标签:
PageRank,网页排名,又称网页级别、Google左侧排名或佩奇排名,是一种由搜索引擎根据网页之间相互的超链接计算的技术,而作为网页排名的要素之一,以Google公司创办人拉里·佩奇(Larry Page)之姓来命名。Google用它来体现网页的相关性和重要性,在搜索引擎优化操作中是经常被用来评估网页优化的成效因素之一。
PageRank通过网络浩瀚的超链接关系来确定一个页面的等级。Google把从A页面到B页面的链接解释为A页面给B页面投票,Google根据投票来源(甚至来源的来源,即链接到A页面的页面)和投票目标的等级来决定新的等级。简单的说,一个高等级的页面可以使其他低等级页面的等级提升。
一个页面的“得票数”由所有链向它的页面的重要性来决定,到一个页面的超链接相当于对该页投一票。一个页面的PageRank是由所有链向它的页面(“链入页面”)的重要性经过递归算法得到的。一个有较多链入的页面会有较高的等级,相反如果一个页面没有任何链入页面,那么它没有等级。
2005年初,Google为网页链接推出一项新属性nofollow,使得网站管理员和网志作者可以做出一些Google不计票的链接,也就是说这些链接不算作“投票”。nofollow的设置可以抵制垃圾评论。
Google工具条上的PageRank指标从0到10。它似乎是一个对数标度算法,细节未知。虽然PageRank是Google的商标,其技术亦已经申请专利,但是专利权属于斯坦福大学,而非Google。
PageRank算法中的点击算法是由Jon Kleinberg提出的。
假设一个由4个页面组成的小团体:A,B,C和D。如果所有页面都链向A,那么A的PR(PageRank)值将是B,C及D的Pagerank总和。

继续假设B也有链接到C,并且D也有链接到包括A的3个页面。一个页面不能投票2次。所以B给每个页面半票。以同样的逻辑,D投出的票只有三分之一算到了A的PageRank上。
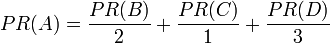
换句话说,根据链出总数平分一个页面的PR值。
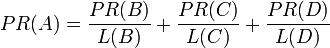
最后,所有这些被换算为一个百分比再乘上一个系数 。由于“没有向外链接的页面”传递出去的PageRank会是0,所以,Google通过数学系统给了每个页面一个最小值
。由于“没有向外链接的页面”传递出去的PageRank会是0,所以,Google通过数学系统给了每个页面一个最小值 :
:
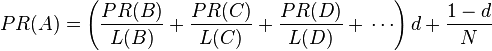
说明:在Sergey Brin和Lawrence Page的1998年原文中给每一个页面设定的最小值是 ,而不是这里的(关于这一部分内容也可以参考英文版的维基百科词条)。 所以一个页面的PageRank是由其他页面的PageRank计算得到。Google不断的重复计算每个页面的PageRank。如果给每个页面一个随机PageRank值(非0),那么经过不断的重复计算,这些页面的PR值会趋向于稳定,也就是收敛的状态。这就是搜索引擎使用它的原因。
,而不是这里的(关于这一部分内容也可以参考英文版的维基百科词条)。 所以一个页面的PageRank是由其他页面的PageRank计算得到。Google不断的重复计算每个页面的PageRank。如果给每个页面一个随机PageRank值(非0),那么经过不断的重复计算,这些页面的PR值会趋向于稳定,也就是收敛的状态。这就是搜索引擎使用它的原因。
这个方程式引入了随机浏览的概念,即有人上网无聊随机打开一些页面,点一些链接。一个页面的PageRank值也影响了它被随机浏览的概率。为了便于理解,这里假设上网者不断点网页上的链接,最终到了一个没有任何链出页面的网页,这时候上网者会随机到另外的网页开始浏览。
为了处理那些“没有向外链接的页面”(这些页面就像“黑洞”会吞噬掉用户继续向下浏览的概率)带来的问题,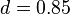 (这里的被称为阻尼系数(damping factor),其意义是,在任意时刻,用户到达某页面后并继续向后浏览的概率,该数值是根据上网者使用浏览器书签的平均频率估算而得。
(这里的被称为阻尼系数(damping factor),其意义是,在任意时刻,用户到达某页面后并继续向后浏览的概率,该数值是根据上网者使用浏览器书签的平均频率估算而得。 (就是用户停止点击,随机跳到新URL的概率)的算法被用到了所有页面上。
(就是用户停止点击,随机跳到新URL的概率)的算法被用到了所有页面上。
所以,这个等式如下:

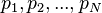 是被研究的页面,
是被研究的页面,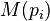 是链入
是链入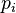 页面的集合,
页面的集合, 是
是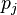 链出页面的数量,而
链出页面的数量,而 是所有页面的数量。
是所有页面的数量。
PageRank值是一个特殊矩阵中的特征向量。这个特征向量为

R是等式的答案
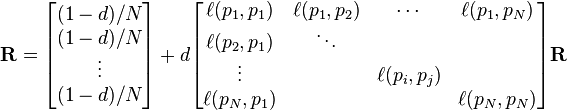
如果不链向,而且对每个 都成立时,
都成立时,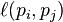 等于0
等于0
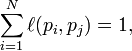
这项技术的主要缺点是旧的页面等级会比新页面高。因为即使是非常好的新页面也不会有很多外链,除非它是某个站点的子站点。
这就是PageRank需要多项算法结合的原因。PageRank似乎偏好于维基百科页面,在条目名称的搜索结果中,维基百科页面总在大多数或者其他所有页面之前。原因主要是维基百科内相互的链接很多,并且有很多站点链入。
Google经常处罚恶意提高PageRank的行为,至于其如何区分正常的链接和不正常的链接仍然是个商业机密。但是在Google的链接规范中,已经很清楚地说明,哪些做法是属于违反指南的行为。
用mapreduce实现pagerank算法
主要依据公式
没有对其他算法的结合,其中d=0.85。
•在具体企业应用中怎么样确定收敛标准?
–1、每个页面的PR值和上一次计算的PR相等
–2、设定一个差值指标(0.0001)。当所有页面和上一次计算的PR差值平均小于该标准时,则收敛。
–3、设定一个百分比(99%),当99%的页面和上一次计算的PR相等
package com.mr.pagerank; import java.io.IOException; import java.util.Arrays; import org.apache.commons.lang.StringUtils; public class Node { private double pageRank=1.0; private String[] adjacentNodeNames; public static final char fieldSeparator = ‘\t‘; public double getPageRank() { return pageRank; } public Node setPageRank(double pageRank) { this.pageRank = pageRank; return this; } public String[] getAdjacentNodeNames() { return adjacentNodeNames; } public Node setAdjacentNodeNames(String[] adjacentNodeNames) { this.adjacentNodeNames = adjacentNodeNames; return this; } public boolean containsAdjacentNodes() { return adjacentNodeNames != null && adjacentNodeNames.length>0; } @Override public String toString() { StringBuilder sb = new StringBuilder(); sb.append(pageRank); if (getAdjacentNodeNames() != null) { sb.append(fieldSeparator) .append(StringUtils .join(getAdjacentNodeNames(), fieldSeparator)); } return sb.toString(); } //value =1.0 B D public static Node fromMR(String value) throws IOException { String[] parts = StringUtils.splitPreserveAllTokens( value, fieldSeparator); if (parts.length < 1) { throw new IOException( "Expected 1 or more parts but received " + parts.length); } Node node = new Node() .setPageRank(Double.valueOf(parts[0])); if (parts.length > 1) { node.setAdjacentNodeNames(Arrays.copyOfRange(parts, 1, parts.length)); } return node; } }
package com.mr.pagerank; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class PageRunJob { public static enum Counter { ABC } /** * * @param args */ public static void main(String[] args) { try{ Configuration config =new Configuration(); config.set("fs.defaultFS", "hdfs://node4:8020"); config.set("yarn.resourcemanager.hostname", "node1"); config.setInt("pageCount", 4); FileSystem fs =FileSystem.get(config); Path firstInPath=new Path("/usr/input/pagerank.txt"); double d =0.0001; int i =0; while(true){ i++; Path outpath =new Path("/usr/output/pr"+i); Path inpath =new Path("/usr/output/pr"+(i-1)); if(i==1){ inpath=firstInPath; } config.setInt("run_num", i); double result =iter(config, fs, i, inpath, outpath); if(result < d){ System.out.println(result+"#######################"); break; } } System.out.println(i+"**********************"); }catch (Exception e){ e.printStackTrace(); } } public static double iter(Configuration config,FileSystem fs,int i,Path inpath,Path outpath)throws Exception{ Job job =Job.getInstance(config); job.setJobName("fof"+i); job.setMapperClass(PageRankMapper.class); job.setReducerClass(PageRankReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); //mapreduce 输入文件 FileInputFormat.setInputPaths(job, inpath); job.setInputFormatClass(KeyValueTextInputFormat.class); //设置mapreduce的输出文件目录,该目录不能存在,自动创建 if(fs.exists(outpath)){ fs.delete(outpath, true); } FileOutputFormat.setOutputPath(job, outpath); boolean f= job.waitForCompletion(true); if(f){ long sumabc= job.getCounters().findCounter(Counter.ABC).getValue(); System.out.println(sumabc +"@@@@@@@@@@@@@@@@"); double avg_abc= sumabc/10000.0/4; return avg_abc; } job=null; return 0; } //读取原数据 static class PageRankMapper extends Mapper<Text, Text, Text, Text>{ protected void map(Text key, Text value, Context context) throws IOException, InterruptedException { int run_num =context.getConfiguration().getInt("run_num", 1); String v =value.toString(); Node page =null; if(run_num==1){ page =Node.fromMR("1.0"+"\t"+v); }else{ page =Node.fromMR(v); } context.write(key, new Text(page.toString()));//每个页面的初始值输出 A 1.0 B D if(page.containsAdjacentNodes()){ String pages[] =page.getAdjacentNodeNames(); double outValue= page.getPageRank()/Double.valueOf(page.getAdjacentNodeNames().length+""); for (int i = 0; i < pages.length; i++) { String apage = pages[i]; Node anode =new Node(); anode.setPageRank(outValue); context.write(new Text(apage), new Text(anode.toString())); // B 0.5 } } } } static class PageRankReducer extends Reducer<Text, Text, Text, Text>{ static int pagecount =0; //reduce任务启动,只会调用一次setup protected void setup(Context context) throws IOException, InterruptedException { pagecount =context.getConfiguration().getInt("pageCount", 4); } protected void reduce(Text key, Iterable<Text> arg1, Context arg2) throws IOException, InterruptedException { double sum =0; double oldpagerank=0; Node sourceNode =null; for( Text i :arg1 ){ Node node =Node.fromMR(i.toString()); if(node.containsAdjacentNodes()){ sourceNode =node; oldpagerank=node.getPageRank(); // sum=sum+oldpagerank; }else{ sum=sum+node.getPageRank(); } } double newpagerank =sum*0.85+(0.15/pagecount); sourceNode.setPageRank(newpagerank); double abc =Math.abs(newpagerank-oldpagerank); int l_abc=(int) (abc*10000); arg2.getCounter(Counter.ABC).increment(l_abc); arg2.write(key, new Text(sourceNode.toString())); } } //计算页面总数,自己去执行 static class FirstMapper extends Mapper<Text, Text, Text, LongWritable>{ protected void map(Text key, Text value, Context context) throws IOException, InterruptedException { context.write(new Text("pagecount"), new LongWritable(1)); } } static class FirstReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ protected void reduce(Text arg0, Iterable<LongWritable> arg1, Context arg2) throws IOException, InterruptedException { long sum=0; for(LongWritable i:arg1){ sum=sum+i.get(); } arg2.write(arg0, new LongWritable(sum)); } } }
标签:
原文地址:http://www.cnblogs.com/Nervermore/p/5023658.html