标签:
拉格朗日乘子法(Lagrange Multiplier)和KKT(Karush-Kuhn-Tucker)条件是求解约束优化问题的重要方法,在有等式约束时使用拉格朗日乘子法,在有不等约束时使用KKT条件。前提是:只有当目标函数为凸函数时,使用这两种方法才保证求得的是最优解。
对于无约束最优化问题,有很多经典的求解方法,参见无约束最优化方法。
先来看拉格朗日乘子法是什么,再讲为什么。
$\min\;f(x)\\s.t.\;h_{i}(x)=0\;\;\;\;i=1,2...,n$
这个问题转换为
\begin{equation}min\;[f(x)+\sum_{i=1}^{n}\lambda_{i}h_{i}(x)]\label{lagrange}\end{equation}
其中$\lambda_{i}\ne{0}$,称为拉格朗日乘子。
下面看一下wikipedia上是如何解释拉格朗日乘子法的合理性的。
现有一个二维的优化问题:
$\min\;f(x,y)\\s.t.\;g(x,y)=c$
我们可以画图来辅助思考。
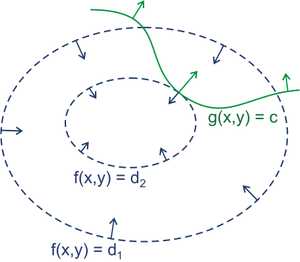
绿线标出的是约束$g(x,y)=c$的点的轨迹。蓝线是$f(x,y)$的等高线。箭头表示斜率,和等高线的法线平行。
从图上可以直观地看到在最优解处,f和g的斜率平行。
$\bigtriangledown[f(x,y)+\lambda(g(x,y)-1)]=0\;\;\;\;\lambda\ne{0}$
一旦求出$\lambda$的值,将其套入下式,易求在无约束极值和极值所对应的点。
$F(x,y)=f(x,y)+\lambda(g(x,y)-c)$
新方程$F(x,y)$在达到极值时与$f(x,y)$相等,因为$F(x,y)$达到极值时$g(x,y)-c$总等于零。
\eqref{lagrange}取得极小值时其导数为0,即$\bigtriangledown{f(x)}+\bigtriangledown{\sum_{i=1}^{n}\lambda_{i}h_{i}(x)}=0$,也就是说$f(x)$和$h(x)$的梯度共线。
先看KKT条件是什么,再讲为什么。
$\begin{equation}let\;L(x,\mu)=f(x)+\sum_{k=1}^q\mu_{k}g_{k}(x)\end{equation}$
其中$\mu_{k}\ge{0},g_{k}(x)\le{0}$
$\because \left.\begin{matrix}\mu_{k}\ge{0}\\g_{k}(x)\le{0}\end{matrix}\right\}$=>$\mu{g(x)}\le{0}$
$\therefore$ \begin{equation}\max_{\mu}L(x,\mu)=f(x)\label{a}\end{equation}
$\therefore$\begin{equation}\min_{x}f(x)=\min_{x}\max_{\mu}L(x,\mu)\label{firsthalf}\end{equation}
$\max_{\mu}\min_{x}L(x,\mu)=\max_{\mu}[\min_{x}f(x)+\min_{x}\mu{g(x)}]=\max_{\mu}\min_{x}f(x)+\max_{\mu}\min_{x}\mu{g(x)}=\min_{x}f(x)+\max_{\mu}\min_{x}\mu{g(x)}$
又$\because\left.\begin{matrix}\mu_{k}\ge{0}\\g_{k}(x)\le{0}\end{matrix}\right\}$=>$\min_{x}\mu{g(x)}=\left\{\begin{matrix}0 & if\;\mu=0\;or\;g(x)=0\\ -\infty & if\;\mu>0\;and\;g(x)<0\end{matrix}\right.$
$\therefore \max_{\mu}\min_{x}\mu{g(x)}=0$此时$\mu=0\;or\;g(x)=0$
\begin{equation}\therefore \max_{\mu}\min_{x}L(x,\mu)=\min_{x}f(x)+\max_{\mu}\min_{x}\mu{g(x)}=\min_{x}f(x)\label{secondhalf}\end{equation}此时$\mu=0\;or\;g(x)=0$
联合\eqref{firsthalf},\eqref{secondhalf}我们得到$\min_{x}\max_{\mu}L(x,\mu)=\max_{\mu}\min_{x}L(x,\mu)$
亦即$\left.\begin{matrix}L(x,\mu)=f(x)+\sum_{k=1}^q\mu_{k}g_{k}(x)\\\mu_{k}\ge{0}\\g_{k}(x)\le{0}\end{matrix}\right\}$=>$\min_{x}\max_{\mu}L(x,\mu)=\max_{\mu}\min_{x}L(x,\mu)=\min_{x}f(x)$
我们把$\max_{\mu}\min_{x}L(x,\mu)$称为原问题$\min_{x}\max_{\mu}L(x,\mu)$的对偶问题,上式表明当满足一定条件时原问题、对偶的解、以及$\min_{x}f(x)$是相同的,且在最优解$x^*$处$\mu=0\;or\;g(x^*)=0$。把$x^*$代入\eqref{a}得$\max_{\mu}L(x^*,\mu)=f(x^*)$,由\eqref{secondhalf}得$\max_{\mu}\min_{x}L(x,\mu)=f(x^*)$,所以$L(x^*,\mu)=\min_{x}L(x,\mu)$,这说明$x^*$也是$L(x,\mu)$的极值点,即$\frac{\partial{L(x,\mu)}}{\partial{x}}|_{x=x^*}=0$。
最后总结一下:
$\left.\begin{matrix}L(x,\mu)=f(x)+\sum_{k=1}^q\mu_{k}g_{k}(x)\\\mu_{k}\ge{0}\\g_{k}(x)\le{0}\end{matrix}\right\}$=>$\left\{\begin{matrix}\min_{x}\max_{\mu}L(x,\mu)=\max_{\mu}\min_{x}L(x,\mu)=\min_{x}f(x)=f(x^*)\\\mu_{k}{g_{k}(x^*)=0}\\\frac{\partial{L(x,\mu)}}{\partial{x}}|_{x=x^*}=0\end{matrix}\right.$
KKT条件是拉格朗日乘子法的泛化,如果我们把等式约束和不等式约束一并纳入进来则表现为:
$\left.\begin{matrix}L(x,\lambda,\mu)=f(x)+\sum_{i=1}^{n}\lambda_{i}h_{i}(x)+\sum_{k=1}^q\mu_{k}g_{k}(x)\\\lambda_{i}\ne{0}\\h_{i}(x)=0\\\mu_{k}\ge{0}\\g_{k}(x)\le{0}\end{matrix}\right\}$=>$\left\{\begin{matrix}\min_{x}\max_{\mu}L(x,\lambda,\mu)=\max_{\mu}\min_{x}L(x,\lambda,\mu)=\min_{x}f(x)=f(x^*)\\\mu_{k}{g_{k}(x^*)=0}\\\frac{\partial{L(x,\lambda,\mu)}}{\partial{x}}|_{x=x^*}=0\end{matrix}\right.$
注:$x,\lambda,\mu$都是向量。
$\frac{\partial{L(x,\lambda,\mu)}}{\partial{x}}|_{x=x^*}=0$表明$f(x)$在极值点$x^*$处的梯度是各个$h_{i}(x^*)$和$g_{k}(x^*)$梯度的线性组合。
转载 http://www.cnblogs.com/zhangchaoyang/articles/2726873.html
标签:
原文地址:http://www.cnblogs.com/chenying99/p/4999524.html