
Neural network learning its own features
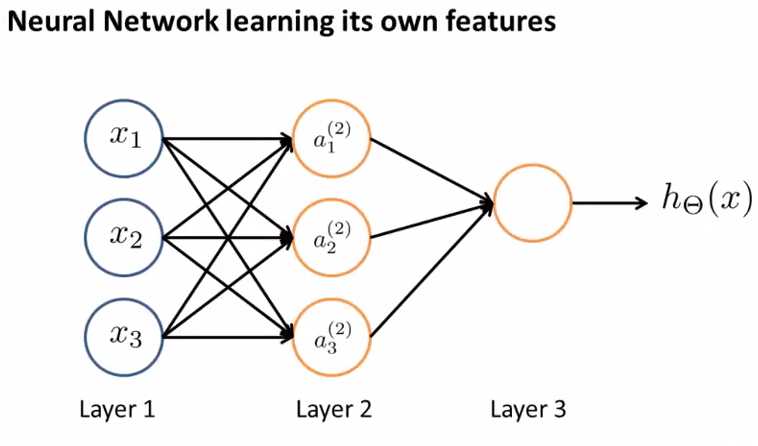
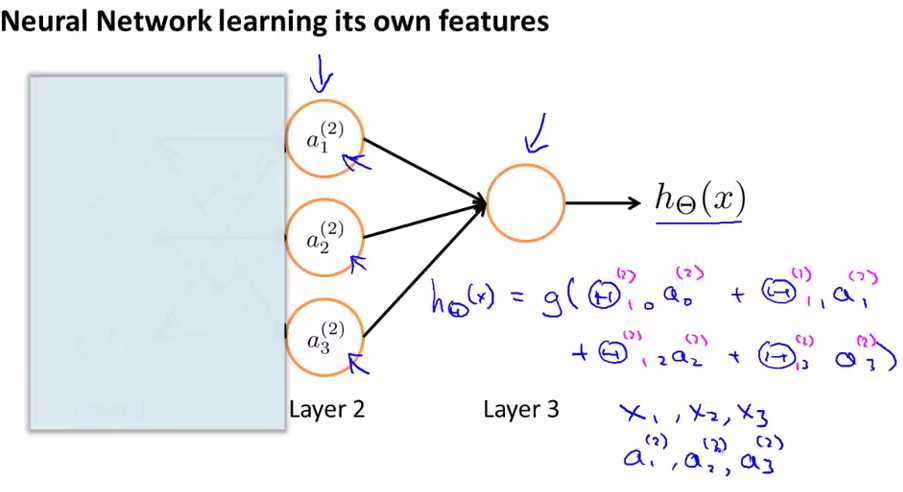
如果我们将左边的input遮住,只看右部分的话,和logistic regression很相似,如果我们只看右边蓝色部分的式子的话,我们会发现它和标准的logistic regression model是一样的(除了我们使用的是大写的Θ),但是这部分所做的就是logistic regression,但是它的input是由hidden layer(layer 2)计算后的输出,即这部分所做的和logistic regression是一样的,除了logistic regression输入是x1,x2,x3,而它的输入是a1(2),a2(2),a3(2).
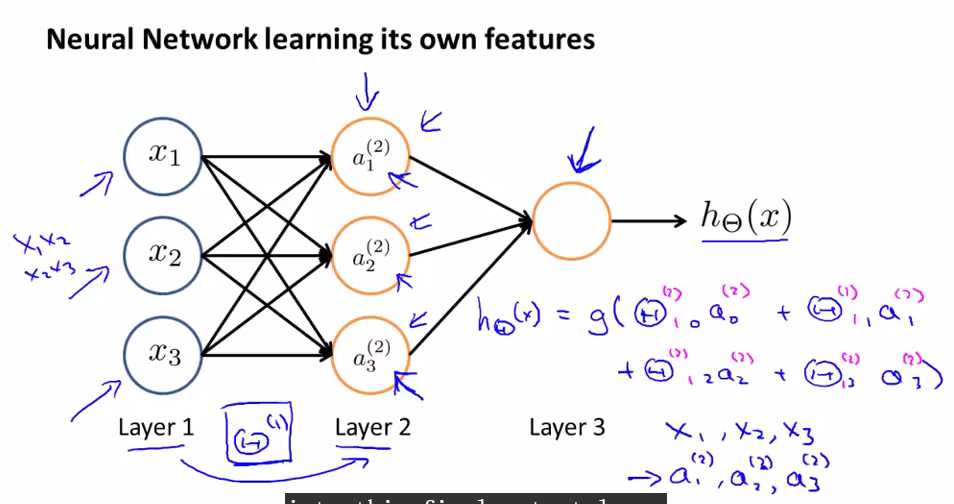
a1(2),a2(2),a3(2)它们是自己learn function from input,从layer1到layer2的function是由Θ(1)来构成的,所以神经网络不是feed x1,x2,x3 to logistic regression,而是自己学习自己的features(a1(2),a2(2),a3(2)),然后将它们feed into logistic regression,并且取决于我们选择的Θ(1),你可以学习一些非常有趣复杂的features,然后你会得出一个better hypotheses(相比使用原始的x1,x2,x3或者x1,x2,x3的多项式来说),总之算法在选择参数上是灵活的,选择了参数后得到a1(2),a2(2),a3(2),然后再将它们feed into logistic regression(即最后一个结点).
神经网络结构
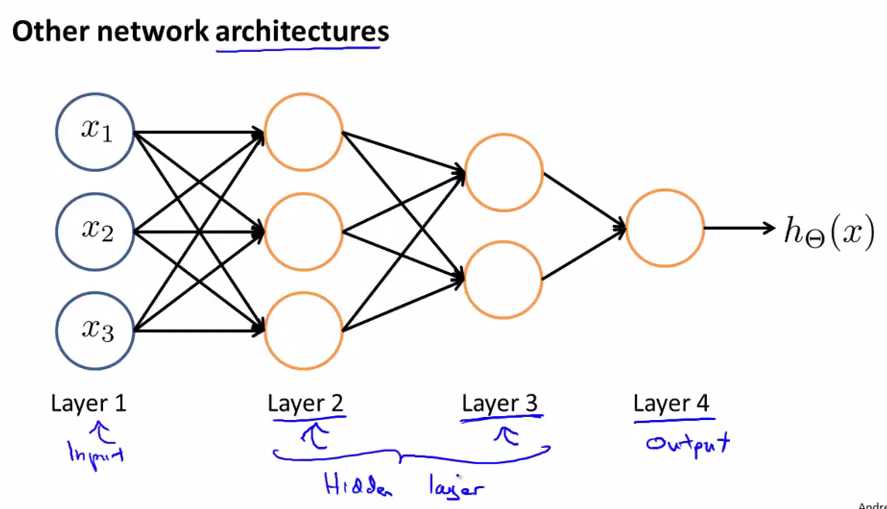
architectures是指神经网络的连接方式,上图是一种不同的neural network architecture, layer2可以接收来自layer1的输入,然后计算出复杂的features,layer3接收来自layer2的输入,计算出更为复杂的features,layer4接收layer3的输出计算出比layer3复杂的features,然后得到very interesting nonlinear hypotheses.
layer1是input layer,layer4是output layer,layer2和layer3是hidden layer,除了input layer和output layer之外的layer叫做hidden layer.
总结:
1,知道了什么叫做forward propagation(传播),从input layer到hidden layer再到output layer
2, 了解在计算中如何向量化来提高我们的计算效率
神经网络(4)---神经网络是如何帮助我们学习复杂的nonlinear hypotheses
标签:
原文地址:http://www.cnblogs.com/yan2015/p/4995278.html