标签:
一、概念
1,ASCII
ASCII(American Standard Code for Information Interchange),中文名称为美国信息交换标准代码。是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统。ASCII码又分为标准ASCII码和扩展ASCII码。
- 标准ASCII码。标准ASCII 码也叫基础ASCII码,使用7 位二进制数来表示所有的大写和小写字母,数字0 到9、标点符号, 以及在美式英语中使用的特殊控制字符。其中0~31及127(共33个)是控制字符或通信专用字符(其余为可显示字符),如控制符:LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)、BEL(响铃)等;通信专用字符:SOH(文头)、EOT(文尾)、ACK(确认)等;ASCII值为8、9、10 和13 分别转换为退格、制表、换行和回车字符。它们并没有特定的图形显示,但会依不同的应用程序,而对文本显示有不同的影响。
32~126(共95个)是字符(32是空格),其中48~57为0到9十个阿拉伯数字。
65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。
同时还要注意,在标准ASCII中,其最高位(b7)用作奇偶校验位。
- 扩展ASCII码。扩展ASCII 字符是从128 到255(0x80-0xff)的字符。许多基于x86的系统都支持使用扩展(或“高”)ASCII。它将每个字符的第8 位用于确定附加的128 个特殊符号字符、外来语字母和图形符号。针对扩展的ASCII码,不同的国家有不同的字符集,所以它并不是国际标准。
ASCII字符表见附录。
2,Latin1
Latin1字符集属于扩展ASCII码的一种,它把位于128-255之间的字符用于拉丁字母表中特殊语言字符的编码,也因此而得名。不过欧洲语言不是地球上的唯一语言,亚洲和非洲语言并不能被Latine1字符集所支持。
Latin1字符表见附录。
3,UNICODE
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。
Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案,用数字0-0x10FFFF来映射这些字符,最多可以容纳1114112个字符,或者说有1114112个码位。码位就是可以分配给字符的数字,UTF-8,UTF-16,UTF-32都是将数字转换到程序数据的编码方案。
Unicode其实是Latin1的扩展。只有一个低字节的Uncode字符其实就是Latin1字符。所以Unicode字符集也兼容ASCII字符。
Unicode又分为两种。UCS-2(用两个字节编码)和UCS-4(用四个字节编码)。UCS是Universal Character Set的简称,也就是通用字符集。
4,UTF
UTF( Unicode Transformation Format )只是一种针对Unicode的编码方式,没有像Unicode那样存在字符与数字之间的对应关系。它的出现只是为了解决Unicode的不足。比如:
- 存储问题。事实证明,对可以用ASCII表示的字符使用UNICODE并不高效,因为Unicode比ASCII占用大一倍的空间,而对ASCII来说高字节的0对他毫无用处。UTF-8可以解决这个问题,因为它是一种变长字节的编码。比如0-127的Unicode字符(ASCII字符)转为UTF-8只需要一个字节。
- 传输问题。计算机分为大端机和小端机。Unicode用至少两个字节的整数来表示一个字符,这个整数在大端机和小端机上字节顺序是相反的,所以给传输带来了巨大的问题。UTF-8很好的解决了这个问题,因为它是字节顺序无关的,在所有机器上表示都一样(至于为什么一样看一下后面的转换关系就会一目了然)。不过UTF-16和UTF-32也有大小端的问题。这也是为什么UTF-8使用较为普遍的原因。
各种UTF编码与Unicode字符集之间转换关系见下文。
5,GB2312
《信息交换用汉字编码字符集》是由中国国家标准总局1980年发布,1981年5月1日开始实施的一套国家标准,标准号是GB2312—1980。GB就是拼音guobiao的简称。适用于汉字处理、汉字通信等系统之间的信息交换,通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB2312。基本集共收入汉字6763个和非汉字图形字符682个。
GB2312采用双字节编码。所有字符集分成94个区,每区有94个位。每个区位上只有一个字符,因此可用所在的区和位来对汉字进行编码,称为区位码。把十六进制的区位码加上0x2020,就得到国标码。国标码加上0x8080,就得到常用的计算机机内码。所以区位码加上0xA0A0就得到了计算机内码。什么是计算机内码呢,通俗的将就是存储字符时在内存里面的整数。下面举个例子。
汉字“啊”是GB2312字符集中的第一个汉字,它的区位码为0x1001。如下图:

0x1001加上0xA0A0就是0xB0A1,这就是“啊”的计算机内码。所以下面这段C程序将输出0xB0A1。
- <span style="font-size:14px;">char* p = "啊";
- printf("0x%X%X", unsigned char(p[0]), unsigned char(p[1]));
- </span>
GB2312字符集见附录。
6,GBK
GBK全称是《汉字内码扩展规范》,K应该是Kuo的首字母。它是1995年12月1日制订的,从时间上来看比GB2312晚了15年。为什么要制定这个字符集呢?大家很容易想到。GB2312有很多空余的位根本没有被使用,表示的汉子也只有区区6763个,这明显不足。
GBK共收录了21003个汉字,完全兼容GB2312字符。比如“啊”在GBK中的编码还是0xB0A1。而且GBK不像B2312那样存在区位码与内码的区分。它的字符编码和在内码是相同的。
GBK是如何兼容GB2312的呢?相信大家很容易理解。还是以“啊”为例。它在GB2312中的内码是0xB0A1,把它直接填到GBK编码表中的相应位置即可。
目前中文版的WIN95、WIN98、WINDOWS NT以及WINDOWS 2000、WINDOWS XP、WIN 7等都支持GBK编码方案。
GBK汉字字符集见附录。
7,GB18030
GB18030有两个版本:GB18030-2000和GB18030-2005。GB18030-2000是GBK的取代版本,它的主要特点是在GBK基础上增加了CJK统一汉字扩充A的汉字。GB18030-2005的主要特点是在GB18030-2000基础上增加了CJK统一汉字扩充B的汉字。所以GB18030也是向上兼容GB2312和GBK的。它我国继GB2312-1980和GB13000-1993之后最重要的汉字编码标准,是我国计算机系统必须遵循的基础性标准之一。
8,BIG-5
BIG-5码是通行于台湾,香港地区的一个繁体字编码方案,俗称“大五码”。地区标准号为:CNS11643。共收录13,060个中文字,其中有二字为重覆编码。它并非当地的国家标准,而只是业界标准。
二、转换规则
根据上面的概念大家可以知道:Latin1是对ASCII的扩展,Unicode又是对Latin1的扩展。GBK是对GB2312的扩展,GB18030又是对GBK的扩展。BIG-5并非国家标准。而UTF是Unicode的编码方式,所以这里只介绍Unicode同UTF及Unicode同GB2312的转换。
1,Unicode转UTF
1.1,Unicode转UTF-8
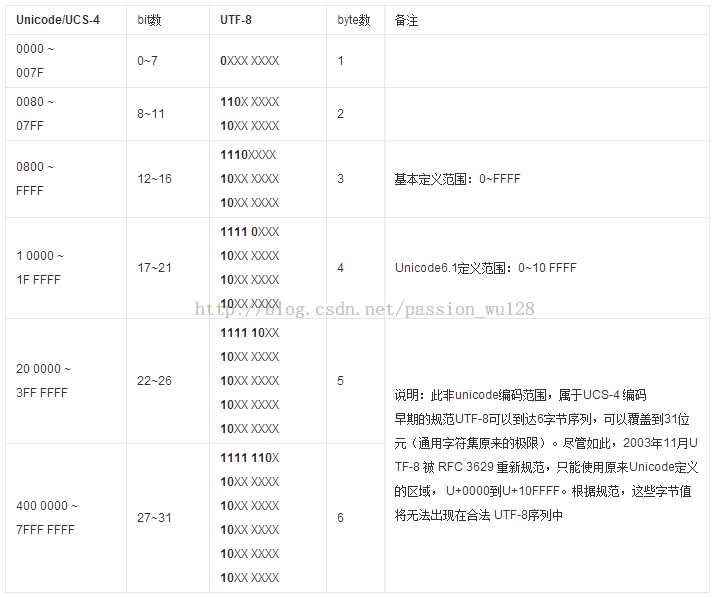
根据Unicode值范围,编码UTF-8需要的字节数在1到6之间。Unicode转换为UTF-8需要的字节数可以这样计算:如果Unicode小于0x80(ASCII字符),则转换后为1个字节。否则转换后的字节数为Unicode二进制位数加3再除以5。对应关系如下:
从上图中大家可以看出:单字节的编码以0开始。多字节的编码高字节都是1...0开始(多少个1就表示多少个字节),而低字节都是10开始。这是为了区分UTF-8编码和其它编码。详细的转换规则是:
小于0x80的Unicode字符直接对应单字节的UTF-8编码。大于0x80的Unicode字符转换时每次将其二进制位从低往高取出二进制位,每次取6位。最后不足位数时用0填充。
比如汉字“啊”的Unicode编码为0x554a。二进制表示为:101 010101 001010。共有15个二进制位,编码UTF-8需要3个字节。
3字节的UTF-8二进制格式为:1110XXXX 10XXXXXX 10XXXXXX。001010填入最低字节,010101填入中间字节,101填入最高字节。最后的UTF-8编码即为:11100101 10010101 10001010,十六进制值为0xE5958A。
1.2,Unicode转UTF-16
UTF-16同Unicode一样,也有大端序列和小端序列的区别。
两个字节的Unicode字符将编码两个字节UTF-16,而且编码值是相同的。
超过两个字节的Unicode字符将编码4个字节的UTF-16,但并不是简单的将Unicode分为高两个字节和低两个字节。具体转换关系参考维基百科对UTF-16的解释。
1.3, Unicode转换为UTF-32
UTF-32同Unicode一样,也有大端序列和小端序列的区别。Unicode的UTF-32编码就是其对应的32位无符号整数,不需要转换。
Windows提供的API WideCharToMultiByte 可以将Unicode转换为UTF编码,不过它的参数中只提供了同UTF-7及UTF-8的转化。而且wchat_t是两个字节的,超过0xFFFF的Unicode字符这个函数也无能为力。
2,Unicode转GB18030
Unicode是国际组织制定的,而GB18030是中国制定的,这两个编码毫无关系,要转换只能一个个字符查表。
WideCharToMultiByte 同样可以将Unicode转换为GB18030编码。我不清楚这个函数的具体实现,我猜是查表吧,不然效率会很低。
Unicode字符同GBK汉字的转换见附录。
三、附录
各种字符编码表及转换表:http://pan.baidu.com/s/1c0laJVq
Unicode其实是Latin1的扩展。只有一个低字节的Uncode字符其实就是Latin1字符——附各种字符编码表及转换表
标签:
原文地址:http://www.cnblogs.com/findumars/p/5006175.html