标签:
这篇主要来讨论下下面这个问题的解法:
无序的整数序列,找出其中值,或者第 K 小的元素!
思考一会,可能这是最快想到的解法,先对数组排序一趟,然后直接取出第k小的元素。这个算法最低的时间复杂度为 O(nlog(n))。 那有没有更加快的算法呢? 先来简单分析下上面这个算法,显然是多做了无用功。因为只要找到第k小的元素,即只要把第k小的位置上的元素找对就可以。而该方法把所有的元素都放在了正确的位置上,这显示是多做了无用功。那么这个问题肯定也是存在更优的解法的。
沿着 “将正确的元素放置到第k小的位置上” 这个思路,注意到 “位置” 这个关键词,是可以联想到在 排序算法 中讲到的一个随机划分的算法的,即任何一个元素通过对数组一次遍历操作都可以将其放置到正确的位置上。似乎看到了希望,那我们就使用这个子算法呗。当随机划分子算法的返回值恰好等于k时,我们就找对了元素,如果不相等时,那么就是用递归继续往下找,因为有一部分元素里面肯定是不会再存在我们想找的元素了!下面是算法的示意图:
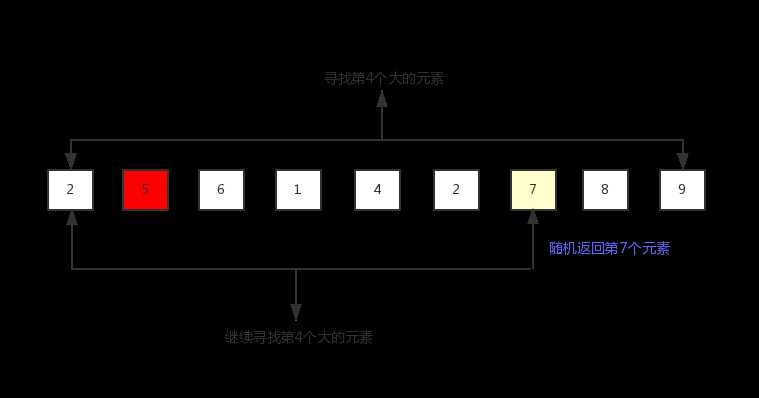
下面是该算法的C语言实现!
int partition(int *A, int p, int q) { int tmp = A[p]; int r = p; int i; for (i = p + 1; i < q + 1; i++) { if (A[i] < tmp) { r += 1; swap(A[r], A[i]); } } swap(A[p], A[r]); return r; } int findKthElement(int *A, int p, int q, int k) { if (p == q) return A[p]; r = partition(A, p, q); if (r == k) return A[k]; else if (r > k) return findKthElement(A, p, r, k); else return findKthElement(A, r, q, k-r+1); }
简单的来分析下算法: 这个算法具有很大的随机性,如果足够幸运的话,每次划分正好是中值,那么算法就结束了。复杂度为O(n). 但是如果不那么幸运,每次划分的元素移动的步长为1, 即 T(n) = T(n - 1) + O(n), 那么该算法复杂度就为O(n^2). 但是就平均意义而言,该算法的时间复杂度期望值为O(n)。 证明可以参考算法导论。
那么在理论上有没有就是 O(n) 复杂度的算法呢? 还真是被一群 大师级 的人物给发明出来了。想要获取 O(n) 复杂度的关键在于 随机元素的选取,如果能够选到合适的随机元素,那么这个问题就 迎刃而解了! 下面是该算法选取随机元素的示意图:
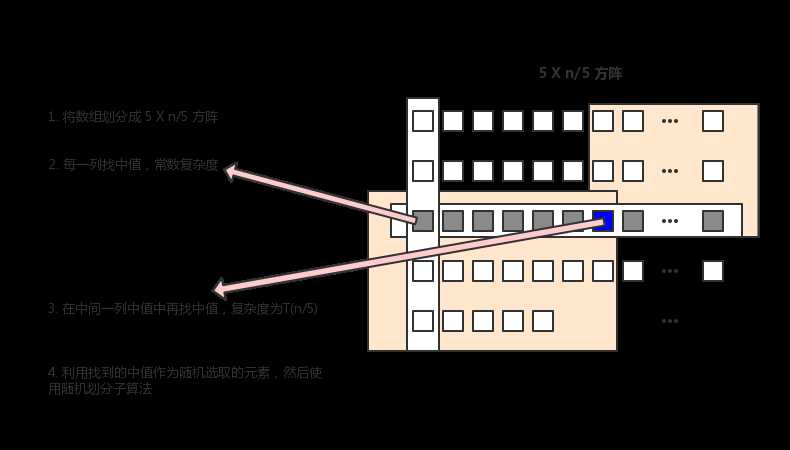
下面计算这个算法的复杂度,T(n) = T(a · n) + T(n / 5) + O(n). 只要这个系数 a 小于4/5,那么这个算法就是线性的复杂度。这种划分方式到底有没有起到这个效果呢? 通过示意图来看,利用比较的传递性,最终取出来的中值是介于图中两块棕色区域内元素之间的。那么就可以计算这个取出来的中值大概在整个序列的哪个范围之内。当n足够大时,这样的划分方法至少能取得 7/10 的效果。所以从分析上来看,这个算法是线性复杂度。
下面是一条摘自 LeetCode 上有关中值的练习题
There are two sorted arrays nums1 and nums2 of size m and n respectively. Find the median of the two sorted arrays. The overall run time complexity should be O(log (m+n)).
关键在于 O(log(m+n)) 的算法复杂度要求,但其实并不难,下面是我的一种解法。
+code
标签:
原文地址:http://www.cnblogs.com/Gru--/p/5024287.html