标签:
1.每个网络应用都是基于客户端-服务器模型的。采用这个模型,一个应用是由一个服务器进程和一个或者多个客户端进程组成。服务器管理某种资源,并且通过操作这种资源来为它的客户端提供某种服务。
eg:一个Web服务器管理了一组磁盘文件,它为客户端进行它会为客户端进行存储和检索。一个FTP管理了一组磁盘文件。相似地一个电子邮件服务器管理了一些文件,它为客户端进行读和更新。
2.客户端-服务器模型中的基本操作是事务。
○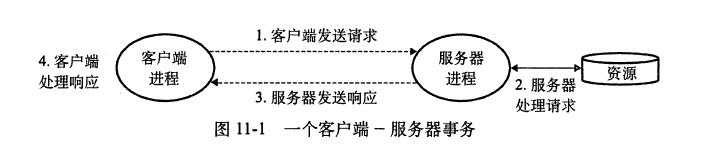
3.一个客户端-服务器事务由四步组成
1)当一个客户端需要服务时,它向服务器发送一个请求,发起一个事务。例如,当Web览器需要一个文件时,它就发送一个请求给Web服务器
2)服务器收到请求后,解释它,并以适当的方式操作它的资源。例如,当Web服务器收到浏览器发出的请求后,它就读一个磁盘文件
3)服务器给客户端发送一响应,并等待下一个请求。例如,Web服务器将文件发送回客户端;
4)客户端收到响应并处理它。例如,当Web浏览器收到来自服务器的一页后,它就在屏幕上显示此页。
○
每根电缆都有相同的最大位带宽
集线器不加分辩地将一个端口上收到的每个位复制到其他所有的端口上
因此,每台主机都能看到每个位。
它存储在这个适配器的非易失性存储器上。每个主机适配器都能看到这个帧,但是只有目的主机实际读取它。
它由电缆和网桥将多个以太网段连接起来,形成的较大的局域网。连接网桥的电缆传输速率可以不同(例:网桥与网桥之间1GB/S, 网桥与集线器之间100MB/S)。
同一网段内A向B传输数据时,帧到达网桥输入端口,网桥将其丢弃,不予转发。A向另一网段内C传输数据时,网桥才将帧拷贝到与相应网段连接的端口上。从而节省了网段的带宽
命名机制 为每台主机至少分配一个互联网地址,从而消除不同主机地址格式的差异,这个地址唯一地标识了这台主机。
传送机制 不同格式的数据进行封装,使其具有相同的格式。
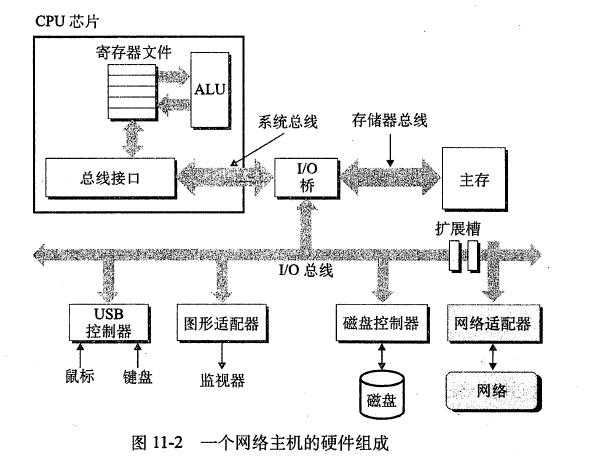
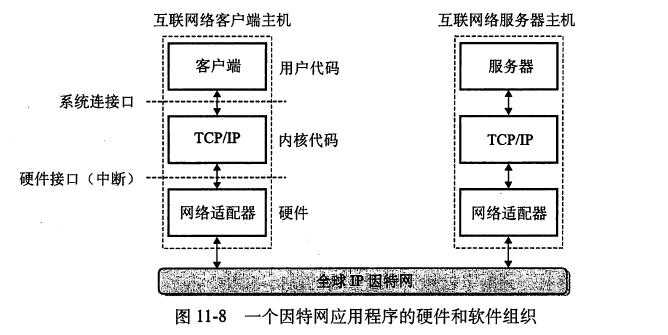
全球IP因特网是最著名和最成功的互联网络实现。从1969年起,它就以这样或那样的形式存在了。虽然因特网的内部体系结构复杂而且不断变化,但是自从20世纪80年代早期以来,客户端-服务器应用的组织就一直保持相当的稳定。下图展示了一个因特网客户端-服务器应用程序的基本硬件和软件组织。每台因特网主机都运行实现TCP/TP协议的软件,几乎每个现代计算机系统都支持这个协议。因特网的客户端和服务器混合使用套接字接口函数和Unix I/O函数来进行通信。套接字函数典型地是作为会陷入内核的系统调用来实现的,并调用各种内核模式的TCP/IP函数。
○
一个IP地址就是一个32位无符号整数。网络程序将IP地址存放在下图所示的IP地址结构中。
○
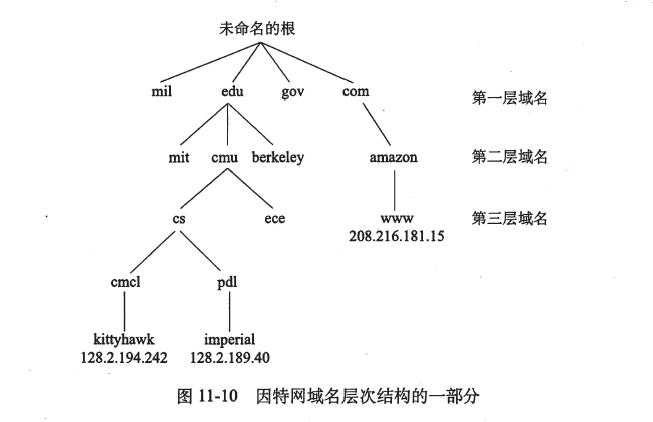
1.因特网客户端和服务器互相通信时使用的是IP地址。为了方便记忆,因特网也定义了一组更加人性化的域名,以及一种将域名映射到IP地址的机制。域名是一串用句点分隔的单词(字母、数字和破折号)。
2.域名集合形成了一个层次结构,每个域名编码了它在这个层次中的位置。通过一个示例你将很容易理解这点。下展示了域名层次结构的一部分。层次结构可以表示为一棵树。树的节点表示城名,反向到根的路径形成了域名。子树称为子域。层次结构中的第一层是个未命名的根节点。下一层是一组一级域名由非赢利组织(因特网分酒名字数字协会)定义。常见的第一层域名包括com、edu、gov、org、net,这些域名是由ICANN的各个授权代理按照先到先服务的基础分配的的。一旦一个组织得到了一个二级域名,那么它就可以在这个子域中创建任何新的域名了。
因特网客户端和服务器通过在连接上发送和接收字节流来通信。从连接一对进程的意义上而言,连接是点对点的。从数据可以同时双向流动的角度来说,它是全双工的。并且从(除了一些如粗心的耕锄机操作员切断了电缆引起灾对性的失败以外)由源进程发出的字节流最终被目的进程以它发出的顺序收到它的角度来说,它也是可靠的。
○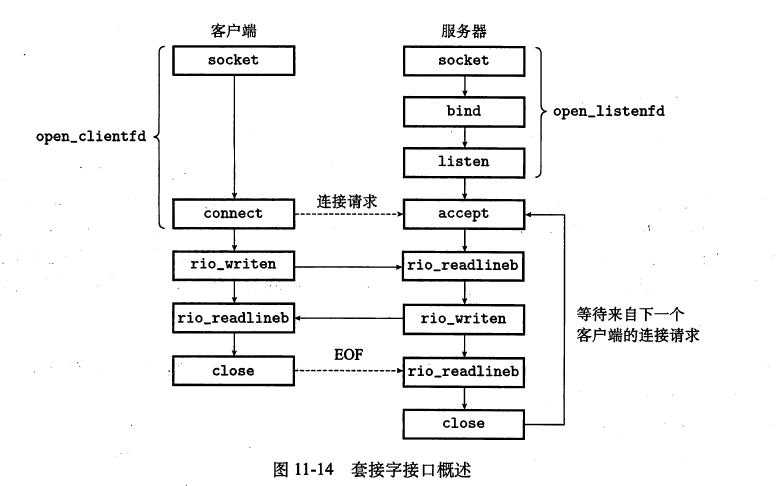
从Unix内核的角度来看,一个套接字就是通信的一个端点。
○
客户端通过connect函数来建立和服务器的连接。
○
○




Web客户端和服务器之间的交互用的是一个基于文本的应用级协议,叫做HTTP。
HTTP是一个简单的协议。一个web客户端(即浏览器)打开一个到服务器的因特网连接。浏览器读取这些内容,并请求某些内容。服务器响应所请求的内容,然后关闭连接。浏览器读取并把它显示在屏幕内
主要的区别是Web内容可以用HTML来编写。一个HTML程序(页)包含指令(标记)它们告诉浏览器如何显示这页中的各种文本和图形对象。
Web服务器以两种不同的方式向客户端提供内容:
1.取一个磁盘文件,并将它的内容返回给客户端。
2.运行一个可执行文件,并将它的输出返回给客户端。
http请求
http响应
1.客户端如何将程序参数传递给服务器 2.服务器如何将参数传递给子进程 3.服务器如何将其他信息传递给子进程 4.子进程将它的输出发送到哪里
TINY的main程序
doit函数
clienterror函数
readrequestthdrs函数
parseuri函数
servestatic函数
servedynamic函数
三种基本的构造并发程序的方法:
1.进程
每个逻辑控制流是一个进程,由内核进行调度,进程有独立的虚拟地址空间
2.I/O多路复用
逻辑流被模型化为状态机,所有流共享同一个地址空间
3.线程
运行在单一进程上下文中的逻辑流,由内核进行调度,共享同一个虚拟地址空间
使用SIGCHLD处理程序来回收僵死子进程的资源。
父进程必须关闭他们各自的connfd拷贝(已连接的描述符),避免存储器泄露。
因为套接字的文件表表项中的引用计数,直到父子进程的connfd都关闭了,到客户端的连接才会终止。
1.优点:防止虚拟存储器被错误覆盖
2.缺点:开销高,共享状态信息才需要IPC机制
使用select函数,要求内核挂起进程,只有在一个或多个I/O事件发生后,才将控制返回给应用程序。
int select(int n,fd_set *fdset,NULL,NULL,NULL); 返回已经准备好的描述符的非0的个数,若出错则为-1。
select函数处理类型为fd_set的集合,叫做描述符集合,看做一个大小为n位的向量:
bn-1,......,b1,b0
I/O多路复用可以用作事件并发驱动程序的基础。
状态机:一组状态、输入事件、输出事件和转移。
自循环:同一输入和输出状态之间的转移。
注意:
init_pool:初始化客户端池
add_client:添加一个新的客户端到活动客户端池中
check_clients:回送来自每个准备好的已连接描述符的一个文本行
相较基于进程的设计,给了程序员更多的对程序程序的控制
运行在单一进程上下文中,所以每个逻辑流都可以访问该进程的全部地址空间,共享数据容易实现
可以使用GDB调试
高效
编码复杂
不能充分利用多核处理器
每个线程都有自己的线程上下文,包括一个线程ID、栈、栈指针、程序计数器、通用目的寄存器和条件码。所有的运行在一个进程里的线程共享该进程的整个虚拟地址空间。由于线程运行在单一进程中,因此共享这个进程虚拟地址空间的整个内容,包括它的代码、数据、堆、共享库和打开的文件。
每个进程开始生命周期时都是单一线程(主线程),在某一时刻创建一个对等线程,从此开始并发地运行,最后,因为主线程执行一个慢速系统调用,或者被中断,控制就会通过上下文切换传递到对等线程。
Posix线程是C语言中处理线程的一个标准接口,允许程序创建、杀死和回收线程,与对等线程安全的共享数据。
线程的代码和本地数据被封装在一个线程例程中。
线程通过调用pthread_create来创建其他线程。
int pthread_create(pthread_t *tid,pthread_attr_t *attr,func *f,void *arg); 成功则返回0,出错则为非零
当函数返回时,参数tid包含新创建的线程的ID,新线程可以通过调用pthread_self函数来获得自己的线程ID。
pthread_t pthread_self(void);返回调用者的线程ID。
一个线程是通过以下方式之一来终止的。
当顶层的线程例程返回时,线程会隐式地终止。
通过调用pthread_exit函数,线程会显式地终止
void pthread_exit(void *thread_return);
线程通过调用pthread_join函数等待其他线程终止。
int pthread_join(pthread_t tid,void **thread_return); 成功则返回0,出错则为非零
在任何一个时间点上,线程是可结合或可分离的。一个可结合的线程能够被其他线程收回其资源和杀死,在被回收之前,它的存储器资源是没有被释放的。分离的线程则相反,资源在其终止时自动释放。
int pthread_deacth(pthread_t tid);
成功则返回0,出错则为非零
pthread_once允许初始化与线程例程相关的状态。
pthread_once_t once_control=PTHREAD_ONCE_INIT; int pthread_once(pthread_once_t *once_control,void (*init_routine)(void)); 总是返回0
一个变量是共享的。当且仅当多个线程引用这个变量的某个实例。
全局变量:定义在函数之外的变量
本地自动变量:定义在函数内部但是没有static属性的变量。
本地静态变量:定义在函数内部并有static属性的变量。
一个变量V是共享的,当且仅当它的一个实例被一个以上的线程引用。例如,示例程序中的变量cnt就是共享的,因为它只有一个运行时实例,并且这个实例被两个对等线程引用在另一方面,myid不是共享的,因为它的两个实例中每一个都只被一个线程引用。然而,认识到像msgs这样的本地自动变量也能被共享是很重要的。
共享变量的同时引入了同步错误,即没有办法预测操作系统是否为线程选择一个正确的顺序。
○
进度图是将n个并发线程的执行模型化为一条n维笛卡尔空间中的轨迹线,原点对应于没有任何线程完成一条指令的初始状态。
当n=2时,状态比较简单,是比较熟悉的二维坐标图,横纵坐标各代表一个线程,而转换被表示为有向边
转换规则:
合法的转换是向右或者向上,即某一个线程中的一条指令完成
两条指令不能在同一时刻完成,即不允许出现对角线
程序不能反向运行,即不能出现向下或向左
而一个程序的执行历史被模型化为状态空间中的一条轨迹线。
信号量不变性:一个正确初始化了的信号量有一个负值。
信号量操作函数:
int sem_init(sem_t *sem,0,unsigned int value);//将信号量初始化为value int sem_wait(sem_t *s);//P(s) int sem_post(sem_t *s);//V(s)
信号量提供了一种很方便的方法来确保对共享变量的互斥访问。基本思想是将每个共享变量(或者一组相关的共享变量)与一个信号量联系起来 。以这种方式来保护共享变量的信号量叫做二元信号量,因为它的值总是0或者1。以提供互斥为目的的二元信号量常常也称为互斥锁。在一个互斥锁上执行P操作称为对互斥锁加锁。类似地,执行V操作称为对互斥锁解锁。对一个互斥锁加了锁但是还没有解锁的线程称为占用这个互斥锁。一个被用作一组可用资源的计数器的信号量称为计数信号量。关键思想是这种P和V操作的结合创建了一组状态,叫做禁止区。因为信号量的不变性,没有实际可行的轨迹线能够包含禁止区中的状态。而且,因为禁止区完全包括了不安全区,所以没有实际可行的轨迹线能够接触不安全区的任何部分。因此,每条实际可行的轨迹线都是安全的,而且不管运行时指令顺序是怎样的,程序都会正确地增加计数器的值。
信号量有两个作用:
实现互斥
调度共享资源
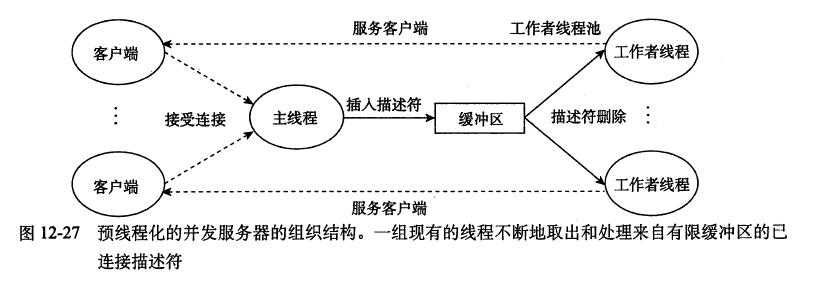
在如图所示的并发服务器中,我们为每一个新客户端创建了一个新线程这种方法的缺点是我们为每一个新客户端创建一个新线程,导致不小的代价。一个基于预线程化的服务器试图通过使用如图所示的生产者-消费者模型来降低这种开销。服务器是由一个主线程和一组工作者线程构成的。主线程不断地接受来自客户端的连接请求,并将得到的连接描述符放在一个不限缓冲区中。每一个工作者线程反复地从共享缓冲区中取出描述符,为客户端服务,然后等待下一个描述符。
○
到目前为止,在对并发的研究中,我们都假设并发线程是在单处许多现代机器具有多核处理器。并发程序通常在这样的机器上运理器系统上执行的。然而,在多个核上并行地调度这些并发线程,而不是在单个核顺序地调度,在像繁忙的Web服务器、数据库服务器和大型科学计算代码这样的应用中利用这种并行性是至关重要的。
定义四个(不相交的)线程不安全函数类:
不保护共享变量的函数。
保持跨越多个调用状态的函数。
返回指向静态变量指针的函数。
调用线程不安全函数的函数。
当它们被多个线程调用时,不会引用任何共享数据。
1.显式可重入的:
所有函数参数都是传值传递,没有指针,并且所有的数据引用都是本地的自动栈变量,没有引用静态或全剧变量。
2.隐式可重入的:
调用线程小心的传递指向非共享数据的指针。
1.竞争发生的原因:
一个程序的正确性依赖于一个线程要在另一个线程到达y点之前到达它的控制流中的x点。也就是说,程序员假定线程会按照某种特殊的轨迹穿过执行状态空间,忘了一条准则规定:线程化的程序必须对任何可行的轨迹线都正确工作。
2.消除方法:
动态的为每个整数ID分配一个独立的块,并且传递给线程例程一个指向这个块的指针
1.一组线程被阻塞了,等待一个永远也不会为真的条件。
程序员使用P和V操作顺序不当,以至于两个信号量的禁止区域重叠。
重叠的禁止区域引起了一组称为死锁区域的状态。
死锁是一个相当难的问题,因为它是不可预测的。
2.互斥锁加锁顺序规则:如果对于程序中每对互斥锁(s,t),给所有的锁分配一个全序,每个线程按照这个顺序来请求锁,并且按照逆序来释放,这个程序就是无死锁的。
本周学习了两章的内容,第十一章在刘念老师的课中已经学过,有了一定的基础,这次学习更加深入了。第十二章的内容与操作系统的课程有一定关联,我刚刚做完GDB深入实践,其中多线程多进程的部分也让我对这里有了些了解。
1.《深入理解计算机系统》
2.linux中fork函数及子进程父进程进程先后 http://blog.csdn.net/wu_zf/article/details/7640970
标签:
原文地址:http://www.cnblogs.com/bonjourvivi/p/5024459.html