标签:
摘要:
我们介绍Adam,这是一种基于一阶梯度来优化随机目标函数的算法。随即目标函数的含义是,在训练过程的每一次迭代中,目标函数是不一样的。有时候因为内存不够大或者其他的原因,算法不会一下子读取全部记录来计算误差,而是选择选择对数据集进行分割,在每次迭代中只读取一部分记录进行训练,这一部分记录称为minibatch,这样每次迭代所使用的小批量数据集就是不同的,数据集不同,损失函数就不同,因此就有随机目标函数的说法。另外还有一个原因就是,采用小批量方式来进行训练,可以降低收敛到局部最优的风险(想象一个在凹凸不平的地面上运动的小球,小球很容易陷入一些小坑,这些小坑并不是最低点)。
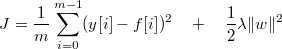
简介:
Adam 这个名字来源于 adaptive moment estimation,自适应矩估计。概率论中矩的含义是:如果一个随机变量 X 服从某个分布,X 的一阶矩是 E(X),也就是样本平均值,X 的二阶矩就是 E(X^2),也就是样本平方的平均值。Adam 算法根据损失函数对每个参数的梯度的一阶矩估计和二阶矩估计动态调整针对于每个参数的学习速率。Adam 也是基于梯度下降的方法,但是每次迭代参数的学习步长都有一个确定的范围,不会因为很大的梯度导致很大的学习步长,参数的值比较稳定。it does not require stationary objective, works with sparse gradients, naturally performs a form of step size annealing. 按我的理解,它有利于降低模型收敛到局部最优的风险。
下面是在实验室作报告的ppt,关于ADAM。












附录:
Dropout:
看看一个实验结果:
没用Dropout时:
训练样本错误率(均方误差):0.032355, 测试样本错误率:15.500%
使用Dropout时:
训练样本错误率(均方误差):0.075819, 测试样本错误率:13.000%
可以看出使用Dropout后,虽然训练样本的错误率较高,但是训练样本的错误率降低了,说明Dropout的泛化能力不错,可以防止过拟合[1]。droput的优势一般体现在样本比较少的情况下。
dropout方法是指每次迭代随机删除一些隐藏节点。并非真的删除,而是让这些节点的输出为0,相当于删除的效果。在前向传播的时候, 隐含层节点的输出值以某个百分比的几率被随机清0,同时在反向传播的时候,计算节点误差那一项时,其误差项也应该清0。dropoutFraction 常常设为0.5,表示删除大约一半的隐藏节点。它为什么有助于防止过拟合呢?可以简单地这样解释,运用了dropout的训练过程,相当于训练了很多个只有一部分隐层单元的较小规模的神经网络,不同的网络可以共享权值,每个网络都是一个分类器,都可以给出一个分类结果,这些结果有的是正确的,有的是错误的。随着训练的进行,大部分网络都可以给出正确的分类结果,那么把这些分类器叠加起来,少数错误的分类器就不会造成太大的影响,就可以取得一个更加可信的分类器。
数据集:

[1]http://www.cnblogs.com/tornadomeet/p/3258122.html
标签:
原文地址:http://www.cnblogs.com/xinchrome/p/4964930.html