标签:
15.1 Introduction
这部分太多概念我不了解。只看懂了最后一段,进程间通信(IPC)内容被组织成了三个部分:
(1)classical IPC : pipes, FIFOs, message queues, semaphores, and shared memory
(2)network IPC : sockets mechanism
(3)advanced features of IPC
15.2 Pipes
Pipes是“the oldest form of UNIX System IPC”,因此有两个方面的limitations:
(1)一般来说pipes都是半双工(half-duplex)的工作模式
(2)pipes能通信的process是有要求的:必须是同一个ancestor的(比如一个process不断fork这种的)
1. pipe函数
int pipe(int fd[2])
fd[0]:执行pipe后,fd[0]代表reading file descriptor
fd[1]: 执行pipe后,fd[1]代表writing file descriptor
返回0代表成功,-1表示失败
这个函数的原理可以用一张图来理解:

上左图:two ends connected in a single process
上右图:emphasizes that the data in the pipe flows through the kernel
这还是在single process里面玩儿,跟我们说的interprocess communication不一样。这时候要借助Chapter8中学到的内容,fork函数,化腐朽为神奇的一步:
“the process that calls pipe then calls fork, creating an IPC channel from the parent to the child, or vice versa”
翻译过来就是:pipe + fork 完成了一个最原始的interprocess communication。上面的IPC思路,可以用下图解释:
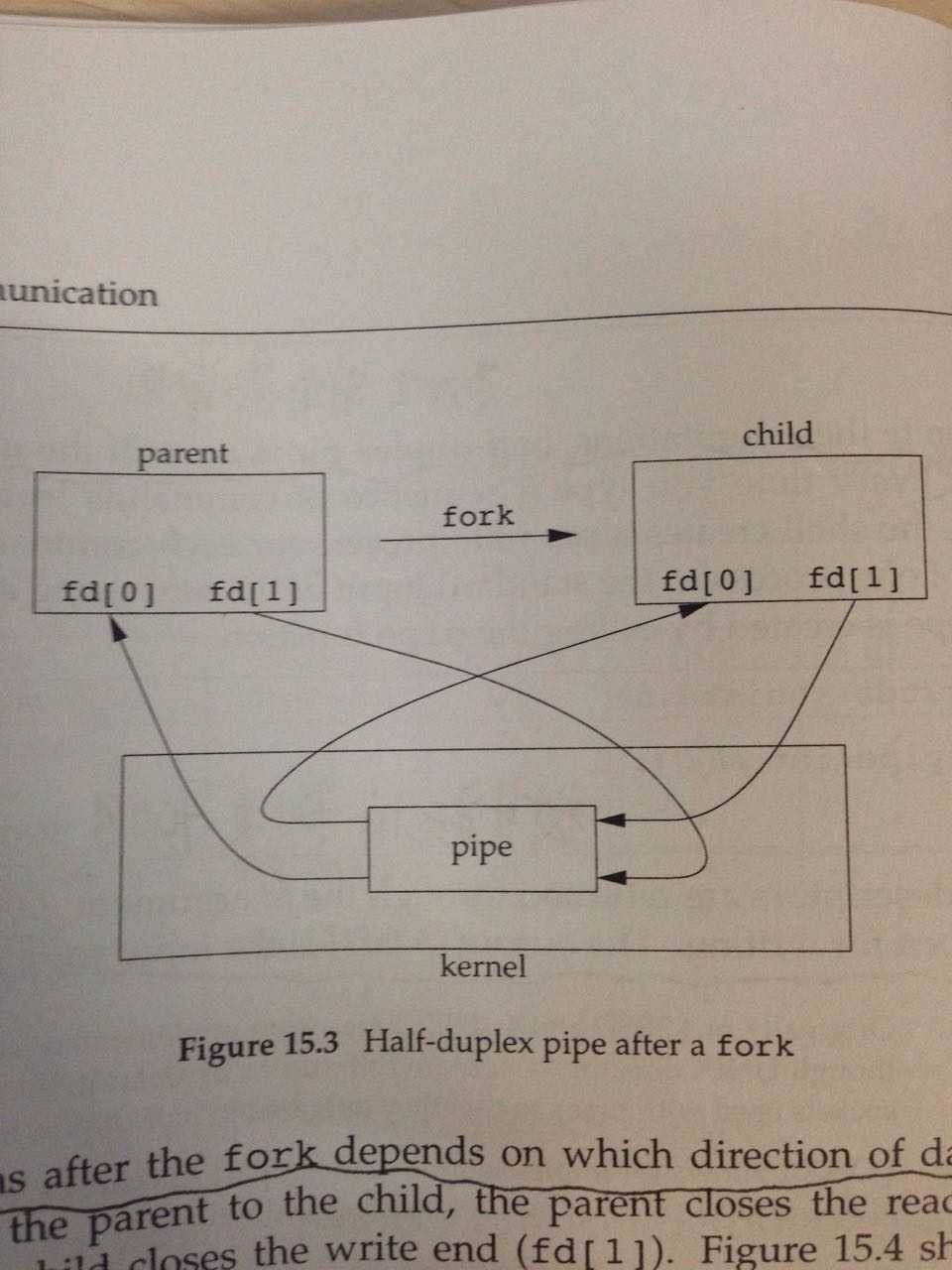
理解上面的原理图,需要有fork的背景知识:parent process经过fork出child process后,parent process的file descriptor是直接copy到child process的。
这样,经过fork之后,就在parent和child中各有一对fd[0] fd[1]:
(1)parent中的fd[1]由pipe输出到parent和child的两个fd[0]
(2)child中的fd[1]同理也可以由pipe输出到parent和child中的两个fd[0]
2. Pipe函数实现基础IPC功能
下面,搞一个程序验证下是不是pipe是不是实现了这样的功能:
1 #include "apue.h" 2 3 int main(int argc, char *argv[]) 4 { 5 int n; 6 int fd[2]; 7 pid_t pid; 8 char line[MAXLINE]; 9 10 if (pipe(fd)<0) { 11 err_sys("pipe error"); 12 } 13 if ((pid=fork())<0) { 14 err_sys("fork error"); 15 } 16 else if (pid>0) { /*parent process*/ 17 //close(fd[0]); 18 write(fd[1], "12345678", 8); 19 sleep(2); 20 n = read(fd[0], line, 4); 21 write(STDOUT_FILENO, line, n); 22 printf("parent\n"); 23 } 24 else { 25 //close(fd[1]); 26 n = read(fd[0], line, 4); 27 write(STDOUT_FILENO, line, n); 28 printf("child\n"); 29 } 30 exit(0); 31 }
( 在pipe+fork之后,常规的套路应该是关闭parent和child端不用的file descriptor(parent关闭fd[0], child关闭fd[1]),但是为了解决上面的疑惑故意没有关上)
这样,效果就是parent和child都保持了read和write的入口。
程序做的事情就是在parent process中往pipe中写“12345678”总共8个字符,先让child process从pipe的出口读4个字符,然后再让parent process从pipe的出口读4个字符。代码运行结果如下:

从结果中看到,parent和child都从管道中fetch了4个字符。解决了之前的疑惑。
更进步一步,查阅了如下的blog(http://blog.csdn.net/tennysonsky/article/details/46315517),下面的几点总结的挺好:

还有一点要注意,read方法是阻塞的:如果parent和child都用read方法从pipe中读内容,如果pipe中的内容被读光了,read方法就阻塞住了。
把上面代码中line18改为“write(fd[1], "1234", 4)”,运行结果如下:

结果就是parent process在read那里阻塞住了。原因是:
(1)pipe中的数据一旦被read走就消失了
(2)read方法是阻塞方法,读不到数据就挂住了
上面解释了“read读不到数据被阻塞的情况”,如果是write写数据的时候,read端已经关闭了呢?这个时候会产生一个SIGPIPE信号。
有如下代码:
1 #include "apue.h" 2 #include <signal.h> 3 #include <unistd.h> 4 5 void sig_pipe(int signo) 6 { 7 printf("pid:%d\n",getpid()); 8 if ( signo == SIGPIPE) 9 { 10 printf("fetch SIGPIPE\n"); 11 fflush(stdout); 12 } 13 } 14 15 int main(int argc, char *argv[]) 16 { 17 int n; 18 int fd[2]; 19 pid_t pid; 20 char line[MAXLINE]; 21 signal(SIGPIPE, sig_pipe); 22 23 if (pipe(fd)<0) { 24 err_sys("pipe error"); 25 } 26 if ((pid=fork())<0) { 27 err_sys("fork error"); 28 } 29 else if (pid>0) { /*parent process*/ 30 close(fd[0]); 31 sleep(10); 32 write(fd[1], "1234", 4); 33 printf("parent\n"); 34 } 35 else { 36 //close(fd[1]); 37 printf("child\n"); 38 close(fd[0]); 39 } 40 exit(0); 41 }
程序运行结果如下:
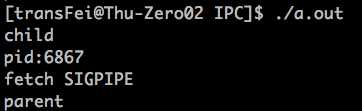
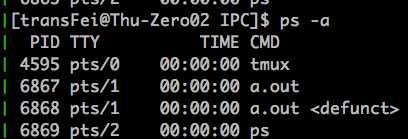
可以看到,是调用write的parent process捕获了这个SIGPIPE信号(parent pid是6867)。(child pid为6868,由于parent没有回收child process,所以在child process执行完之后,就变成了野进程了<defunct>)
3. 利用pipe函数实现一个 cat XXX | more的例子
如题,直接上例子代码:
1 #include "apue.h" 2 #include <sys/wait.h> 3 4 #define DEF_PAGER "/bin/more" /*default pager program*/ 5 6 int main(int argc, char *argv[]) 7 { 8 int n; 9 int fd[2]; 10 pid_t pid; 11 char *pager, *argv0; 12 char line[MAXLINE]; 13 FILE *fp; 14 15 fp = fopen(argv[1], "r"); /*把fp关联到disk file*/ 16 pipe(fd); /*创建pipe*/ 17 18 if ((pid = fork())<0) { 19 err_sys("fork error"); 20 } 21 else if (pid>0) { /*parent process*/ 22 close(fd[0]); 23 while (fgets(line, MAXLINE, fp)!=NULL) { /*从disk file中读一行*/ 24 n = strlen(line); 25 if (write(fd[1], line, n)!=n) { /*往child process的fd[0]中写*/ 26 err_sys("write error to pipe"); 27 } 28 } 29 ferror(fp); /*检查写的过程中是否出问题了*/ 30 close(fd[1]); /*关闭写的fd*/ 31 if (waitpid(pid, NULL, 0)<0) { /*等child process执行完毕*/ 32 err_sys("waitpid error"); 33 } 34 exit(0); 35 } 36 else { 37 close(fd[1]); 38 if (fd[0] != STDIN_FILENO) { /*将fd[0]关联到stdin中*/ 39 if (dup2(fd[0], STDIN_FILENO)!=STDIN_FILENO) { 40 err_sys("dup2 error to stdin"); 41 } 42 close(fd[0]); /*fd[0]的使命到此结束了 因为read end已经被关联到stdout了*/ 43 } 44 if ((pager = getenv("PAGER"))==NULL) { /*从环境变量中读取PAGER*/ 45 pager = DEF_PAGER; 46 } 47 if ((argv0 = strrchr(pager, ‘/‘))!=NULL) { /*找到‘/‘在字符串pager中最后一次出现的位置*/ 48 argv0++; 49 } 50 else { 51 argv0 = pager; 52 } 53 if (execl(pager, argv0, (char *)0)<0) { /*pager是命令path argv0是具体路径下的命令*/ 54 err_sys("execl error for %s", pager); 55 } 56 } 57 exit(0); 58 }
编译后,执行如下命令:

获得结果如下:
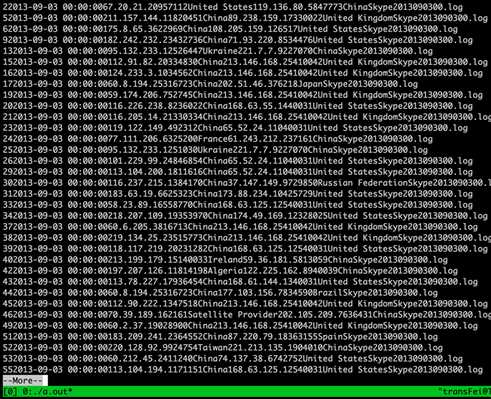
从结果来看 就跟 cat XXX | more实现的功能是一样的。
从代码上看,为了实现上面的功能,主要在line39~line41中用到了dup2这个函数。回顾一下dup2这个函数:
int dup2(A, B)
(1)A是已经打开的file descriptor
(2)让B与A关联到同一个file
(3)如果A是not valid则fail
(4)如果A与B相等,则什么都不做返回
有了上面的背景知识,理解以上的代码主要有以下几点:
(1)dup2是把parent process通过fd[1]往pipe里面写数据,本来正常的出口是fd[0],但是通过dup2把出口改到了child process的STDIN_FILENO上面。这样就彻底实现了cat XXX | more一样的功能。“cat XXX”就是parent process做的事情,“|”就是起到了dup2的作用,“more”是child process实际做的事情。
(2)execl之后child process执行的内容就是/bin/more命令;而执行more命令的process中file descriptor是从之前child process中继承下来的,而STDIN_FILENO就是编号为0的file descriptor;所以对于“more”命令来说,它的STDIN_FILENO就是pipe的出口端fd[0]。具体excel的细节,还得去看APUE的chapter 8。
4. popen & pclose函数 及其实现细节
"pipe + fork"编程模型是一个最基础的IPC模型,<stdio.h>中提供了两个函数来集成化实现"pipe+fork"的编程模型。
FILE *popen(const char *cmdstring, const char *type)
int pclose(FILE *fp)
参数cmdstring就是要执行的命令, type可以取值{“r”, “w”}两个值。这里的r和w跟fopen中的r和w一个意思。
当type对应的参数为"r"的时候,即fp = popen(cmdstring, "r")的情况下,是如下的编程模型:

当type对应的参数为"w"的时候,即fp = popen(cmdstring, "w")的情况下,是如下的编程模型:
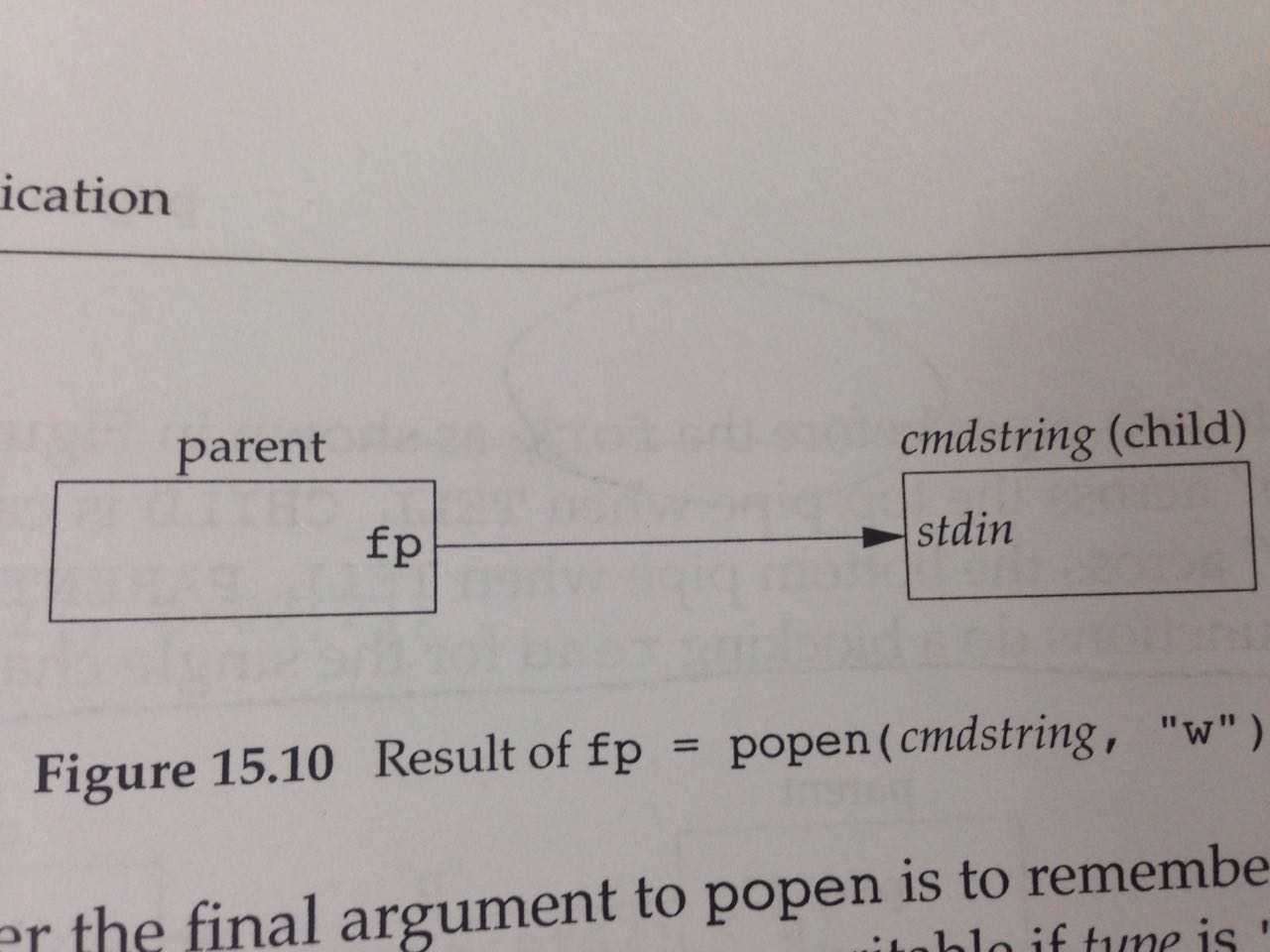
这两个函数本身stdio是都提供具体实现的,但是为了串起来一些细节,用一个综合的例子来说明。
这个例子还是实现cat XXX | more的功能,与之前的区别是把"pipe+fork"的编程模型继承到了popen和pclose中。具体代码如下:
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <unistd.h> 4 #include <errno.h> 5 #include <fcntl.h> 6 #include <sys/wait.h> 7 #include <limits.h> 8 9 #ifdef OPEN_MAX 10 static long openmax = OPEN_MAX; 11 #else 12 static long openmax = 0; 13 #endif 14 15 #define OPEN_MAX_GUESS 256 16 #define PAGER "${PAGER:-more}" /*environment variable, or default*/ 17 #define MAXLINE 4096 18 19 static pid_t *childpid = NULL; /*pointer to array allocated at run-time*/ 20 static int maxfd; 21 22 /*系统允许获得的最大的file descriptor数量*/ 23 long open_max(void) 24 { 25 if (openmax==0) { 26 errno = 0; 27 if ((openmax = sysconf(_SC_OPEN_MAX))<0) { 28 if (errno == 0) { 29 openmax = OPEN_MAX_GUESS; 30 } 31 else { 32 err_sys("sysconf error for _SC_OPEN_MAX"); 33 } 34 } 35 } 36 return openmax; 37 } 38 39 40 FILE * popen(const char *cmdstring, const char *type) 41 { 42 int i; 43 int pfd[2]; 44 pid_t pid; 45 FILE *fp; 46 /*这段代码保证输入参数*/ 47 if ((type[0] != ‘r‘ && type[0] != ‘w‘)||(type[1] !=0)) { 48 errno = EINVAL; 49 return NULL; 50 } 51 if (childpid==NULL) { /*如果是首次处理childpid 动态给childpid分配内存*/ 52 maxfd = open_max(); 53 if ((childpid = calloc(maxfd, sizeof(pid_t)))==NULL) { 54 return NULL; 55 } 56 } 57 if (pipe(pfd)<0) { /*pipe搞一下pfd, pfd[0]代表input pfd[1]代表output*/ 58 return NULL; 59 } 60 if ( pfd[0]>=maxfd || pfd[1]>=maxfd ) { /*如果超出fd最大量程 就把fd都关了返回*/ 61 close(pfd[0]); 62 close(pfd[1]); 63 errno = EMFILE; /*这个ERROR的意思就是file descriptor超出最大量程了*/ 64 return NULL; 65 } 66 /*在这之前都是做各种准备工作*/ 67 if ((pid=fork())<0) { 68 return NULL; 69 } 70 else if (pid==0) { /*child process*/ 71 if (*type==‘r‘) { /*parent要从child中读 所以关闭child中pfd[0] input的fd*/ 72 close(pfd[0]); 73 if (pfd[1]!=STDOUT_FILENO) { /*常规套路 把pdf[1]引到child的标准输出中*/ 74 dup2(pfd[1], STDOUT_FILENO); 75 close(pfd[1]); 76 } 77 } 78 else { /*parent要向child中写 所以关闭child中pfd[1] output的fd*/ 79 close(pfd[1]); 80 if (pfd[0]!=STDIN_FILENO) { 81 dup2(pfd[0], STDIN_FILENO); 82 close(pfd[0]); 83 } 84 } 85 /*close all descriptors in childpid[]*/ 86 for( i=0; i<maxfd; i++ ) /*为什么要这种操作 因为child process可以继承parent process的file descriptor 但是这些file descriptor其实并不需要 所以都需要关了*/ 87 { 88 if (childpid[i]>0) { /*每次fork之后 child process中都会copy过来一套childpid 而这些pid在child porocess中其实都不需要 所以 需要一一给删除*/ 89 close(i); 90 } 91 } 92 /*至此 child process的准备工作都做好了: 1.管道铺好了 2.该关的fd也都关了*/ 93 execl("/bin/sh", "sh", "-c", cmdstring, (char *)0); 94 _exit(127); 95 } 96 /*parent process继续往下进行*/ 97 if (*type==‘r‘) { 98 close(pfd[1]); 99 if ((fp=fdopen(pfd[0], type))==NULL) { /*因为pfd已经被pipe打开了 所以对于打开的fd就要用fdopen来处理 下面‘w‘的情况同理*/ 100 return NULL; 101 } 102 } 103 else { 104 close(pfd[0]); 105 if ((fp=fdopen(pfd[1], type))==NULL) { 106 return NULL; 107 } 108 } 109 childpid[fileno(fp)] = pid; /*这里的方式是用fd作为index child pid号作为value 构建这个childpid数组*/ 110 return fp; 111 } 112 113 int pclose(FILE *fp) 114 { 115 int fd, stat; 116 pid_t pid; 117 118 if (childpid==NULL) { /*没有调用过popen函数 报错*/ 119 errno = EINVAL; 120 return -1; 121 } 122 fd = fileno(fp); /*file descriptor超过最大量程 报错*/ 123 if (fd>=maxfd) { 124 errno = EINVAL; 125 return -1; 126 } 127 if ((pid=childpid[fd])==0) { /*正用着的进程的pid是不可能为0的 因为没用用的childpid[]都是0 报错*/ 128 errno = EINVAL; 129 return -1; 130 } 131 childpid[fd] = 0; /*把进程pid设为0了 告诉父进程 这个曾经起作用的child process已经无效了*/ 132 if (fclose(fp)==EOF) { /*fclose执行不成功返回的是-1 且errno中标示了是什么错误*/ 133 return -1; 134 } 135 /*这里为什么要用while循环?*/ 136 while (waitpid(pid, &stat, 0)<0) { /*这个pid是子进程的pid 由于调用pclose的一定是parent process 所以必须等着child process进程执行完毕了再往下进行*/ 137 if (errno!=EINTR) { 138 return -1; 139 } 140 } 141 return stat; /*通过stat返回 与fp挂钩的child process的执行状态*/ 142 } 143 144 145 int main(int argc, char *argv[]) 146 { 147 char line[MAXLINE]; 148 FILE *fpin, *fpout; 149 150 fpin = fopen(argv[1], "r"); 151 if ((fpout = popen(PAGER, "w"))==NULL) { 152 err_sys("popen error"); 153 } 154 while (fgets(line, MAXLINE, fpin)!=NULL) { 155 if (fputs(line, fpout)==EOF) { 156 err_sys("fputs error to pipe"); 157 } 158 } 159 if (ferror(fpin)) { 160 err_sys("fgets error"); 161 } 162 if (pclose(fpout)==-1) { 163 err_sys("pclose error"); 164 } 165 exit(0); 166 }
代码执行结果与之前相同,不再赘述。主要通过这个例子来学习一些细节。
popen函数:
由于这种通用的函数要defensive programming的思路来设计,所以在实现functionality之前要处理各种corner case
(1)如果type的值不是r和w 则出错返回。
(2)如果childpid(childpid中存放着已经开着的各种child process的pid)为空,证明是parent process首次调用popen函数,需要给childpid分配memory。
(3)具体要给childpid分配多大的memory,这个由maxfd参数决定。maxfd这个由于具体系统实现决定(通过open_max函数获得,apue耍书上P52 figure2.17实现),含义是同一个process最多能开多少个fd(在我的用centos系统上是1024)。给childpid分配memory的方式一开始没理解好,问题主要纠结在为什么pid的array要根据file descriptor max来决定。其实,就应该是这样的,因为"pipe+fork"编程模型的核心在于一个fd通向一个child process;所以,最多能有多少个chidpid就是取决于最多能弄出来多少个file descriptor。
接下来就是之前提到过的“pipe+fork”编程模型,看似只返回了一个FILE *fp,实际上做了如下几件事情:
(4)私下搞出来一个child process,执行传入的cmdstring命令
(5)返回给parent process一个fp,这个fp就相当于child process的STDIN
(6)为了让parent process能定位到popen函数创建的child process。需要在childpid中存着这个pid,这里有个技巧,就是用parent process与child process关联的fp的fd,最终是fd作为这个child process pid在childpid数组中的index。我猜这样设计的原因是,pid和fd都同时知道了,想做什么操作也方便了。
(7)在child process中,用for循环把childpid中所有的fd都关闭了。因为fork之后,parent process中的childpid也继承到了chid process中,这对child process是无用的,而且不关掉还容易留隐患。通过检验childpid[i]是否为0,可以判断这个child process是否被fork出来过;如果被fork出来过,则证明其fd(就是i)是有效的,统统关闭之。注意,这里关闭的是后面fork出来的child process指向之前fork出来的child process的fd,有点儿拗口,主要是下面的图:
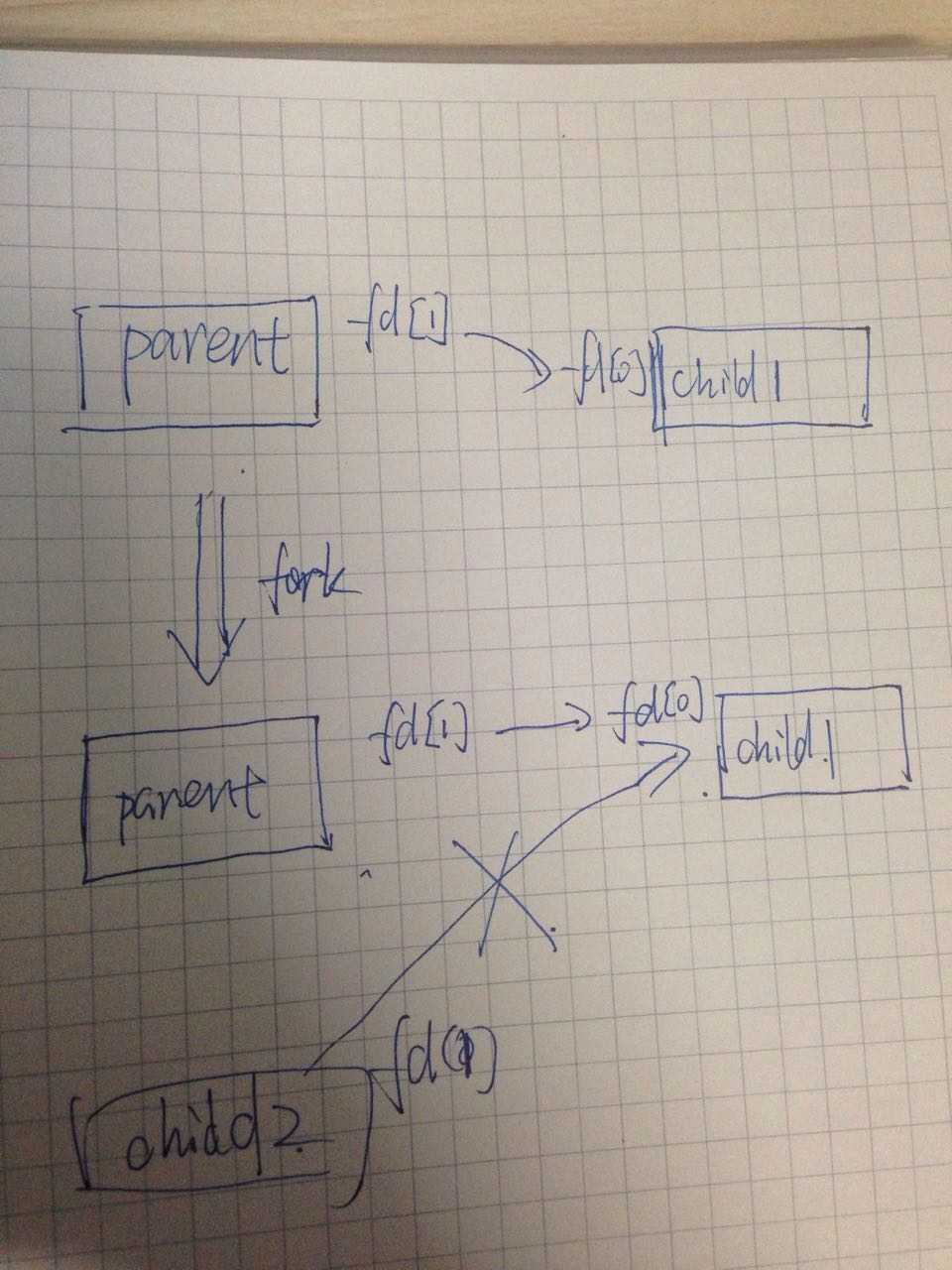
大概就是这个意思了。因此才有了for循环,删除child与child之间fd的关联。没有关联就不能乱删,判断有关联的标准就是pid!=0。这样就保证了只有parent与child之间的pipe连接,不会产生child与child之间的pipe通道。
pclose函数:
这个函的功能就是断开parent与某个child之间的pipe通道。这个功能分为三个实现环节:
(1)关闭之前获得的fp(传入的参数fp发挥了作用)
(2)防止child成为孤儿进程,必须回收child process的执行状态:用waitpid来完成这个事情,又由于waitpid允许被signal打断,而signal产生的EINTR信号是可以容忍出现的,因此用了while循环来做。(之前保存在childpid中的pid发挥了作用)
(3)还必须保证后续fork的child知道,这个child已经被回收了(childpid[fd]=0发挥了作用)
15.3 Coprocesses
自己写出去,经过一个filter处理后,再读回来。
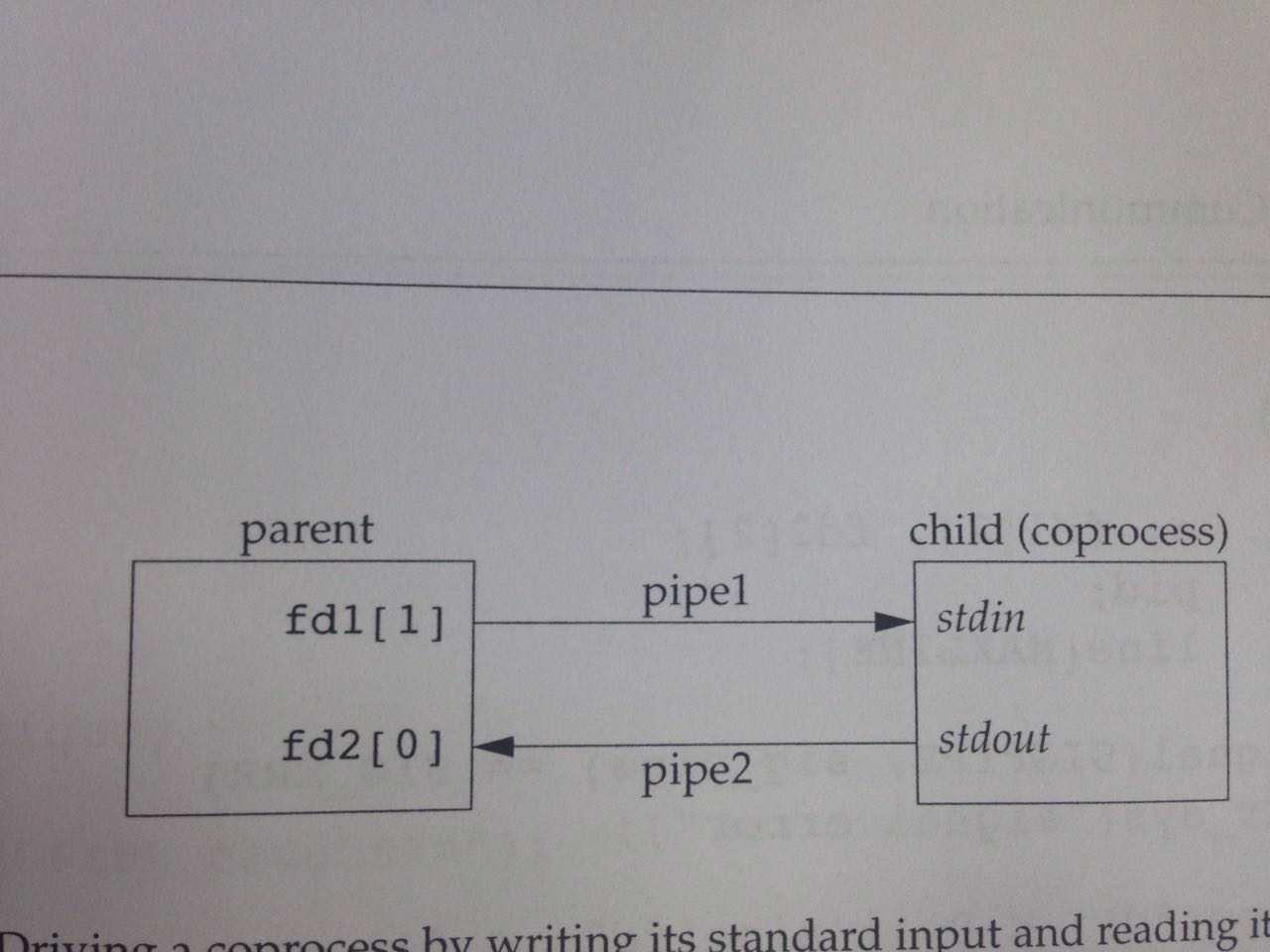
先构造一个2整数加法器如下:
1 #include "apue.h" 2 3 int main(int argc, char *argv[]) 4 { 5 int n, int1, int2; 6 char line[MAXLINE]; 7 8 while ((n=read(STDIN_FILENO, line, MAXLINE))>0) { 9 line[n] = 0; /*null terminate*/ 10 if (sscanf(line, "%d%d", &int1, &int2)==2) { 11 sprintf(line, "%d\n", int1+int2); 12 n = strlen(line); 13 if (write(STDOUT_FILENO, line, n) != n) { 14 err_sys("write error"); 15 } 16 } 17 else { 18 if (write(STDOUT_FILENO, "invalid args\n", 13)!=13) { 19 err_sys("write error"); 20 } 21 } 22 } 23 exit(0); 24 }
这个加法器的作用就是从stdin中读两个整数,做容错处理,加法运算,再写出到stdout中。编译成可执行文件add2。
构造一个进程,利用coprocess的方式,来调用add2处理加法运算。代码如下(除去了书上一些defensive programming的段落,目的是便于把思路捋清楚):
1 #include "apue.h" 2 3 static void sig_pipe(int signo) 4 { 5 if ( signo == SIGPIPE ) 6 { 7 printf("fetch SIGPIPE\n"); 8 } 9 exit(1); 10 } 11 12 int main(int argc, char *argv[]) 13 { 14 int n, fd1[2], fd2[2]; 15 char line[MAXLINE]; 16 pid_t pid; 17 18 signal(SIGPIPE, sig_pipe); 19 pipe(fd1); 20 pipe(fd2); 21 22 if ((pid = fork())<0) { 23 err_sys("fork error"); 24 } 25 else if (pid>0) { /*parent process*/ 26 close(fd1[0]); 27 close(fd2[1]); 28 while (fgets(line,MAXLINE,stdin)!=NULL) { 29 n = strlen(line); 30 if (write(fd1[1],line,n)!=n) { 31 err_sys("write error to pipe"); 32 } 33 if ((n=read(fd2[0], line, MAXLINE))<0) { 34 err_sys("read error from pipe"); 35 } 36 if (n==0) { 37 err_msg("child closed pipe"); 38 break; 39 } 40 line[n] = 0; /*null terminate*/ 41 if (fputs(line ,stdout)==EOF) { 42 err_sys("fputs error"); 43 } 44 } 45 ferror(stdin); 46 exit(0); 47 } 48 else { 49 close(fd1[1]); 50 close(fd2[0]); 51 if (fd1[0]!=STDIN_FILENO) { 52 dup2(fd1[0], STDIN_FILENO); 53 close(fd1[0]); 54 } 55 if (fd2[1]!=STDOUT_FILENO) { 56 dup2(fd2[1], STDOUT_FILENO); 57 close(fd2[1]); 58 } 59 execl("./add2", "add2", (char *)0); 60 } 61 exit(0); 62 }
执行结果如下:
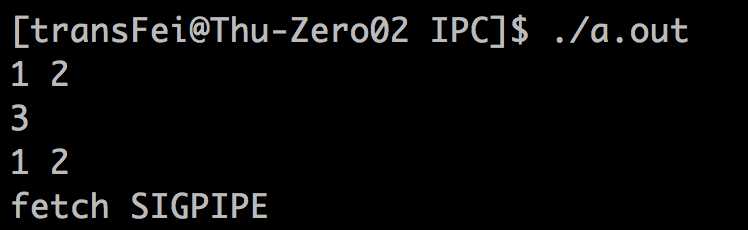
(1)一开始按照coprocess的模型执行两个整数的加法,输入“1 2”返回“3”
(2)然后手工结束add2进程如下:
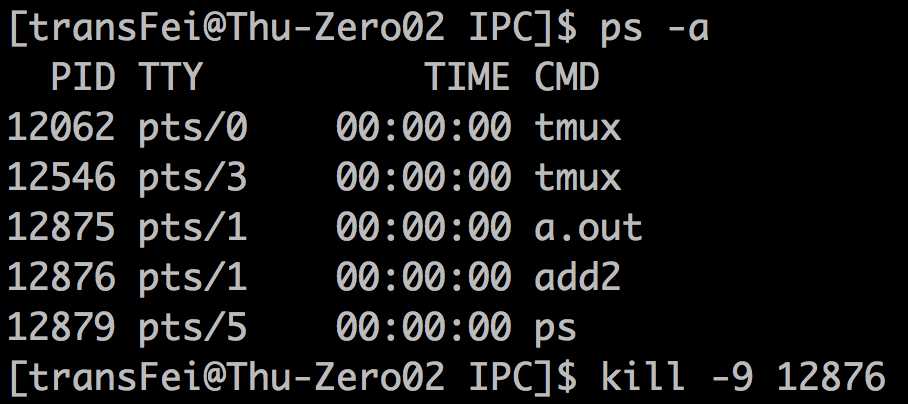
手动结束进程后,pipe的一端已经没有了;因此,a.out的write就触发了SIGPIPE的信号。
这里还有个内容需要注意,add2在实现上用的都是low-level的read和write两个读写函数。
如果把level往上拔一下,换到standard I/O,代码如下:
1 #include "apue.h" 2 3 int main(int argc, char *argv[]) 4 { 5 int int1, int2; 6 char line[MAXLINE]; 7 8 setvbuf(stdin, NULL, _IOLBF, 0); 9 setvbuf(stdout, NULL, _IOLBF, 0); 10 11 while (fgets(line, MAXLINE, stdin)!=NULL) { 12 if (sscanf(line, "%d%d", &int1, &int2)==2) { 13 printf("%d\n", int1+int2); 14 } 15 else { 16 printf("invalid args\n"); 17 } 18 } 19 exit(0); 20 }
则再执行上述的完整流程,完全进行不下去了。
原因可以用一句话来概括:由于standard I/O的buffer机制,使得这种coprocess编程模型出现了deadlock。
由于这种编程模型下,add2自动识别standard input来自于pipe(同理,standard output也被识别为输出到pipe),因此standard I/O默认设置为fully buffered。在这样的背景下,整个program执行的流程如下:
(1)a.out调用write向pipe中写数据
(2)add2调用fgets从pipe中读数据,但是由于是fully buffered,所以不刷新一直读不进来;由于没有读到数据,因此也不会往出写数据
(3)同时,a.out调用完write之后,又马上调用了read;由于read是阻塞函数,所以一直等着pipe的输出
(4)但是(2)中已经说了,add2等着a.out给buffer写满再刷新,同时a.out也等着add2往pipe中写数据。a.out和add2都互相等着对方,最终就造成了deadlock。
如何解决coprocess这种编程模型遇到的问题?
一种方式就是修改源代码,强制为line buffered;但是并不是所有程序都拿的到源代码的,于是就有了另外一种方法,叫pesudo terminal,后面Chapter 19中提到。
15.5 FIFOs
传统的pipes是在ancestor relation processes之间完成IPC,FIFOs则可以在unrelated processes之间完成IPC。
1. FIFOs是一种file,它的创建可以用如下函数:
int mkfifo(const char *path, mode_t mode)
int mkfifoat(int fd, const char *path, mode_t mode)
其用法可以类比open和openat(书上P62)
2. 与pipe类似,如果向FIFOs执行write操作,但是read端已经关闭了,也会发出SIGPIPE信号
3. 同一个FIFOs可以有多个writer向其中写,因此有多个写的atomic问题:与pipe类似,如果每个writer写的数据不大于PIPE_BUF,则FIFOs的实现机制可以保证其同步,不会数据在FIFOs中data interleaved
4. FIFOs的实际用处主要包括两个方面:
(1)shell command用FiFOs技术完成一个pipeline向另一个pipeline传输数据(好处是不用创建临时文件)
(2)CS架构中,client与server数据的交换汇合点
三个例子。
第一例子说明,FIFOs可以在unrelated process之间exchange data,代码:
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <unistd.h> 4 #include <fcntl.h> 5 6 #include <sys/types.h> 7 #include <sys/stat.h> 8 #include <signal.h> 9 #include <errno.h> 10 11 #define PATHNAME "/tmp/myfifo" 12 13 int main(int argc, char *argv[]) 14 { 15 pid_t pid; 16 int fd = -1; 17 char buf[BUFSIZ] = ""; 18 19 mkfifo(PATHNAME, 0644); /*创建一个管道文件*/ 20 fflush(NULL); 21 if ((pid = fork())<0) { 22 exit(1); 23 } 24 else if (pid>0) { /*parent 1*/ 25 pid_t child1 = pid; 26 pid = fork(); 27 if (pid>0) { /*parent 2*/ 28 waitpid(pid, NULL, 0); /*先等着child2执行完*/ 29 } 30 else { /*child 这样就保证两个child没有共同的parent process*/ 31 fd = open(PATHNAME, O_RDWR); /*打开fifo文件, 既能读又能写*/ 32 read(fd, buf, BUFSIZ); /*阻塞读*/ 33 printf("%s",buf); /*读到什么展示一下*/ 34 write(fd, " World!", 8); /*读完了再写点儿东西进去*/ 35 close(fd); 36 exit(0); 37 } 38 waitpid(child1, NULL, 0); /*再等着child1执行完*/ 39 } 40 else { /*child 1*/ 41 fd = open(PATHNAME, O_RDWR); /*打开fifo文件*/ 42 write(fd, "Hello", 6); /*写点儿东西*/ 43 sleep(1); /*停一会儿*/ 44 read(fd, buf, BUFSIZ); /*阻塞读*/ 45 close(fd); 46 puts(buf); /*展示读到了什么*/ 47 remove(PATHNAME); /*把创建的fifo文件删了*/ 48 exit(0); 49 } 50 return 0; 51 }
代码执行结果如下:

上述的代码构造了两个unrelated process,并且通过FIFOs来回写了一次。
第二个例子,pipeline向pipeline之间传数据,shell调用tee命令
mkfifo fifo1
prog3 < fifo1 &
prog1 < infile | tee fifo1 | prog2
上述shell command的实际流程就是下面的图:
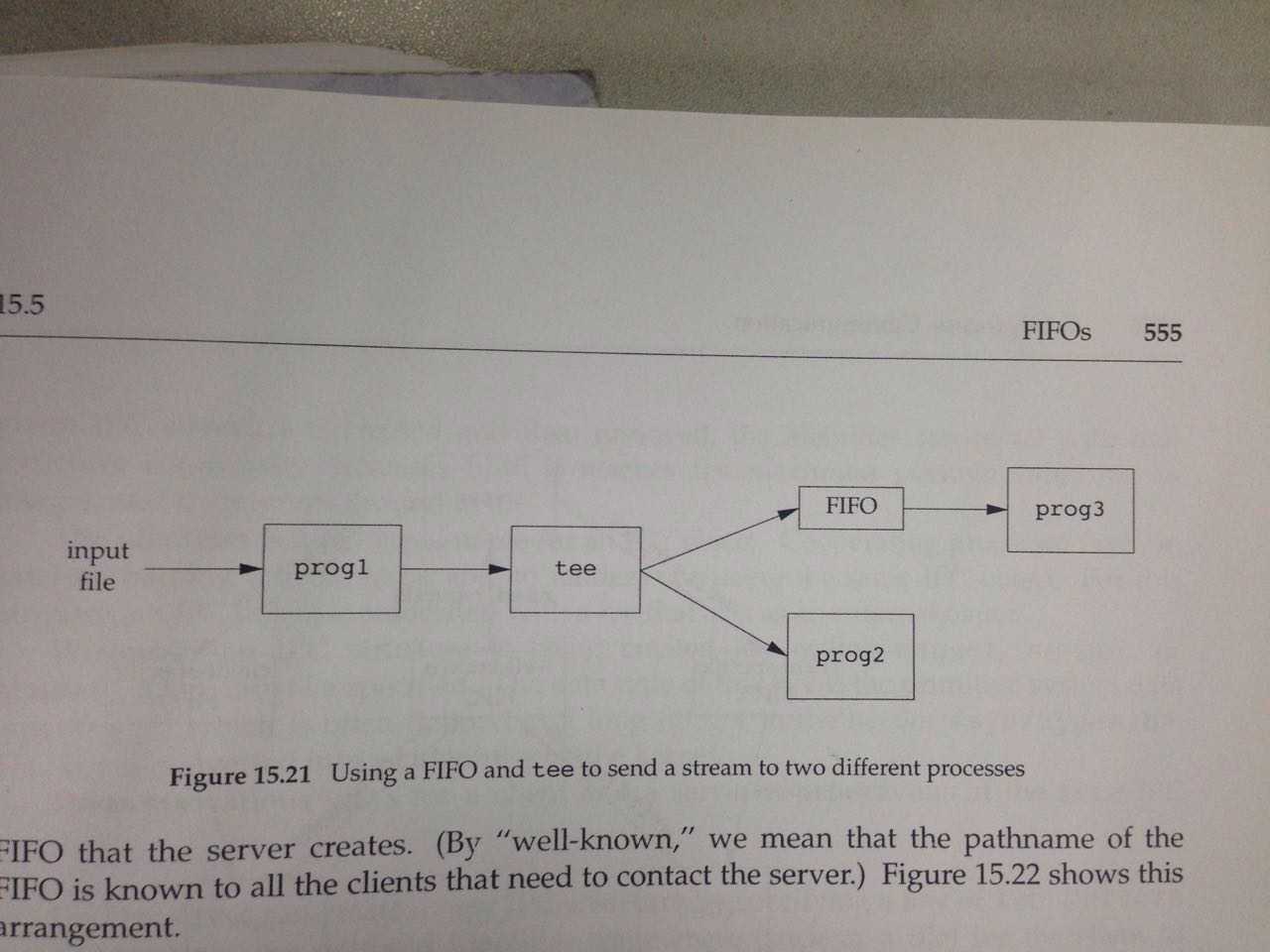
如果没有FIFO这个环节,就只能用临时文件:因为prog3是一个进程,而tee的stdout只能输出prog2,因此tee输出到FIFO就相当于输出到了prog3中。
第三个例子,CS架构的数据汇合节点,如下图所示:
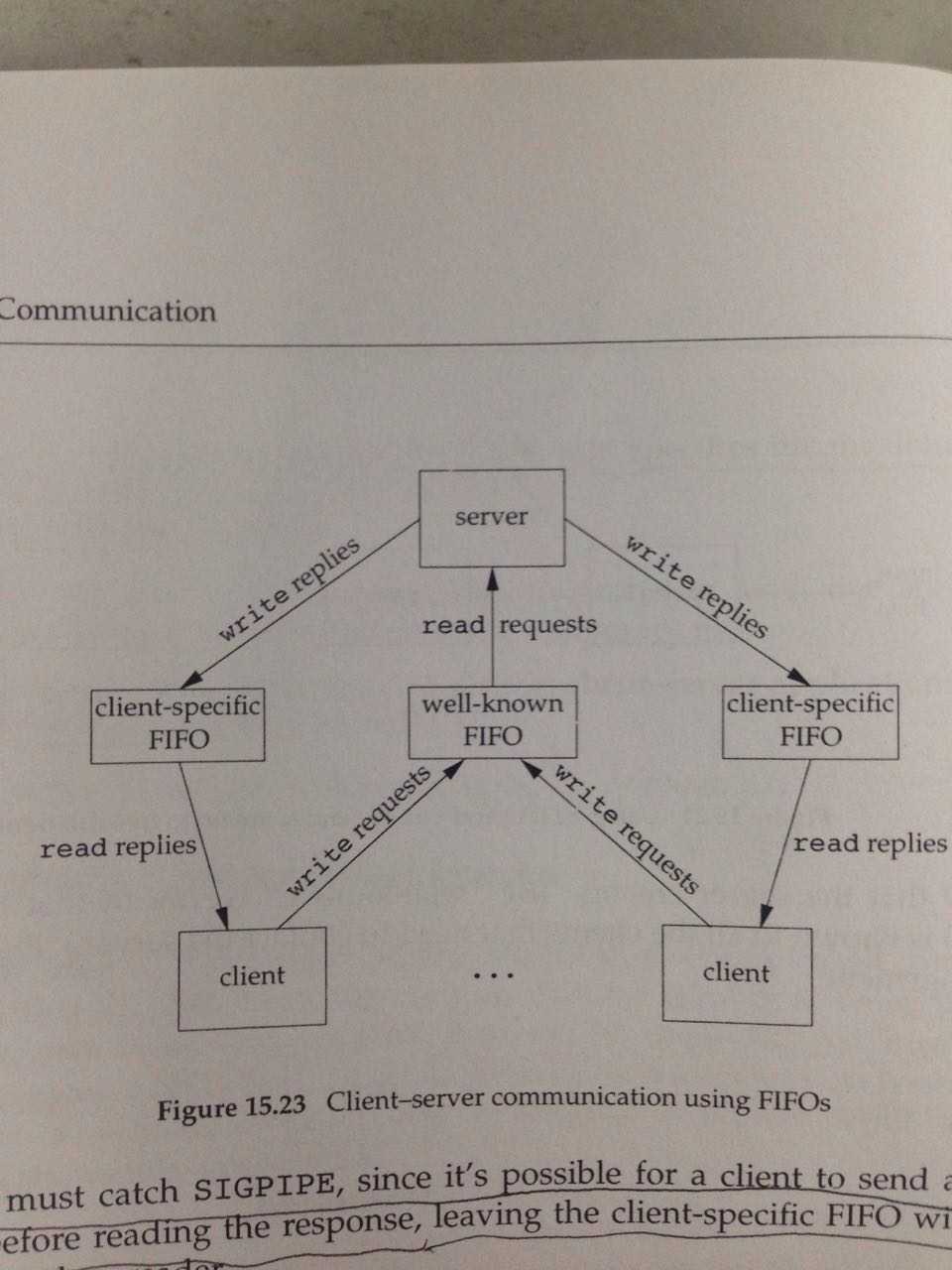
(1)从C向S,通过well-known FIFO
(2)从S向C,server给每个client都分配一个unique FIFO
(3)如果client crash了,server向client执行write的时候,会出发SIGPIPE信号。
15.6 XSI IPC
书上这部分内容比较抽象,讲述的就是XSI IPC三种类型(message queues, semaphores, and shared memory)的共性:
1. Identifiers and Keys:
Keys用于全局唯一标识某种IPC,常用的生成Keys的方式是利用pathname+project ID的方式来生成,具体的函数是ftok函数。
Identifiers依赖于Keys,向msgget函数传入参数Keys来生成Identifier;这个Identifier在进程内部唯一标识某个IPC,具体的函数是msgget函数。
为什么要搞这种内外分开的设计模式?
我猜这是因为方便管理进程对于某个IPC structure的权限管理:Keys的意思是,IPC structure客观上就在那里摆着(由pathname+project ID决定);但是,每个进程中再由Keys生成Identifiers的时候,必须设定相应的权限。通过这样的方式,管理了不同进程对相同IPC structure的不同权限。
2. Permission Structure
通过一个struct ipc_perm中的各项属性来决定。
3. Configuration Limits
这是由kernel管的。
4. Advantages and Disadvantages
没太看懂。
15.7 Message Queues
书上缺少具体的例子,参考下面的blog(http://www.cnblogs.com/chuyuhuashi/p/4475904.html)中的代码例子,模拟一个单机版的Message Queues。
代码分为三个部分:
第一个部分是记录消息队列接口参数以及消息主体结构体的头文件proto.h,如下:
1 #ifndef PROTO_H_ 2 #define PROTO_H_ 3 4 #define NAMESIZE 32 5 6 #define KEYPATH "/tmp/out" 7 8 #define KEYPROJ ‘a‘ 9 10 #define MSGTYPE1 11 11 #define MSGTYPE2 12 12 13 struct msg_st{ 14 long mtype; 15 char name[NAMESIZE]; 16 int chinese; 17 int math; 18 }; 19 20 #endif
第二个部分是消息队列接收部分,reciver.c如下:
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <sys/types.h> 4 #include <sys/ipc.h> 5 #include <sys/msg.h> 6 7 #include "proto.h" 8 9 int main(int argc, char *argv[]) 10 { 11 key_t key; 12 int msgid; 13 struct msg_st rbuf; 14 15 /*创建key 标识从哪个消息队列接收*/ 16 key = ftok(KEYPATH, KEYPROJ); 17 if (key<0) { 18 perror("ftok()"); 19 exit(1); 20 } 21 22 /*reciver创建消息队列*/ 23 msgid = msgget(key, IPC_CREAT|0600); /*0400和0200的合体 具有user-read和user-write的权限*/ 24 if (msgid<0) { 25 perror("msgget()"); 26 exit(1); 27 } 28 29 /*不断从消息队列中接收消息*/ 30 while (1) { 31 /*接收消息*/ 32 if (msgrcv(msgid, &rbuf, sizeof(rbuf)-sizeof(long),0,0)<0) { 33 perror("msgrcv"); 34 exit(1); 35 } 36 /*校验消息类型*/ 37 if (rbuf.mtype == MSGTYPE1) { 38 printf("MSGTYPE1:\n"); 39 printf("name = %s\n", rbuf.name); 40 printf("math = %d\n", rbuf.math); 41 printf("chinese = %d\n", rbuf.chinese); 42 } 43 else if (rbuf.mtype == MSGTYPE2) { 44 printf("MSGTYPE2:\n"); 45 printf("name = %s\n", rbuf.name); 46 printf("math = %d\n", rbuf.math); 47 printf("chinese = %d\n", rbuf.chinese); 48 } 49 else { 50 exit(1); 51 } 52 } 53 54 /*移除消息队列信息*/ 55 msgctl(msgid, IPC_RMID, NULL); 56 exit(0); 57 }
第三部分是向消息队列发送消息的部分,sender.c如下:
#include <stdio.h> #include <stdlib.h> #include <sys/types.h> #include <sys/ipc.h> #include <sys/msg.h> #include <string.h> #include <unistd.h> #include <time.h> #include "proto.h" int main(int argc, char *argv[]) { key_t key; int msgid; struct msg_st sbuf; srand(time(NULL)); /*创建key 用于标识发送到哪个消息队列*/ key = ftok(KEYPATH, KEYPROJ); if (key<0) { perror("ftok()"); exit(1); } /*由于reciver已经创建了以key为标识的消息队列 所以只需要得到msgid即可*/ msgid = msgget(key, 0); if (msgid<0) { perror("msgget()"); exit(1); } /*构建消息主体*/ sbuf.mtype = MSGTYPE1; strcpy(sbuf.name, "type1 sender"); sbuf.math = rand()%100; sbuf.chinese = rand()%100; /*发送消息*/ if (msgsnd(msgid, &sbuf, sizeof(sbuf)-sizeof(long),0)<0) { perror("msgsnd()"); exit(1); } sbuf.mtype = MSGTYPE2; strcpy(sbuf.name, "type2 sender"); sbuf.math = rand()%100; sbuf.chinese = rand()%100; if (msgsnd(msgid, &sbuf, sizeof(sbuf)-sizeof(long),0)<0) { perror("msgsnd()"); exit(1); } /*发送完毕*/ puts("ok!"); exit(0); }
执行结果如下:
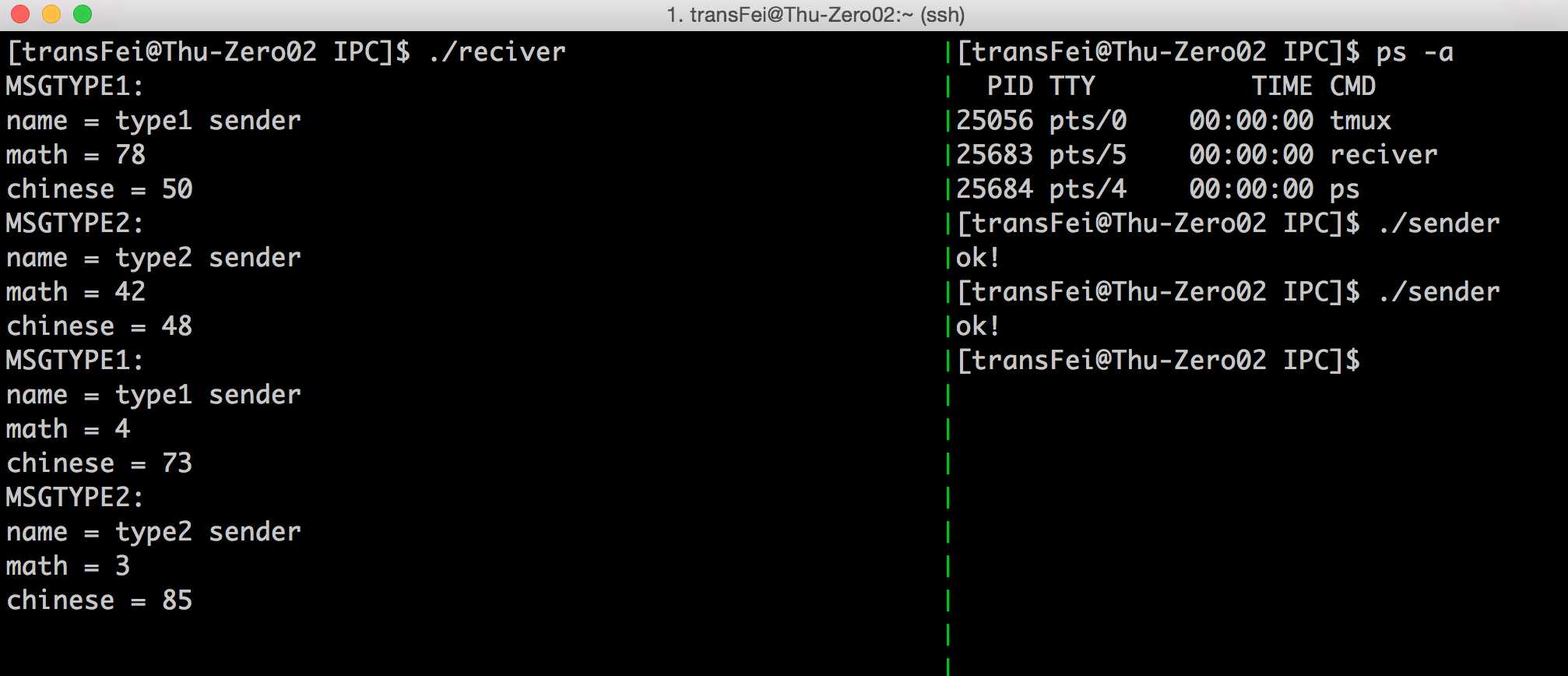
操作流程如下:
(1)先启动./reciver(ps -a查看,确实有reciver再运行),建立消息队列并不断做好准备从消息队列中循环接收消息。
(2)启动./sender ,向reciver建立的消息队列中发送消息。
(3)reciver通过消息队列接收到了sender发来的消息,做出响应并输出结果
上面的流程,就是典型的消息队列通信流程,其中涉及到如下几个关键函数:
1. ftok函数
key_t ftok(const char *path, int id)
函数的作用是根据输入参数获得唯一的标示某个消息队列的key_t型变量。
一个消息队列必须对应唯一的key_t;如果reciver和sender想要对应同一个消息队列,reciver和sender就必须用同样的path和id作为参数,生成key_t。path和id就是定义在proto.h中的两个宏:
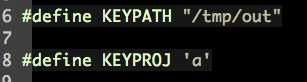
注意。这里的KEYPATH所指的文件必须是存在的,如果不存在,则会报错。
2. msgget函数
int msgget(key_t key, int flag)
打开或者创建一个消息队列。如果消息队列不存在,就创建之;如果存在了,就打开之。
其中key就是就ftok生成的唯一标识消息队列的key_t类型变量;flag其中一个作用是控制权限,以及消息队列的打开模式。
函数的返回值是int型,就是前面提到的消息队列identifier。在process内部的所有对消息队列的进一步操作,都用msgid来唯一标识这个消息队列。
3. msgrcv函数
ssize_t msgrcv(int msqid, void *ptr, size_t nbytes, long type, int flag)
用于消息队列接收端,接受消息。
msqid:进程中由msgget产生的消息队列进程内唯一id,即告诉从哪个进程接受消息。
ptr:指向一个long类型的地址,即告诉消息从消息队列中读完之后存到哪里。上述代码中是一个结构体,即消息队列中每个消息的定义结构,reciver和sender都要知道这个结构才能使IPC通信完成。
nbytes:ptr所指的long类型再往后读多少bytes的消息数据内容;默认每个消息的开头都是long类型,这个long类型只表征消息的类型,不涉及到消息的内容;跳过这个long的大小之后,紧接着的都是消息内容,这个nbytes表征了读多少消息内容。
type:等于0标示读消息队列中最近一个消息;大于0表示,只读最近一个type=ptr所指向的long变量类型的值(在这里就是mtype的值);小于0也有其对应的意义。
flag:有一个重要属性是IPC_NOWAIT;正常msgrcv这个函数是阻塞的,即干等着收到消息才返回;如果在flag中设置了IPC_NOWAIT这个标志位,则不会干等着,一旦没有马上获取消息队列中的消息,就马上返回了,并且将errno设置为EIDRM。即,默认不改动flag情况下,msgrcv是一个阻塞函数:每次就从消息队列中读那么多,读到了才算完事儿,否则就干等着。
函数的返回值是从消息的数据部分(不包括long类型的mtype)。
这里有关ptr结构体成员的定义是有严格要求的:第一个成员必须是long类型的mtype,并且必须是大于0的值。为什么这样?这几个函数就是这么协定的。即完整的消息结构必须是:“long表示的消息类型+紧跟着的消息数据内容”
4. msgsnd函数
int msgsnd(int msqid, const void *ptr, size_t nbytes, int flag)
与3相同的几个参数不再赘述。
flag的设置也可以设为IPC_NOWAIT;不同的在于如果没有立刻向队列中发出去消息,则将errno设为EAGAIN,表示资源繁忙。
5. msgctl函数
int msgctl(int msqid, int cmd, struct msqid_ds *buf)
这是个消息队列的管家函数。
cmd可以取值为 {IPC_STAT,IPC_SET,IPC_RMID}
根据cmd不同取值,执行不同的功能。上述代码中执行的是删除功能。
15.8 Semaphores
信号量是一个“counter used to provide access to a shared data object for multiple processes”。即保证多进程对于shared data object进行同步操作。APUE的作者对XSI IPC的semaphore的评价并不是很高,使用上比较复杂,并且有时候容易遇到各种坑。
通过一个例子,来说明semaphore的一般用法,代码如下;
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <string.h> 4 #include <unistd.h> 5 #include <sys/wait.h> 6 #include <sys/types.h> 7 #include <sys/ipc.h> 8 #include <sys/sem.h> 9 #include <errno.h> 10 11 #define PROCNUM 10 12 #define FNAME "/tmp/out" 13 #define BUFSIZE 1024 14 15 static int semid; /*所有的进程都要访问的资源 且不会被修改*/ 16 17 static void P(int sem_index){ 18 struct sembuf op; 19 op.sem_num = sem_index; /*semid标定的semaphore set中具体第sem_index下标的那个semaphore*/ 20 op.sem_op = -1; /*申请占用1个资源*/ 21 op.sem_flg = 0; /*没有特殊要求*/ 22 while (semop(semid,&op,1)<0) { /*这里的‘1‘指的是从&op这个地址往后取几个struct sembuf*/ 23 if (errno!=EINTR && errno!=EAGAIN) { 24 perror("semop()"); 25 exit(1); 26 } 27 } 28 } 29 30 static void V(int sem_index){ 31 struct sembuf op; 32 op.sem_num = sem_index; 33 op.sem_op = 1; /*释放1个资源*/ 34 op.sem_flg = 0; 35 while (semop(semid,&op,1)<0) { 36 if (errno!=EINTR && errno!=EAGAIN) { 37 perror("semop()"); 38 exit(1); 39 } 40 } 41 } 42 43 static void func_add(){ 44 FILE *fp; 45 char buf[BUFSIZE]; 46 fp = fopen(FNAME, "r+"); /*所有child process都可以打开FNAME*/ 47 /*并且所有的child process都必须按照套路出牌 先敲门再访问*/ 48 P(0); /*占用资源*/ 49 P(1); 50 fgets(buf, BUFSIZE, fp); 51 rewind(fp); 52 sleep(1); 53 fprintf(fp,"%d\n",atoi(buf)+1); 54 fflush(fp); 55 V(1); 56 V(0); /*释放资源*/ 57 fclose(fp); 58 } 59 60 int main(int argc, char *argv[]){ 61 int i; 62 pid_t pid; 63 /*由于都是在亲缘关系的process之间 因此可以用IPC_PRIVATE宏生成semid*/ 64 semid = semget(IPC_PRIVATE, 2, 0600); /*创建两个semaphore*/ 65 if (semid<0) { 66 perror("segment()"); 67 exit(1); 68 } 69 if (semctl(semid,0,SETVAL,1)<0) { /*设置semaphore[0]资源数量是1*/ 70 perror("semctl()"); 71 exit(1); 72 } 73 if (semctl(semid,1,SETVAL,1)<0) { /*设置semaphore[1]资源的数量是1*/ 74 perror("semctl()"); 75 exit(1); 76 } 77 /*fork出20个子进程*/ 78 for (i=0; i<PROCNUM; i++){ 79 pid = fork(); 80 if (pid==0) { /*每次在child process中执行对semaphore的操作*/ 81 func_add(); 82 exit(0); 83 } 84 } 85 for(i=0; i<PROCNUM; i++) /*等着fork出来的所有child都返回完成了*/ 86 wait(NULL); 87 semctl(semid, 0, IPC_RMID); /*移除这个semaphore*/ 88 exit(0); 89 }
代码执行到功能,是10个进程向同一个文件(/tmp/out)中累加数据,用信号量的方式对多进程操作同步。
有了前面消息队列的基础,对semaphore的几个函数梳理如下:
1. semget函数
int segmet(key_t key, int nsems, int flag)
创建信号量
key : 喂给这个函数key(这个key是不同进程中唯一标示semaphore的,上面的例子中,由于各个process都是由一个parent fork出来的,属于亲属关系,因此用IPC_PRIVATE作为key即可)
nsems : 创建信号量的数量(上述代码是2个)
flag:一些特殊要求设置flag位
函数的返回值在是semaphore在进程内部的唯一标示
2. semctl函数
信号量的管理函数
int semctl(int semid, int semnum, int cmd, ... /* union semun arg */)
semid : 进程内部唯一标示semaphore的identifier
semnum : 这个变量有点别扭,即semid标示的是一个semaphore数组,semnum指的是这个数组中的semaphore下标(在上面的代码中由于semid标示的数组总共有两个semaphore资源,所以这里semnum可以取值为{0,1})。
cmd : 要对某个semaphore执行的具体操作(上述代码中是SETVAL,即只对一个semaphore资源操作)
3. semop函数
int semop(int semid, struct sembuf semop_array[], size_t nops)
对信号量操作
semid:同上
semop_array:struct sembuf类型的结构体数组指针,每个结构体中存放着要对semid所指向的某个semaphore的操作信息。
struct sembuf{ unsigned short sem_num; /*semid标定的semaphore数组中的元素下标*/ short sem_op; /*正几就是占用几个资源 负几就是释放几个资源 0代表等着资源是0*/ short sem_flg; /*特殊要求 设置flag位*/ }
nops:代表semop_array的数量,到底有多少个op需要加在semaphore上面
15.9 Shared Memory
优点就是速度快,缺点是同步起来麻烦,得借助信号量之类的。
这种shared memory不像之前的消息队列或信号量,没有显式的文件名。
通过shared memory这种方式可以方便的在parent process和child process之间通信。
直接看一个列子:
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <sys/mman.h> 4 #include <sys/types.h> 5 #include <sys/stat.h> 6 #include <unistd.h> 7 #include <fcntl.h> 8 #include <string.h> 9 #include <sys/ipc.h> 10 #include <sys/shm.h> 11 #include <sys/wait.h> 12 13 #define MEMSIZE 1024 14 15 int main(int argc, char *argv[]) 16 { 17 char *ptr; 18 pid_t pid; 19 int shmid; 20 21 shmid = shmget(IPC_PRIVATE, MEMSIZE, 0600); 22 23 if ((pid=fork())<0) { 24 perror("fork()"); 25 } 26 else if (pid==0) { /*child process*/ 27 ptr = shmat(shmid, NULL, 0); 28 printf("CHILD : shared memory from %p to %p\n", (void*)ptr, (void*)ptr+MEMSIZE); 29 fflush(stdout); 30 strcpy(ptr, "hello"); 31 shmdt(ptr); 32 exit(0); 33 } 34 else { /*parent process*/ 35 wait(NULL); 36 ptr = shmat(shmid, NULL, 0); 37 printf("PARENT : shared memory from %p to %p\n", (void*)ptr, (void*)ptr+MEMSIZE); 38 puts(ptr); 39 shmdt(ptr); 40 shmctl(shmid, IPC_RMID, NULL); 41 exit(0); 42 } 43 }
上述代码开辟了一段shared memory(line21);child process向这段shared memory写入“hello"字符串;parent process从这段shared memory读入内容再输出到terminal上。运行结果如下:

shared memory的关键在于:
(1)shmget函数:负责理出来一块memroy专门用于shared memory,仅仅是理出来这么一块memory,并且生成了shmid这个identifier,唯一标识这块shared memory。
(2)shmat函数:shmget函数整理出来的shared memory还不能够被其他process访问,而shmat做的事情就是启动当前process对这段shared memory的访问,把这段shared memory对接到当前process的memory space上,并返回这段共享内存在当前process中的起始地址,即上述代码中的ptr。child process和parent process中的ptr相当于这段shared memory的代言人。
乍看上述代码的输出,为什么child和parent中的ptr的值都相同呢?分析一下不难得出结论:
这个地址绝对不是shared memory的实际地址,而是这段shared memory在child和process内部各自的地址代言人。既然各自process中的代言人,为什么还相同呢?原因有两个:
(1)ptr的产生方式都是 ptr = shmat(shmid ,0 ,0) 即让系统的算法自动给这段shared memory在当前process的memory layout中找到first avalialbe的地址。
(2)parent process通过fork的方式产生child process,则child与process在memory layout上完全copy过去的。因此,按照(1)中提到的方法,在child和parent的内部获得的地址一定是相同的。
【APUE】Chapter15 Interprocess Communication
标签:
原文地址:http://www.cnblogs.com/xbf9xbf/p/5018177.html