标签:
3.1 决策树的构造
3.1.1 信息增益
熵(entropy)是信息的期望值。如果待分类的事物可能划分在多个分类中,则符号xi的信息定义为: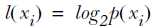 ,p(xi)为该分类的概率。
,p(xi)为该分类的概率。
为了计算熵,需计算所有类别所有可能包含的信息期望值: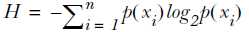 ,n是分类的数目。
,n是分类的数目。

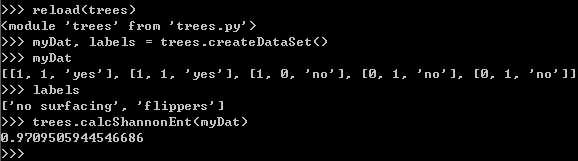
3.1.2 划分数据集
分类算法需要:上述的测量信息熵、划分数据集、度量划分数据集的熵。

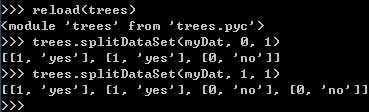

注意:这里数据集需要满足以下两个办法:
<1>所有的列元素都必须具有相同的数据长度
<2>数据的最后一列或者每个实例的最后一个元素是当前实例的类别标签。

3.1.3 递归构建决策树
递归结束条件:程序遍历完所有划分数据集的属性,或者每个分支下的所有实例都有相同的分类。
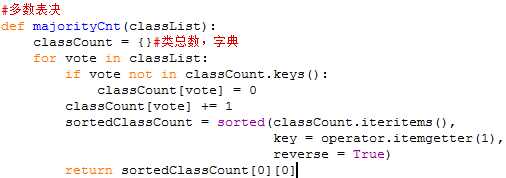
如果数据集已处理完所有属性,但类标签依然不唯一。此时,会采用多数表决方法决定该叶子节点分类。
该叶节点中属于某一类最多的样本数,那么我们就说该叶节点属于那一类!。


标签:
原文地址:http://www.cnblogs.com/hudongni1/p/5024450.html