标签:
File->new->Project,如下图 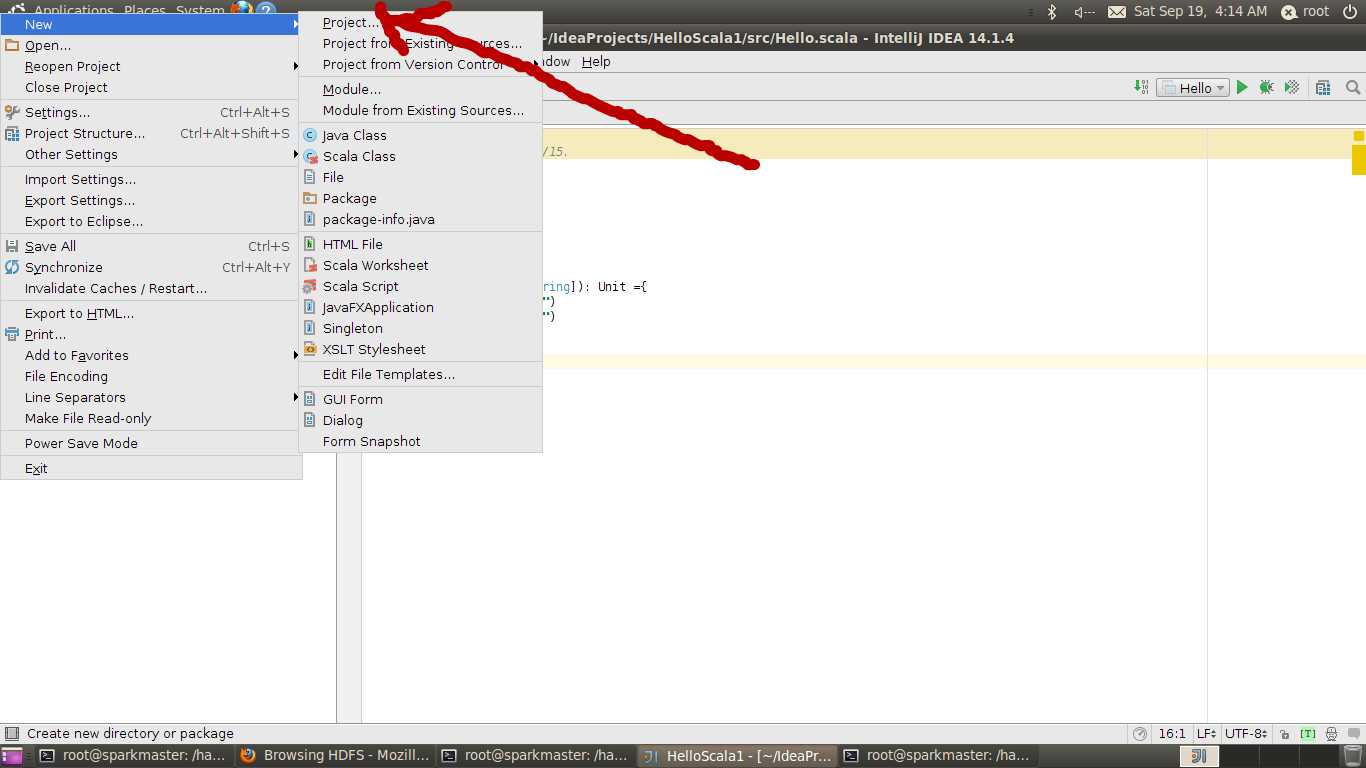
选择Scala 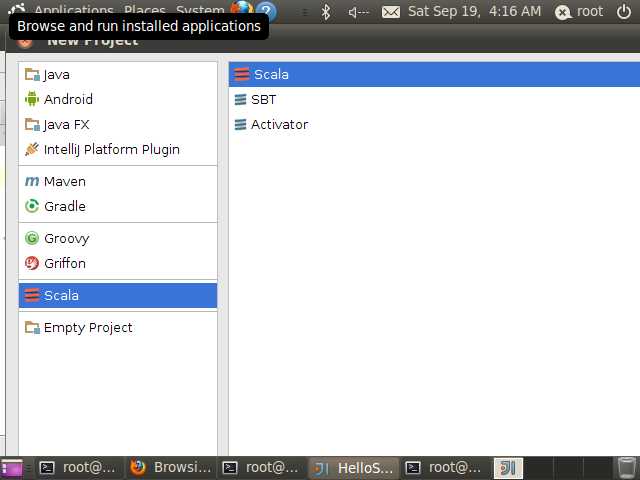
然后next 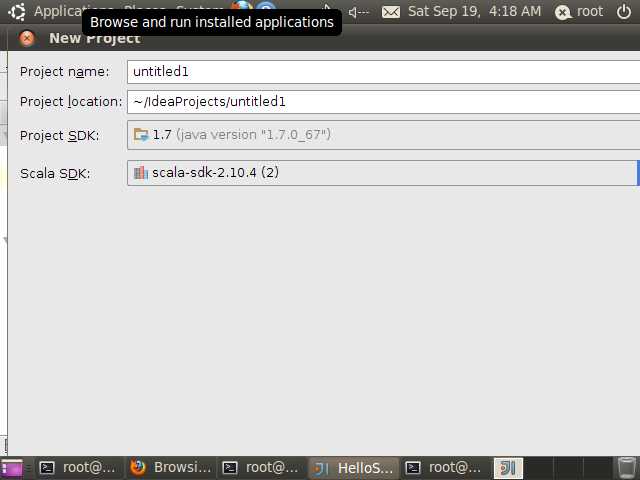
其中Project SDK指定安装的JDK,Scala SDK指定安装的Scala(这里使用的是IDEA自带的scala SDK),这里将项目名称命令为SparkWordCount,然后finish 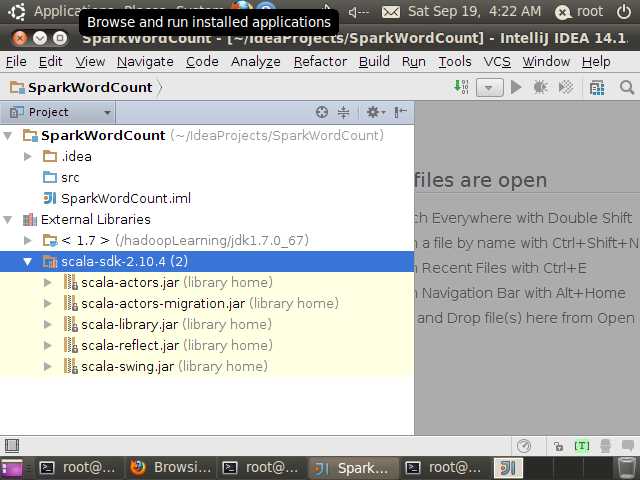
在IDEA中开发应用程序时,常常需要通过一定的文件目录组织进行源码编写,例如源文件目录、测试源文件目录,下面演示在Intellij IDEA的src目录下创建main/scala源文件目录。
直接按F4或右鍵点击工程文件 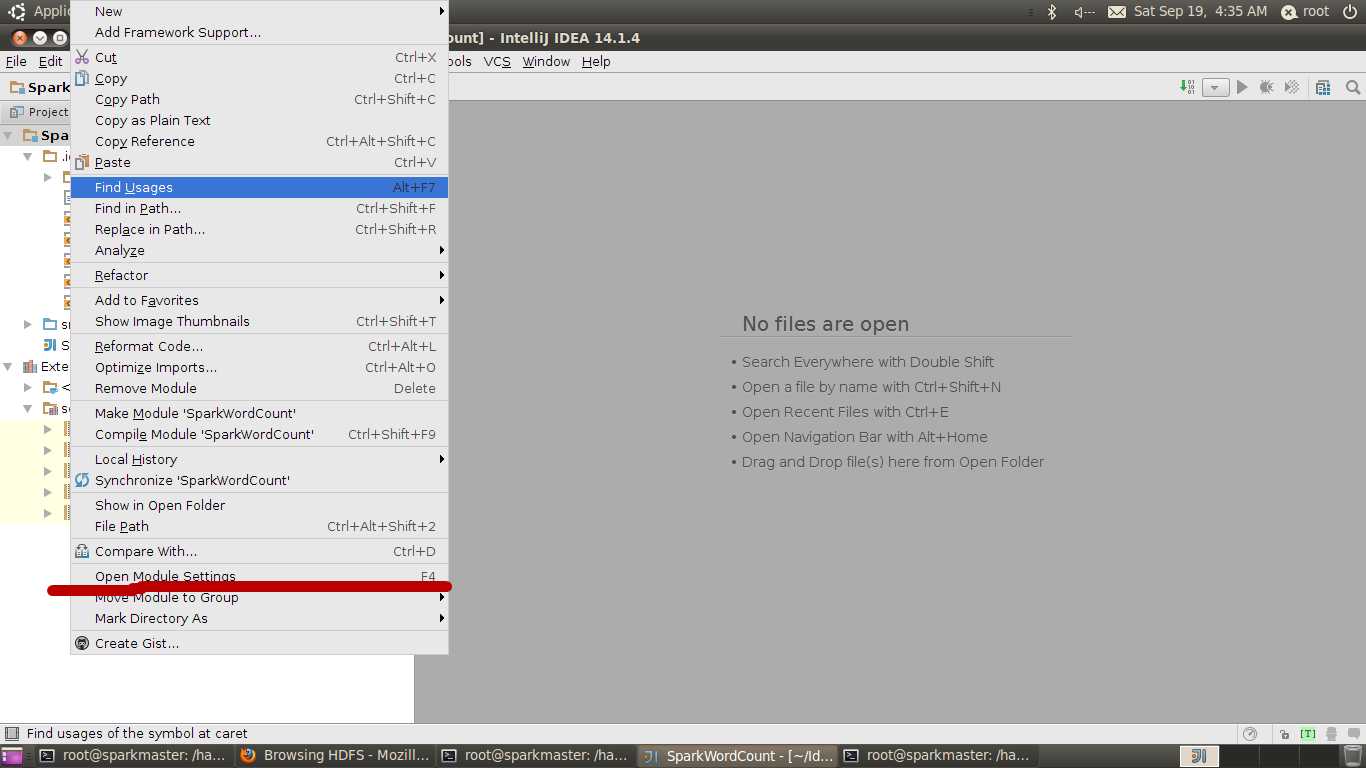
再选择open module setting,打开项目配置,点击src目录,然后右键创建main/scala文件夹,再点击scala文件夹为sources,如下图所示 
### (2)导入Spark 1.5.0依赖包
直接F4打开Project Structure,然后选择libraries 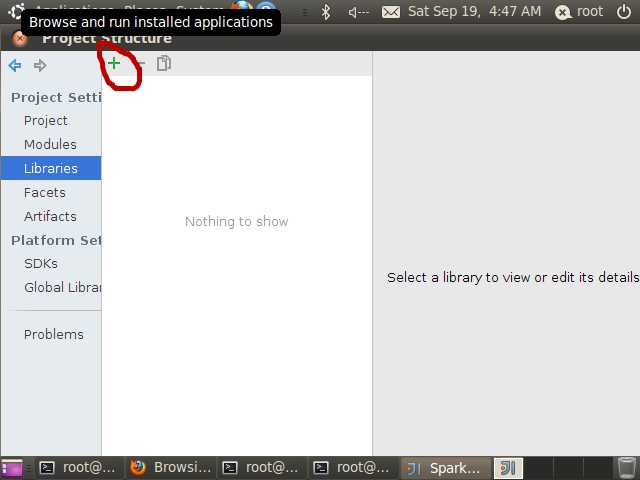
点击上图中的+添加外部依赖包,选择”java”,然后再选择spark-assembly-1.5.0-hadoop2.4.0.jar 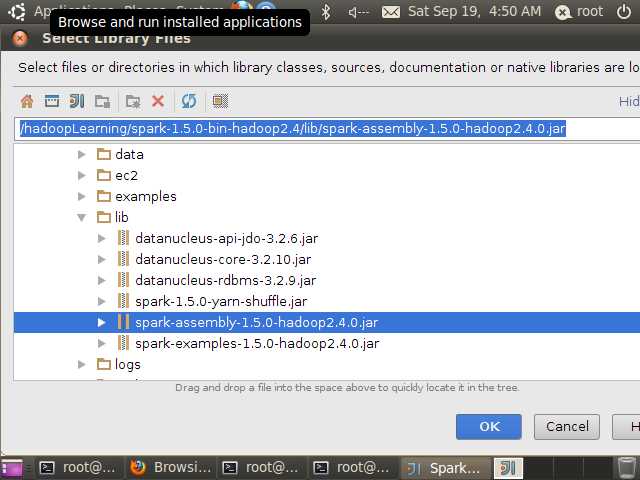
成功后如下图 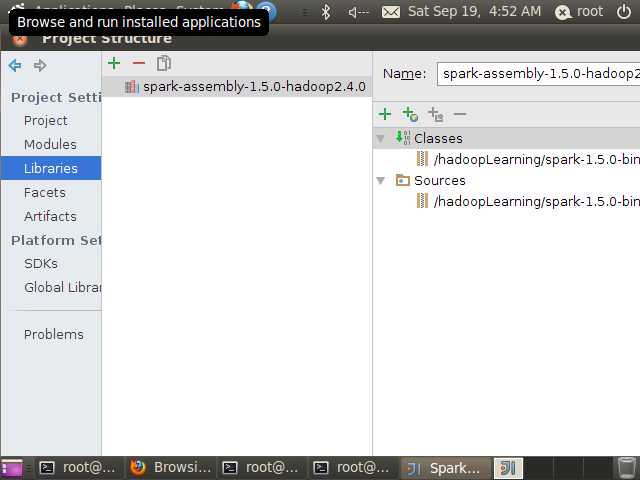
至此Spark开发环境配置完成
在src/main/scala源文件目录中创建一个SparkWordCount 应用程序对象,编辑内容如下:
import org.apache.spark.SparkContext._ import org.apache.spark.{SparkConf, SparkContext} object SparkWordCount{ def main(args: Array[String]) { //输入文件既可以是本地linux系统文件,也可以是其它来源文件,例如HDFS if (args.length == 0) { System.err.println("Usage: SparkWordCount <inputfile>") System.exit(1) } //以本地线程方式运行,可以指定线程个数, //如.setMaster("local[2]"),两个线程执行 //下面给出的是单线程执行 val conf = new SparkConf().setAppName("SparkWordCount").setMaster("local") val sc = new SparkContext(conf) //wordcount操作,计算文件中包含Spark的行数 val count=sc.textFile(args(0)).filter(line => line.contains("Spark")).count() //打印结果 println("count="+count) sc.stop() } }
编译代码,直接Build->Make Project 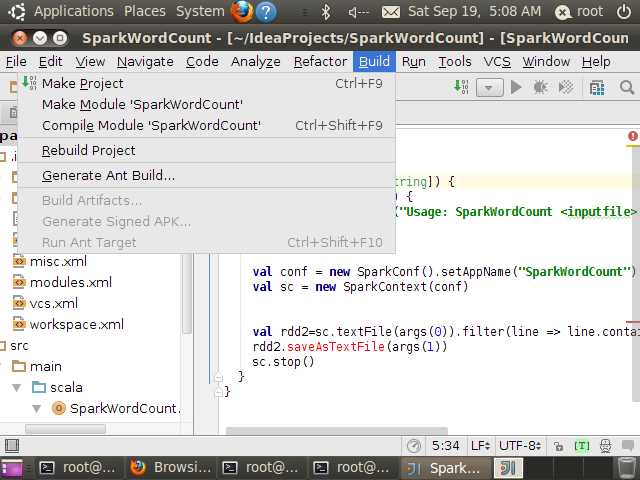
然后编程运行参数,Run->Edit Configurations 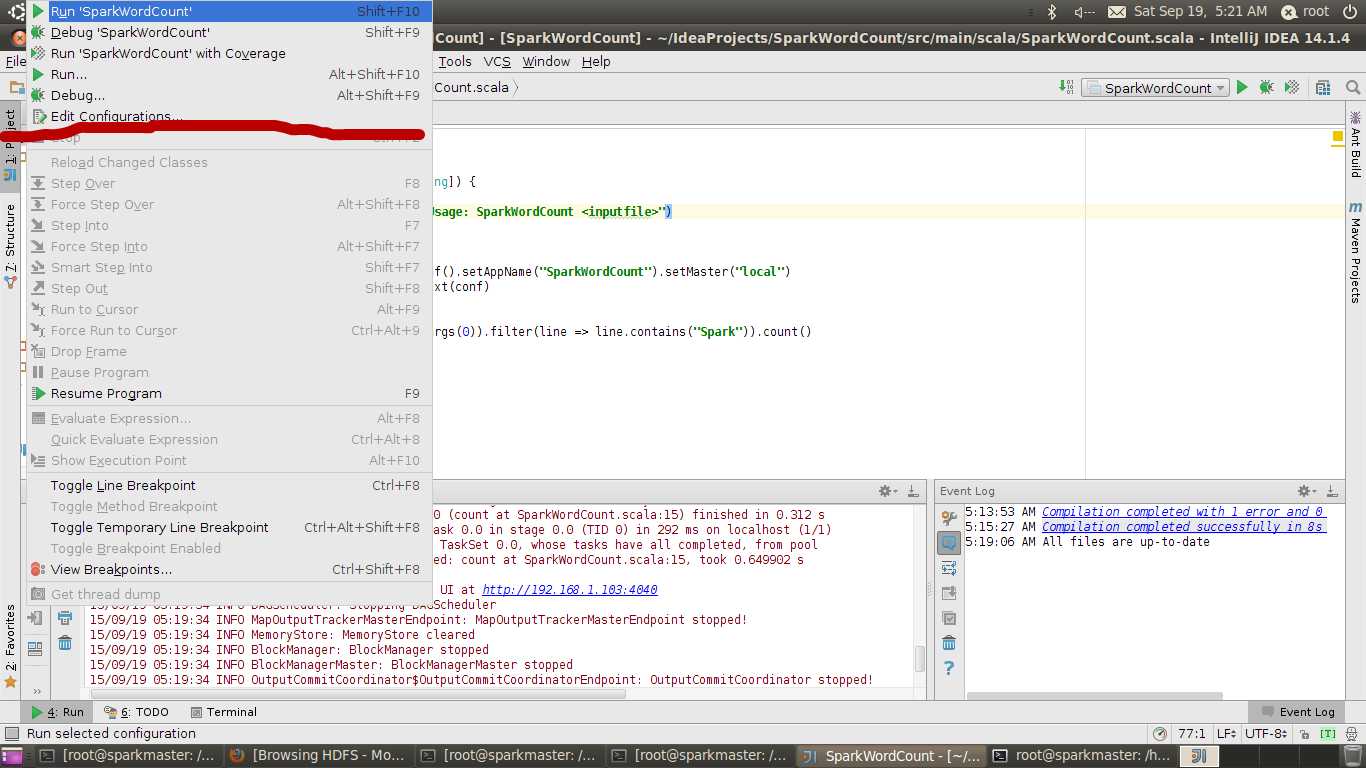
Main Class输入:SparkWordCount
Program arguments输入:/hadoopLearning/spark-1.5.0-bin-hadoop2.4/README.md
如下图: 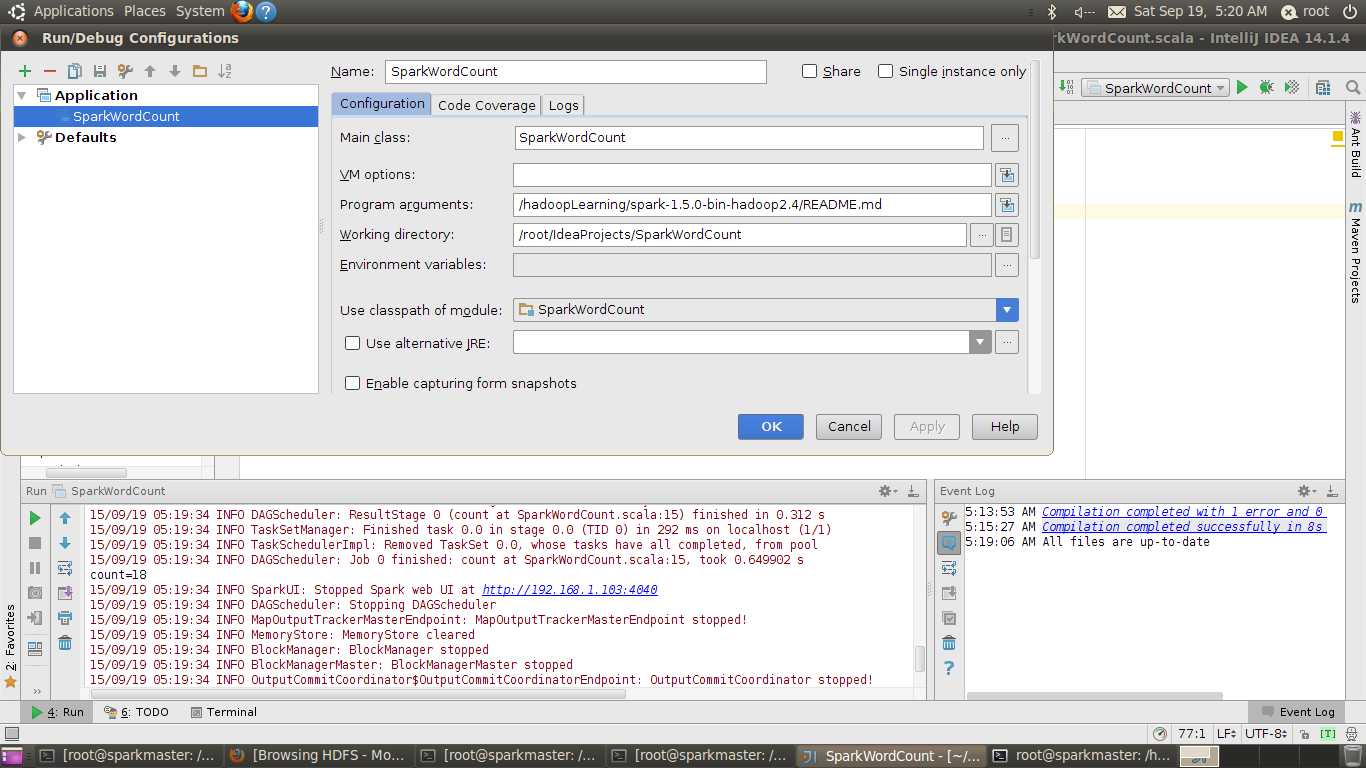
完成后直接Run->Run或Alt+Shift+F10运行程序,执行结果如下图: 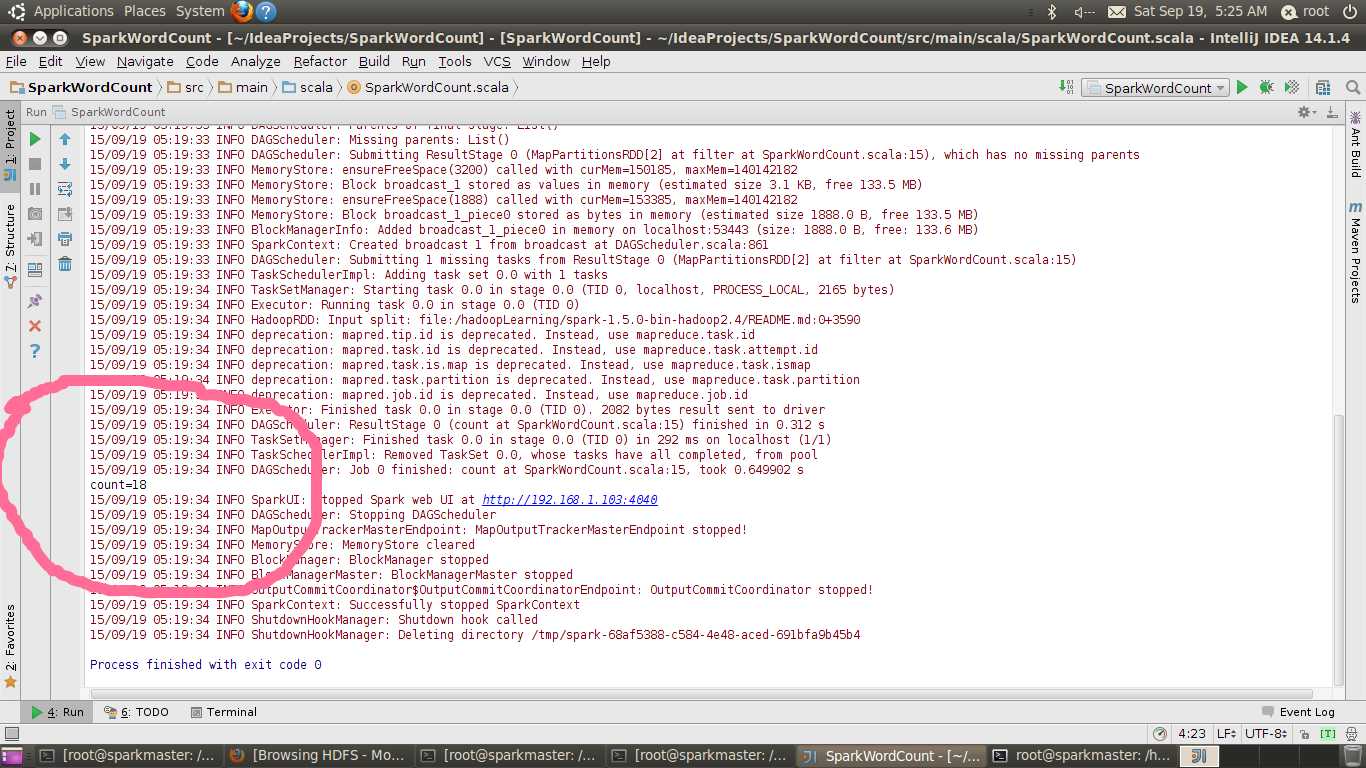
将程序内容修改如下:
import org.apache.spark.SparkContext._
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount{
def main(args: Array[String]) {
//输入文件既可以是本地linux系统文件,也可以是其它来源文件,例如HDFS
if (args.length == 0) {
System.err.println("Usage: SparkWordCount <inputfile> <outputfile>")
System.exit(1)
}
//提交集群时,本地线程不起作用
val conf = new SparkConf().setAppName("SparkWordCount").setMaster("local")
val sc = new SparkContext(conf)
//rdd2为所有包含Spark的行
val rdd2=sc.textFile(args(0)).filter(line => line.contains("Spark"))
//保存内容,在例子中是保存在HDFS上
rdd2.saveAsTextFile(args(1))
sc.stop()
}
}点击工程SparkWordCount,然后按F4打个Project Structure并选择Artifacts,如下图 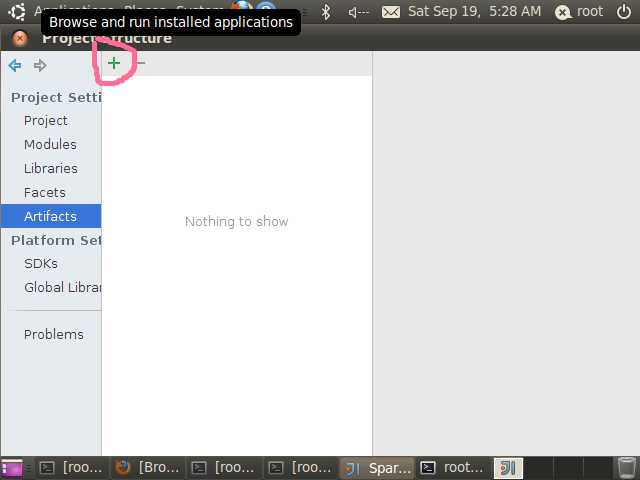
选择Jar->form modules with dependencies,如下图 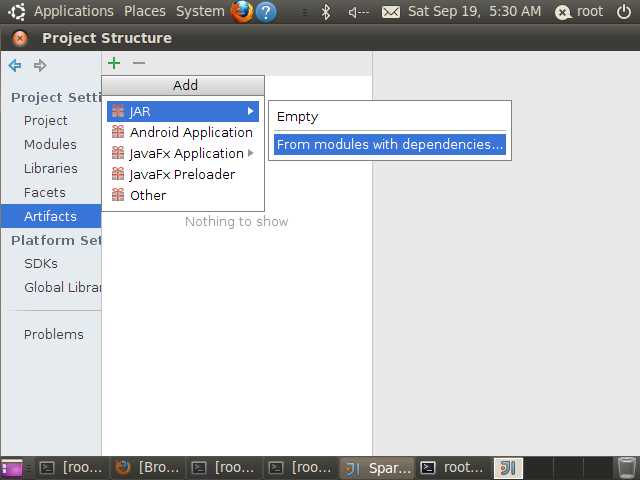
进入下面的界面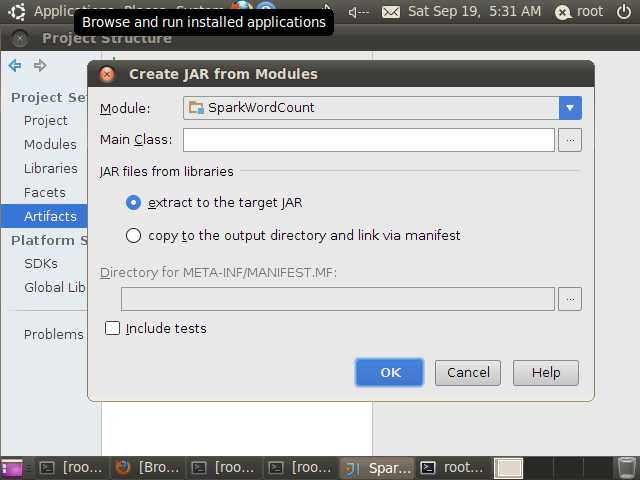
在main class中,选择SparkWordCount,如下图 
点击确定后得到如下界面 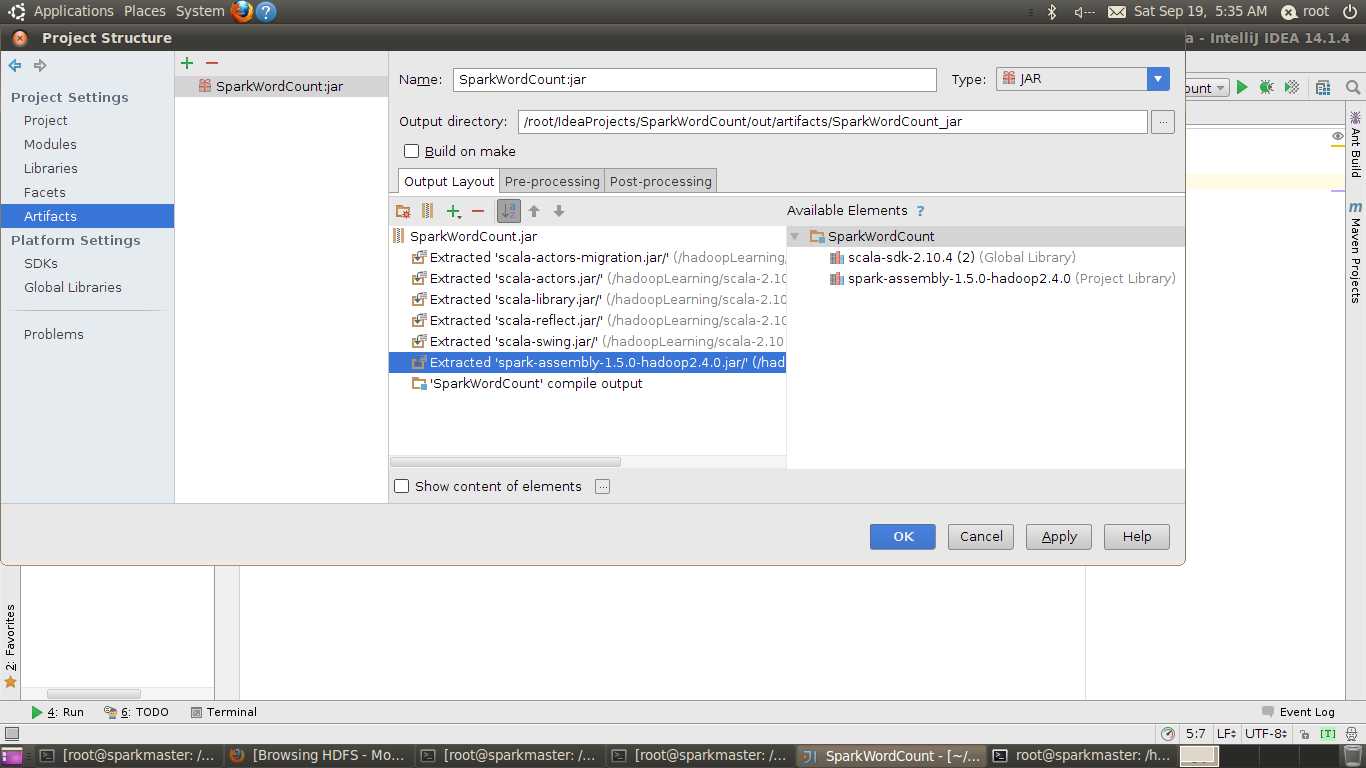
因为后期提交到集群上运行,因此相关jar包都存在,为减小jar包的体积,将spark-assembly-1.5.0-hadoop2.4.0.jar等jar包删除即可,如下图 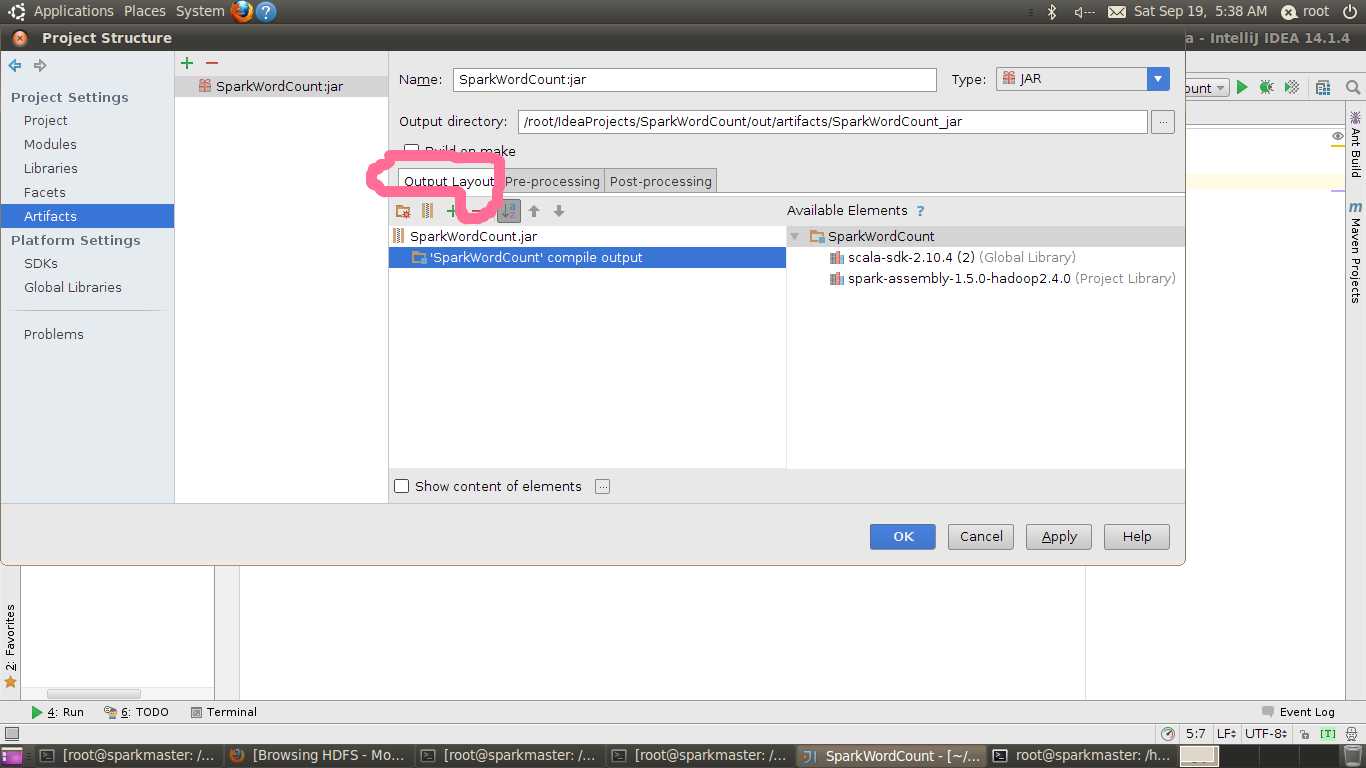
确定后,再点击Build->Build Artifacts 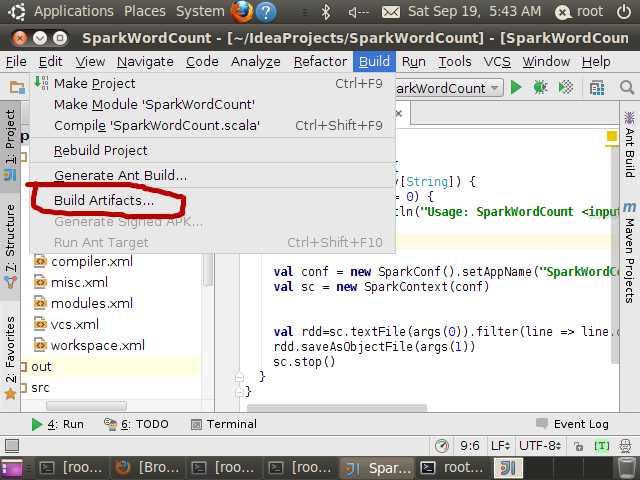
生成后的jar文件保存在root@sparkmaster:~/IdeaProjects/SparkWordCount/out/artifacts/SparkWordCount_jar# 目录中,如下图: 
./spark-submit --master spark://sparkmaster:7077 --class SparkWordCount --executor-memory 1g /root/IdeaProjects/SparkWordCount/out/artifacts/SparkWordCount_jar/SparkWordCount.jar hdfs://ns1/README.md hdfs://ns1/SparkWordCountResult
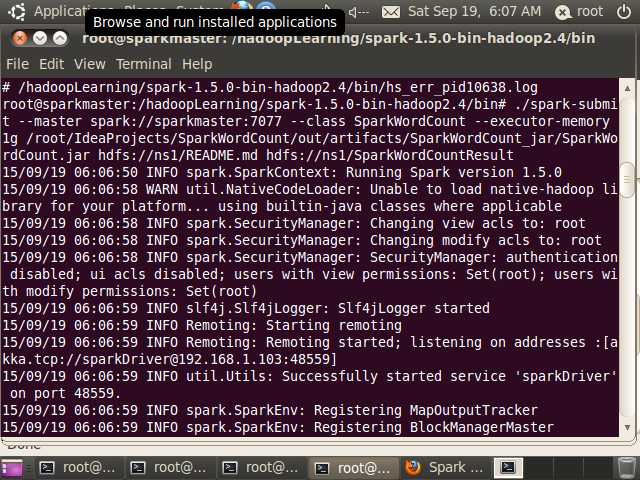
执行结果: 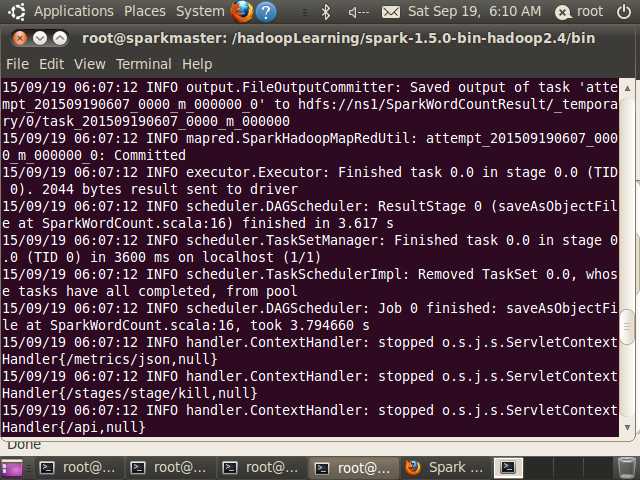
HDFS文件已经生成了SparkWordCountResult 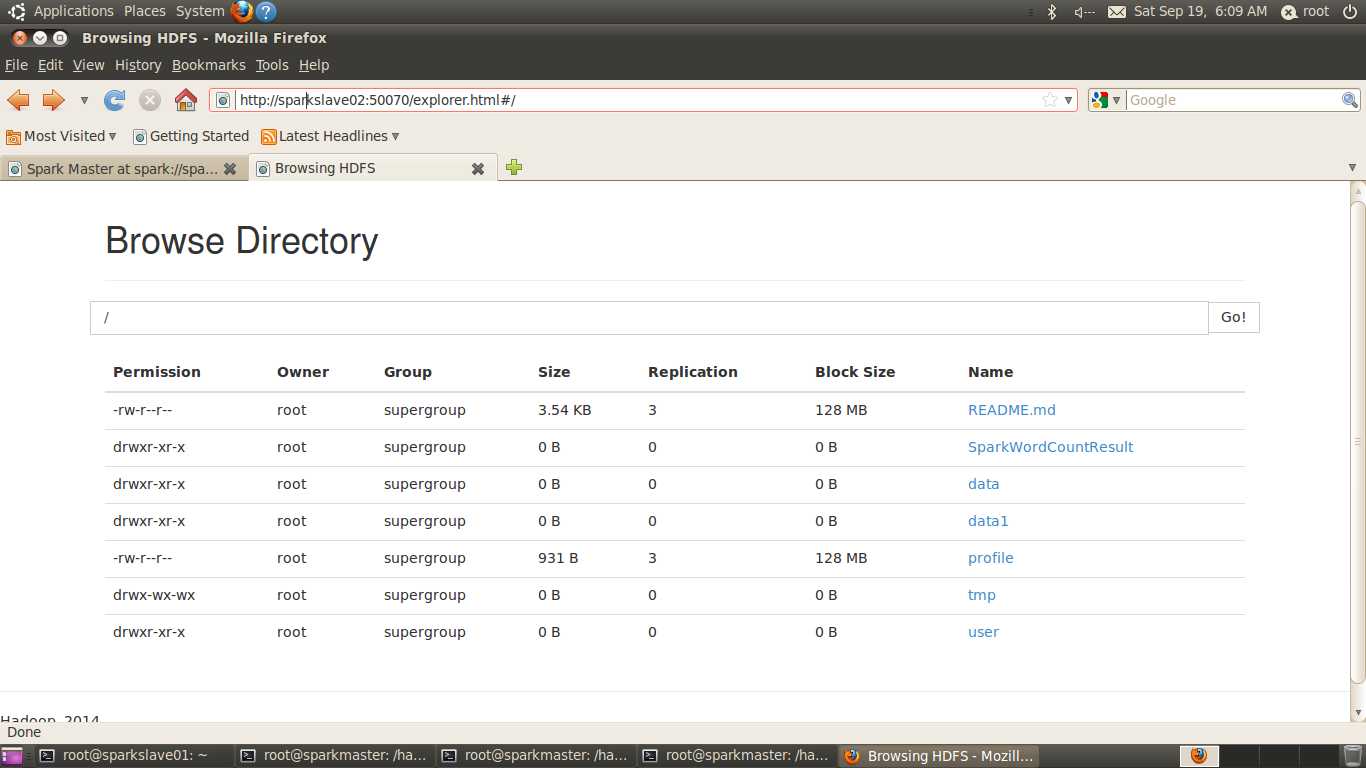
使用
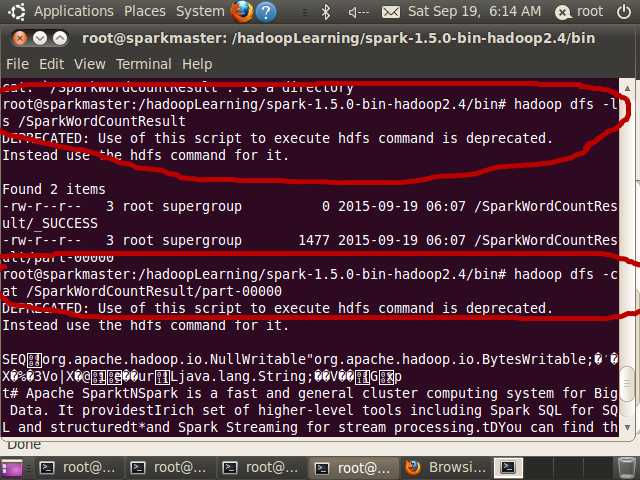
root@sparkmaster:/hadoopLearning/spark-1.5.0-bin-hadoop2.4/bin# hadoop dfs -ls
/SparkWordCountResult
root@sparkmaster:/hadoopLearning/spark-1.5.0-bin-hadoop2.4/bin# hadoop dfs -cat
/SparkWordCountResult/part-00000
查看目录内容,具体结果如下图所示:
标签:
原文地址:http://www.cnblogs.com/zhoudayang/p/5007770.html