标签:
主要为第十周内容:大规模机器学习、案例、总结
(一)随机梯度下降法
如果有一个大规模的训练集,普通的批量梯度下降法需要计算整个训练集的误差的平方和,如果学习方法需要迭代20次,这已经是非常大的计算代价。
首先,需要确定大规模的训练集是否有必要。当我们确实需要一个大规模的训练集,可以尝试用随机梯度下降法来替代批量梯度下降法。
在随机梯度下降法中,定义代价函数一个单一训练实例的代价:
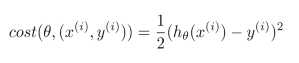
随机梯度下降算法如下:
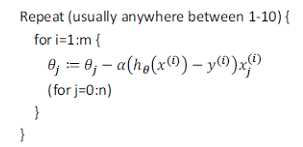
随机梯度下降算法在每一次计算之后便更新参数Θ,而不需要首先将所有的训练集求和,在梯度下降算法还没有完成一次迭代时,随机梯度下降算法便已经走出了很远。但是这样的算法存在的问题是,不是每一步都是朝着"正确"的方向迈出的。因此算法虽然会逐渐走向全局最小值的位置,但是可能无法站到那个最小值的那一点,而是在最小值点附近徘徊。
微型批量梯度下降算法是介于批量梯度下降算法和随机梯度下降算法之间的算法,每计算常数b次训练实例,变更新一次Θ。
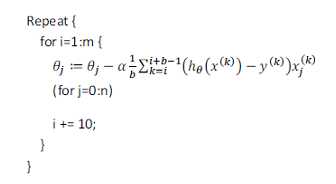
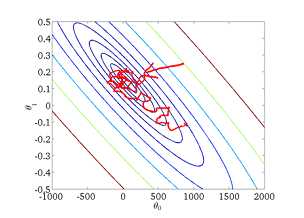
在批量梯度下降中,我们可以令代价函数 J 为迭代次数的函数,绘制图表,根据图表来判断梯度下降是否收敛。 但是,在大规模的训练集的情况下,这是不现实的,因为计算代价太大了。在随机梯度下降中,我们在每一次更新Θ之前都计算一次代价,然后每 X 次迭代后,求出这 X次对训练实例计算代价的平均值,然后绘制这些平均值与 X 次迭代的次数之间的函数图表。
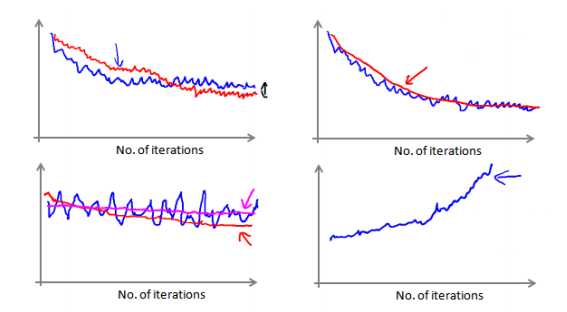
当我们绘制这样的图表时,可能会得到一个颠簸不平但是不会明显减少的函数图像(如上面左下图中蓝线所示)。我们可以增加 X 来使得函数更加平缓,也许便能看出下降的趋势了(如上面左下图中红线所示);或者可能函数图表仍然是颠簸不平且不下降的(如洋红色线所示),那么我们的模型本身可能存在一些错误。如果我们得到的曲线如上面右下方所示,不断地上升,那么我们可能会需要选择一个较小的学习率 α。
也可以令学习率随着迭代次数的增加而减小,如

但是通常我们不需要这样做便能有非常好的效果了,对α进行调整所耗费的计算通常不值得。
(二)在线学习
在线学习算法指的是对数据流而非离线的静态数据集的学习。许多在线网站都有持续不断的用户流,对于每一个用户,网站希望能在不将数据存储到数据库中便顺利地进行算法学习。

一旦对该数据完成学习算法,我们便丢弃该数据,不再存储它。
在线学习算法的好处在于,我们的算法可以很好的适应用户的倾向性,算法可以针对用户的当前行为不断地更新模型以适应该用户。
Map Reduce和数据并行
批量梯度下降算法来求解大规模数据集的最优解=需要对整个训练集进行循环,计算其偏导数和代价,再求和,计算代价非常大。将整个数据集计算的工作分配到几台计算机中,让每一台计算机处理数据集的一部分,然后将计算结果汇总求和。这就是Map Reduce。

详细的Map Reduce 可以继续学习 Hadoop和Spark
(三)上限分析
在机器学习应用中,通常血药几个步骤才能进行最终的预测,哪个步骤最值得花时间和精力去改善呢?这就是上限分析的用武之地。
在一个文字识别应用中,分为以下步骤:

在上限分析中,对于该步骤和应用之前部分,手工提供100%的输出结果,看应用 最终效果提升了多少。
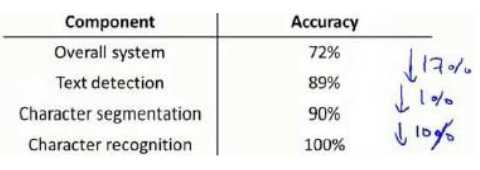
由上图可见,文字侦测(Character Segmentation)步骤值得投入时间和精力。
标签:
原文地址:http://www.cnblogs.com/findwg/p/5008498.html