标签:
1、项目名称:
2、程序代码:
package com.averagescorecount; import java.io.IOException; import java.util.Iterator; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class ScoreCount { /*这个map的输入是经过InputFormat分解过的数据集,InputFormat的默认值是TextInputFormat,它针对文件, *按行将文本切割成InputSplits,并用LineRecordReader将InputSplit解析成<key,value>对, *key是行在文本中的位置,value是文件中的一行。 */ public static class Map extends Mapper<LongWritable, Text, Text , IntWritable>{ public void map(LongWritable key , Text value , Context context ) throws IOException, InterruptedException{ String line = value.toString(); System.out.println("line:"+line); System.out.println("TokenizerMapper.map..."); System.out.println("Map key:"+key.toString()+" Map value:"+value.toString()); //将输入的数据首先按行进行分割 StringTokenizer tokenizerArticle = new StringTokenizer(line,"\n"); //分别对每一行进行处理 while (tokenizerArticle.hasMoreTokens()) { //每行按空格划分 StringTokenizer tokenizerLine = new StringTokenizer(tokenizerArticle.nextToken()); String strName = tokenizerLine.nextToken();//学生姓名部分 String strScore= tokenizerLine.nextToken();//成绩部分 Text name = new Text(strName); int scoreInt = Integer.parseInt(strScore); System.out.println("name:"+name+" scoreInt:"+scoreInt); context.write(name, new IntWritable(scoreInt)); System.out.println("context_map:"+context.toString()); } System.out.println("context_map_111:"+context.toString()); } } public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable>{ public void reduce(Text key , Iterable<IntWritable> values,Context context) throws IOException,InterruptedException{ int sum = 0; int count = 0; int score = 0; System.out.println("reducer..."); System.out.println("Reducer key:"+key.toString()+" Reducer values:"+values.toString()); //设置迭代器 Iterator<IntWritable> iterator = values.iterator(); while (iterator.hasNext()) { score = iterator.next().get(); System.out.println("score:"+score); sum += score; count++; } int average = (int) sum/count; System.out.println("key"+key+" average:"+average); context.write(key, new IntWritable(average)); System.out.println("context_reducer:"+context.toString()); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = new Job(conf, "score count"); job.setJarByClass(ScoreCount.class); job.setMapperClass(Map.class); job.setCombinerClass(Reduce.class); job.setReducerClass(Reduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
4、运行过程:
14/09/20 19:31:16 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
14/09/20 19:31:16 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
14/09/20 19:31:16 WARN mapred.JobClient: No job jar file set. User classes may not be found. See JobConf(Class) or JobConf#setJar(String).
14/09/20 19:31:16 INFO input.FileInputFormat: Total input paths to process : 1
14/09/20 19:31:16 WARN snappy.LoadSnappy: Snappy native library not loaded
14/09/20 19:31:16 INFO mapred.JobClient: Running job: job_local_0001
14/09/20 19:31:16 INFO util.ProcessTree: setsid exited with exit code 0
14/09/20 19:31:16 INFO mapred.Task: Using ResourceCalculatorPlugin : org.apache.hadoop.util.LinuxResourceCalculatorPlugin@4080b02f
14/09/20 19:31:16 INFO mapred.MapTask: io.sort.mb = 100
14/09/20 19:31:16 INFO mapred.MapTask: data buffer = 79691776/99614720
14/09/20 19:31:16 INFO mapred.MapTask: record buffer = 262144/327680
line:陈洲立 67
TokenizerMapper.map...
Map key:0 Map value:陈洲立 67
name:陈洲立 scoreInt:67
context_map:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
context_map_111:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
line:陈东伟 90
TokenizerMapper.map...
Map key:13 Map value:陈东伟 90
name:陈东伟 scoreInt:90
context_map:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
context_map_111:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
line:李宁 87
TokenizerMapper.map...
Map key:26 Map value:李宁 87
name:李宁 scoreInt:87
context_map:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
context_map_111:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
line:杨森 86
TokenizerMapper.map...
Map key:36 Map value:杨森 86
name:杨森 scoreInt:86
context_map:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
context_map_111:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
line:陈东奇 78
TokenizerMapper.map...
Map key:46 Map value:陈东奇 78
name:陈东奇 scoreInt:78
context_map:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
context_map_111:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
line:谭果 94
TokenizerMapper.map...
Map key:59 Map value:谭果 94
name:谭果 scoreInt:94
context_map:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
context_map_111:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
line:盖盖 83
TokenizerMapper.map...
Map key:69 Map value:盖盖 83
name:盖盖 scoreInt:83
context_map:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
context_map_111:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
line:陈洲立 68
TokenizerMapper.map...
Map key:79 Map value:陈洲立 68
name:陈洲立 scoreInt:68
context_map:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
context_map_111:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
line:陈东伟 96
TokenizerMapper.map...
Map key:92 Map value:陈东伟 96
name:陈东伟 scoreInt:96
context_map:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
context_map_111:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
line:李宁 82
TokenizerMapper.map...
Map key:105 Map value:李宁 82
name:李宁 scoreInt:82
context_map:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
context_map_111:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
line:杨森 85
TokenizerMapper.map...
Map key:115 Map value:杨森 85
name:杨森 scoreInt:85
context_map:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
context_map_111:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
line:陈东奇 72
TokenizerMapper.map...
Map key:125 Map value:陈东奇 72
name:陈东奇 scoreInt:72
context_map:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
context_map_111:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
line:谭果 97
TokenizerMapper.map...
Map key:138 Map value:谭果 97
name:谭果 scoreInt:97
context_map:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
context_map_111:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
line:盖盖 82
TokenizerMapper.map...
Map key:148 Map value:盖盖 82
name:盖盖 scoreInt:82
context_map:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
context_map_111:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
line:陈洲立 46
TokenizerMapper.map...
Map key:158 Map value:陈洲立 46
name:陈洲立 scoreInt:46
context_map:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
context_map_111:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
line:陈东伟 48
TokenizerMapper.map...
Map key:171 Map value:陈东伟 48
name:陈东伟 scoreInt:48
context_map:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
context_map_111:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
line:李宁 67
TokenizerMapper.map...
Map key:184 Map value:李宁 67
name:李宁 scoreInt:67
context_map:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
context_map_111:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
line:杨森 33
TokenizerMapper.map...
Map key:194 Map value:杨森 33
name:杨森 scoreInt:33
context_map:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
context_map_111:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
line:陈东奇 28
TokenizerMapper.map...
Map key:204 Map value:陈东奇 28
name:陈东奇 scoreInt:28
context_map:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
context_map_111:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
line:谭果 78
TokenizerMapper.map...
Map key:217 Map value:谭果 78
name:谭果 scoreInt:78
context_map:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
context_map_111:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
line:盖盖 87
TokenizerMapper.map...
Map key:227 Map value:盖盖 87
name:盖盖 scoreInt:87
context_map:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
context_map_111:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
line:
TokenizerMapper.map...
Map key:237 Map value:
context_map_111:org.apache.hadoop.mapreduce.Mapper$Context@d4cf771
14/09/20 19:31:16 INFO mapred.MapTask: Starting flush of map output
reducer...
Reducer key:李宁 Reducer values:org.apache.hadoop.mapreduce.ReduceContext$ValueIterable@63dbbdf2
score:82
score:87
score:67
key李宁 average:78
context_reducer:org.apache.hadoop.mapreduce.Reducer$Context@3d32487
reducer...
Reducer key:杨森 Reducer values:org.apache.hadoop.mapreduce.ReduceContext$ValueIterable@63dbbdf2
score:33
score:86
score:85
key杨森 average:68
context_reducer:org.apache.hadoop.mapreduce.Reducer$Context@3d32487
reducer...
Reducer key:盖盖 Reducer values:org.apache.hadoop.mapreduce.ReduceContext$ValueIterable@63dbbdf2
score:87
score:83
score:82
key盖盖 average:84
context_reducer:org.apache.hadoop.mapreduce.Reducer$Context@3d32487
reducer...
Reducer key:谭果 Reducer values:org.apache.hadoop.mapreduce.ReduceContext$ValueIterable@63dbbdf2
score:94
score:97
score:78
key谭果 average:89
context_reducer:org.apache.hadoop.mapreduce.Reducer$Context@3d32487
reducer...
Reducer key:陈东伟 Reducer values:org.apache.hadoop.mapreduce.ReduceContext$ValueIterable@63dbbdf2
score:48
score:90
score:96
key陈东伟 average:78
context_reducer:org.apache.hadoop.mapreduce.Reducer$Context@3d32487
reducer...
Reducer key:陈东奇 Reducer values:org.apache.hadoop.mapreduce.ReduceContext$ValueIterable@63dbbdf2
score:72
score:78
score:28
key陈东奇 average:59
context_reducer:org.apache.hadoop.mapreduce.Reducer$Context@3d32487
reducer...
Reducer key:陈洲立 Reducer values:org.apache.hadoop.mapreduce.ReduceContext$ValueIterable@63dbbdf2
score:68
score:67
score:46
key陈洲立 average:60
context_reducer:org.apache.hadoop.mapreduce.Reducer$Context@3d32487
14/09/20 19:31:16 INFO mapred.MapTask: Finished spill 0
14/09/20 19:31:16 INFO mapred.Task: Task:attempt_local_0001_m_000000_0 is done. And is in the process of commiting
14/09/20 19:31:17 INFO mapred.JobClient: map 0% reduce 0%
14/09/20 19:31:19 INFO mapred.LocalJobRunner:
14/09/20 19:31:19 INFO mapred.Task: Task ‘attempt_local_0001_m_000000_0‘ done.
14/09/20 19:31:19 INFO mapred.Task: Using ResourceCalculatorPlugin : org.apache.hadoop.util.LinuxResourceCalculatorPlugin@5fc24d33
14/09/20 19:31:19 INFO mapred.LocalJobRunner:
14/09/20 19:31:19 INFO mapred.Merger: Merging 1 sorted segments
14/09/20 19:31:19 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 102 bytes
14/09/20 19:31:19 INFO mapred.LocalJobRunner:
reducer...
Reducer key:李宁 Reducer values:org.apache.hadoop.mapreduce.ReduceContext$ValueIterable@2407325d
score:78
key李宁 average:78
context_reducer:org.apache.hadoop.mapreduce.Reducer$Context@52403ee2
reducer...
Reducer key:杨森 Reducer values:org.apache.hadoop.mapreduce.ReduceContext$ValueIterable@2407325d
score:68
key杨森 average:68
context_reducer:org.apache.hadoop.mapreduce.Reducer$Context@52403ee2
reducer...
Reducer key:盖盖 Reducer values:org.apache.hadoop.mapreduce.ReduceContext$ValueIterable@2407325d
score:84
key盖盖 average:84
context_reducer:org.apache.hadoop.mapreduce.Reducer$Context@52403ee2
reducer...
Reducer key:谭果 Reducer values:org.apache.hadoop.mapreduce.ReduceContext$ValueIterable@2407325d
score:89
key谭果 average:89
context_reducer:org.apache.hadoop.mapreduce.Reducer$Context@52403ee2
reducer...
Reducer key:陈东伟 Reducer values:org.apache.hadoop.mapreduce.ReduceContext$ValueIterable@2407325d
score:78
key陈东伟 average:78
context_reducer:org.apache.hadoop.mapreduce.Reducer$Context@52403ee2
reducer...
Reducer key:陈东奇 Reducer values:org.apache.hadoop.mapreduce.ReduceContext$ValueIterable@2407325d
score:59
key陈东奇 average:59
context_reducer:org.apache.hadoop.mapreduce.Reducer$Context@52403ee2
reducer...
Reducer key:陈洲立 Reducer values:org.apache.hadoop.mapreduce.ReduceContext$ValueIterable@2407325d
score:60
key陈洲立 average:60
context_reducer:org.apache.hadoop.mapreduce.Reducer$Context@52403ee2
14/09/20 19:31:19 INFO mapred.Task: Task:attempt_local_0001_r_000000_0 is done. And is in the process of commiting
14/09/20 19:31:19 INFO mapred.LocalJobRunner:
14/09/20 19:31:19 INFO mapred.Task: Task attempt_local_0001_r_000000_0 is allowed to commit now
14/09/20 19:31:19 INFO output.FileOutputCommitter: Saved output of task ‘attempt_local_0001_r_000000_0‘ to hdfs://localhost:9000/user/hadoop/score_output
14/09/20 19:31:20 INFO mapred.JobClient: map 100% reduce 0%
14/09/20 19:31:22 INFO mapred.LocalJobRunner: reduce > reduce
14/09/20 19:31:22 INFO mapred.Task: Task ‘attempt_local_0001_r_000000_0‘ done.
14/09/20 19:31:23 INFO mapred.JobClient: map 100% reduce 100%
14/09/20 19:31:23 INFO mapred.JobClient: Job complete: job_local_0001
14/09/20 19:31:23 INFO mapred.JobClient: Counters: 22
14/09/20 19:31:23 INFO mapred.JobClient: Map-Reduce Framework
14/09/20 19:31:23 INFO mapred.JobClient: Spilled Records=14
14/09/20 19:31:23 INFO mapred.JobClient: Map output materialized bytes=106
14/09/20 19:31:23 INFO mapred.JobClient: Reduce input records=7
14/09/20 19:31:23 INFO mapred.JobClient: Virtual memory (bytes) snapshot=0
14/09/20 19:31:23 INFO mapred.JobClient: Map input records=22
14/09/20 19:31:23 INFO mapred.JobClient: SPLIT_RAW_BYTES=116
14/09/20 19:31:23 INFO mapred.JobClient: Map output bytes=258
14/09/20 19:31:23 INFO mapred.JobClient: Reduce shuffle bytes=0
14/09/20 19:31:23 INFO mapred.JobClient: Physical memory (bytes) snapshot=0
14/09/20 19:31:23 INFO mapred.JobClient: Reduce input groups=7
14/09/20 19:31:23 INFO mapred.JobClient: Combine output records=7
14/09/20 19:31:23 INFO mapred.JobClient: Reduce output records=7
14/09/20 19:31:23 INFO mapred.JobClient: Map output records=21
14/09/20 19:31:23 INFO mapred.JobClient: Combine input records=21
14/09/20 19:31:23 INFO mapred.JobClient: CPU time spent (ms)=0
14/09/20 19:31:23 INFO mapred.JobClient: Total committed heap usage (bytes)=408944640
14/09/20 19:31:23 INFO mapred.JobClient: File Input Format Counters
14/09/20 19:31:23 INFO mapred.JobClient: Bytes Read=238
14/09/20 19:31:23 INFO mapred.JobClient: FileSystemCounters
14/09/20 19:31:23 INFO mapred.JobClient: HDFS_BYTES_READ=476
14/09/20 19:31:23 INFO mapred.JobClient: FILE_BYTES_WRITTEN=81132
14/09/20 19:31:23 INFO mapred.JobClient: FILE_BYTES_READ=448
14/09/20 19:31:23 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=79
14/09/20 19:31:23 INFO mapred.JobClient: File Output Format Counters
14/09/20 19:31:23 INFO mapred.JobClient: Bytes Written=79
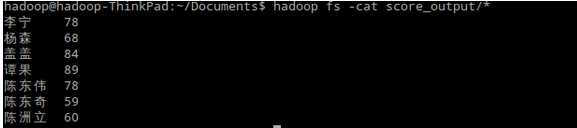
5、输出结果:
标签:
原文地址:http://www.cnblogs.com/yangyquin/p/5021157.html