标签:
上一篇中介绍了的基本使用方法以及演示了一个简单的例子,在这一篇中我们来介绍了的原理。
首先我们来看一下

看完了图,那么我们一步一步跟着我们的代码调用来看下,以我们最简单的 .get()方法为例:

这边有调用一个getShard 方法,参数为我们传入的key,然后返回一个普通的jedis对象,那么这个getShard是用来做什么的呢,大家可能已经猜到了,这个方法就是会根据我们传入的key做一致性哈希判断,然后返回key落到的那个redis实例上的一个redis连接,不同的key返回的redis连接可能是不同的。
进入getShard 方法,你会发现这个实现是在Sharded类中实现的(看上面的类图可以发现顶层的Sharded类),代码如下:

上面的方法是层层调用的关系,在这边不细说,我们主要看下红框的那个方法实现(上面的nodes变量是一个TreeMap 类型, algo 是Hashing类型,即key分片所使用的hash算法,这个在前一篇有简单说过),那么这段代码的含义我们大概成猜出来了,
那么这个S、 R对象各自代表什么呢?看下面的代码


可以得出 S = JedisShardInfo, R = Jedis 对象,即在TreeMap存储了服务器划分的虚拟节点的信息,LinkedHashMap中存储了服务器的物理连接。
JedisShardInfo具体信息如下:里面包含了jedis服务器的一些信息,最重要的是它的父类中有一个weight字段,作为本jedis服务器的权值。
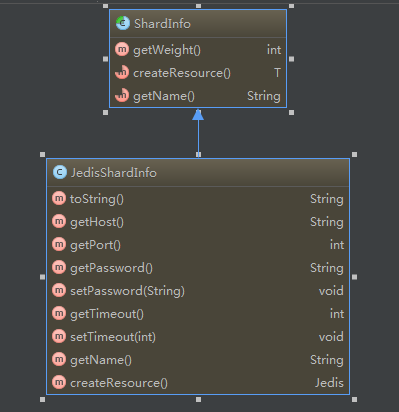
ok,那我们了解了实际上就是根据jedis服务器的信息去获取一个jedis的连接,返回给上层调用。
我们可以梳理下这个逻辑:
那么我们的nodes 服务器虚拟节点和resources 服务器物理连接是什么时候初始化的呢,接下来继续看
我们看到Sharded的构造方法

这边有一个initialize方法,看其实现

具体细节就不说了,根据上面的,我们就知道是在这边进行了初始化,将每台服务器节点采用hash算法划分为160个虚拟节点(可以配置划分权重),保存在TreeMap中,
然后把每台服务器节点的信息和物理连接以键值对保存LinkedHashMap中。
然后通过一系列的查找,发现Sharded的构造方法其实是在我们 jedisPool.getResource() 时就完成的

纳尼? 每次jedisPool.getResource() 才初始化?那会不会造成很慢呢,其实不用担心,其底层是使用了commons.pool来进行连接池的一些操作,会根据我们配置的连接池参数来生成对应的连接并保存,其中的细节很复杂,博主没有继续深究,实现其实和数据库连接池是一致的。
分布式具体的的实现思路:
redis服务器节点划分:将每台服务器节点采用hash算法划分为160个虚拟节点(可以配置划分权重)
将划分虚拟节点采用TreeMap存储
对每个redis服务器的物理连接采用LinkedHashMap存储
对Key or KeyTag 采用同样的hash算法,然后从TreeMap获取大于等于键hash值得节点,取最邻近节点存储;当key的hash值大于虚拟节点hash值得最大值时,存入第一个虚拟节点
sharded采用的hash算法:MD5 和 MurmurHash两种;默认采用64位的MurmurHash算法;
好了,大概的实现如上面所说的,都是图可能会有点乱,大家如果有什么问题或者发现了什么错误,please tell me!
Jedis下的ShardedJedis(分布式)使用方法(二)
标签:
原文地址:http://www.cnblogs.com/vhua/p/redis_2.html