标签:
一、Hadoop简介
1.1、Hadoop主要进行分布式存储和分布式计算
1.1-1、HDFS:分布式文件系统
1.1-2、MapReduce:并行计算框架
1.2、Hadoop用来做什么?
搭建大型的数据仓库
搜索引擎、日志分析、数据挖掘
1.3、优势:
高扩展、低成本、成熟的生态圈
二、Hadoop核心
2.1、HDFS
2.1.1 简介
文件被分成块进行存储(默认块的大小是64MB),HDFS两个重要节点NameNode和DataNode
1)NameNode:管理节点,存储源文件
(1)存储文件与数据块的映射表
(2)存储数据块与DataNode的映射表
2)DataNode:数据节点
用于存放数据块
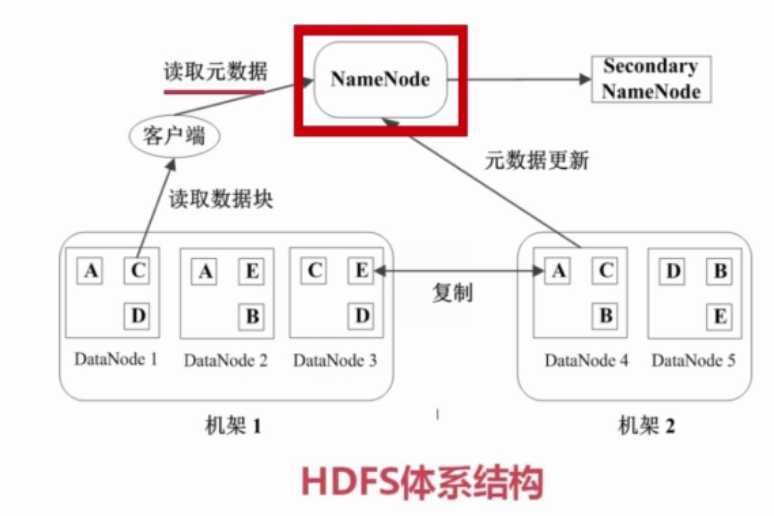
2.1.3 HDFS的数据存储和容错
1)对每个数据块存储3份,2份在同一机架,1份在另一机架
2)心跳检测,DataNode定期向NameNode发送心跳消息。
3)二级NameNode(对NameNode的数据进行同步备份,),NameNode故障以后,切换到二级NameNode
2.1.4 HDFS文件读取
1)读取文件
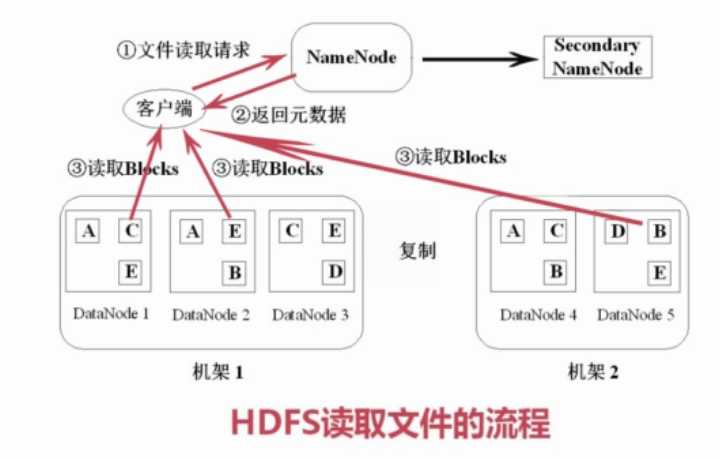
(1) 客户端向NameNode请求数据
(2) NameNode查询源数据,回复客户端,文件包括哪些块,这些块分别位于哪个DataNode
(3)客户端分别对DataNode读取块,将block组装成源文件
2)写文件
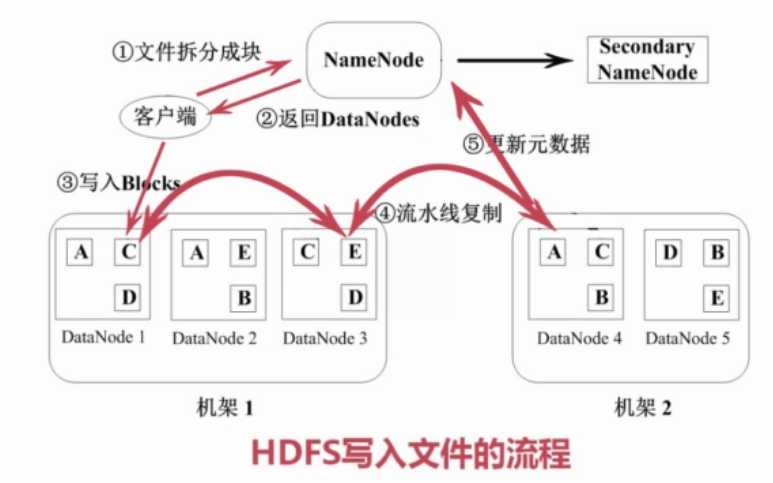
(1)客户端将文件拆分成块,发送给NameNode
(2)NameNode发挥给客户端一系列可用的DataNode
(3)客户端将数据写入到DataNode,
(4)DataNode对数据进行流水线复制,保留三份
(5)更新源数据,DataNode向NameNode汇报数据
2.1.5 HDFS的特点
1) 数据冗余,硬件容错(三备份)
2) 流式数据访问(1次写入,多次读取,写入后无法修改)
3) 适合存储大文件,(小文件对NameNode的负载压力大)
2.1.6 HDFS适应性和局限性
1) 适合数据批量读写,吞吐量高。不适合交互式应用,低延时很满足(例如数据库)
2) 适合一次写入,多次读取,顺序写入。不支持多用户并发写相同的文件。
标签:
原文地址:http://www.cnblogs.com/likailiche/p/5027814.html