标签:
http://blog.csdn.net/wuxinke_blog/article/details/8769131
有这么一系列的问题,是否在困扰着你:用户程序编译连接形成的地址空间在什么范围内?内核编译后地址空间在什么范围内?要对外设进行访问,I/O的地址空间又是什么样的?
先 回答第一个问题。Linux最常见的可执行文件格式为elf(Executable and LinkableFormat)。在elf格式的可执行代码中,ld总是从0x8000000开始安排程序的“代码段”,对每个程序都是这样。至于程序执行时在物理内存中的实际地址,则由内核为其建立内存映射时临时分配,具体地址取决于当时所分配的物理内存页面。
我们可以用Linux的实用程序objdump对你的程序进行反汇编,从而知晓其地址范围。
例如:假定我们有一个简单的C程序Hello.c
# include<stdio.h>
greeting ( )
{
printf(“Hello,world!\n”);
}
main()
{
greeting();
}
之所以把这样简单的程序写成两个函数,是为了说明指令的转移过程。我们用gcc和ld对其进行编译和连接,得到可执行代码hello。然后,用Linux的实用程序objdump对其进行反汇编:
$objdump –d hello
得到的主要片段为:
08048568 <greeting>:
8048568: pushl ?p
8048569: movl %esp, ?p
804856b: pushl $0x809404
8048570: call 8048474 <_init+0x84>
8048575: addl $0x4, %esp
8048578: leave
8048579: ret
804857a: movl %esi, %esi
0804857c <main>:
804857c: pushl ?p
804857d: movl %esp, ?p
804857f: call 8048568 <greeting>
8048584: leave
8048585: ret
8048586: nop
8048587: nop
其中,像08048568这样的地址,就是我们常说的虚地址(这个地址实实在在的存在,只不过因为物理地址的存在,显得它是“虚”的罢了)。
.虚拟内存、内核空间和用户空间
Linux虚拟内存的大小为2^32(在32位的x86机器上),内核将这4G字节的空间分为两部分。最高的1G字节(从虚地址0xC0000000到0xFFFFFFFF)供内核使用,称为“内核空间”。而较低的3G字节(从虚地址0x00000000到0xBFFFFFFF),供各个进程使用,称为“用户空间”。因为每个进程可以通过系统调用进入内核,因此,Linux内核空间由系统内的所有进程共享。于是,从具体进程的角度来看,每个进程可以拥有4G字节的虚拟地址空间(也叫虚拟内存)。
每个进程有各自的私有用户空间(0~3G),这个空间对系统中的其他进程是不可见的。最高的1GB内核空间则为所有进程以及内核所共享。另外,进程的“用户空间”也叫“地址空间”,在后面的叙述中,我们对这两个术语不再区分。
用户空间不是进程共享的,而是进程隔离的。每个进程最大都可以有3GB的用户空间。一个进程对其中一个地址的访问,与其它进程对于同一地址的访问绝不冲突。比如,一个进程从其用户空间的地址0x1234ABCD处可以读出整数8,而另外一个进程从其用户空间的地址0x1234ABCD处可以读出整数20,这取决于进程自身的逻辑。
任意一个时刻,在一个CPU上只有一个进程在运行。所以对于此CPU来讲,在这一时刻,整个系统只存在一个4GB的虚拟地址空间,这个虚拟地址空间是面向此进程的。当进程发生切换的时候,虚拟地址空间也随着切换。由此可以看出,每个进程都有自己的虚拟地址空间,只有此进程运行的时候,其虚拟地址空间才被运行它的CPU所知。在其它时刻,其虚拟地址空间对于CPU来说,是不可知的。所以尽管每个进程都可以有4GB的虚拟地址空间,但在CPU眼中,只有一个虚拟地址空间存在。虚拟地址空间的变化,随着进程切换而变化。
从上面我们知道,一个程序编译连接后形成的地址空间是一个虚拟地址空间,但是程序最终还是要运行在物理内存中。因此,应用程序所给出的任何虚地址最终必须被转化为物理地址,所以,虚拟地址空间必须被映射到物理内存空间中,这个映射关系需要通过硬件体系结构所规定的数据结构来建立。这就是我们所说的段描述符表和页表,Linux主要通过页表来进行映射。
于是,我们得出一个结论,如果给出的页表不同,那么CPU将某一虚拟地址空间中的地址转化成的物理地址就会不同。所以我们为每一个进程都建立其页表,将每个进程的虚拟地址空间根据自己的需要映射到物理地址空间上。既然某一时刻在某一CPU上只能有一个进程在运行,那么当进程发生切换的时候,将页表也更换为相应进程的页表,这就可以实现每个进程都有自己的虚拟地址空间而互不影响。所以,在任意时刻,对于一个CPU来说,只需要有当前进程的页表,就可以实现其虚拟地址到物理地址的转化。
.内核空间到物理内存的映射
内核空间对所有的进程都是共享的,其中存放的是内核代码和数据,而进程的用户空间中存放的是用户程序的代码和数据,不管是内核程序还是用户程序,它们被编译和连接以后,所形成的指令和符号地址都是虚地址(参见2.5节中的例子),而不是物理内存中的物理地址。
虽然内核空间占据了每个虚拟空间中的最高1GB字节,但映射到物理内存却总是从最低地址(0x00000000)开始的,如图4.2所示,之所以这么规定,是为了在内核空间与物理内存之间建立简单的线性映射关系。其中,3GB(0xC0000000)就是物理地址与虚拟地址之间的位移量,在Linux代码中就叫做PAGE_OFFSET。
我们来看一下在include/asm/i386/page.h头文件中对内核空间中地址映射的说明及定义:
#define __PAGE_OFFSET (0xC0000000)
……
#define PAGE_OFFSET ((unsignedlong)__PAGE_OFFSET)
#define __pa(x) ((unsignedlong)(x)-PAGE_OFFSET)
#define __va(x) ((void*)((unsigned long)(x)+PAGE_OFFSET))
对于内核空间而言,给定一个虚地址x,其物理地址为“x- PAGE_OFFSET”,给定一个物理地址x,其虚地址为“x+PAGE_OFFSET”。
这里再次说明,宏__pa()仅仅把一个内核空间的虚地址映射到物理地址,而决不适用于用户空间,用户空间的地址映射要复杂得多,它通过分页机制完成。
内核空间为3GB~4GB,这1GB的空间分为如下几部分,如图1所示: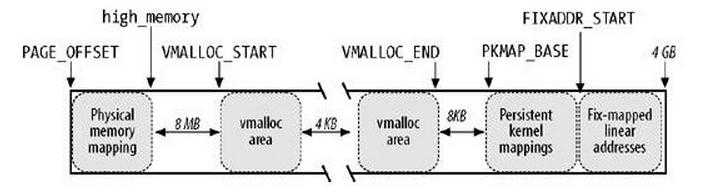
先说明图中符号的含义:
PAGE_OFFSET:0XC0000000,即3GB
high_memory:这个变量的字面含义是高端内存,到底什么是高端内存,Linux内核规定,RAM的前896为所谓的低端内存,而896~1GB共128MB为高端内存。如果你的内存是512M,那么high_memory是多少?是3GB+512,也就是说,物理地址x<=896M,就有内核地址0xc0000000+x,否则,high_memory=0xc0000000+896M
或者说high_memory最大值为0xc0000000+896M ,实际值为0xc0000000+x
在源代码中函数mem_init中,有这样一行:
high_memory = (void *) __va(max_low_pfn * PAGE_SIZE);
其中,max_low_pfn为物理内存的最大页数。
所以在图中,PAGE_OFFSET到high_memory之间就是所谓的物理内存映射。只有这一段之间,物理地址与虚地址之间是简单的线性关系。
还要说明的是,要在这段内存分配内存,则调用kmalloc()函数。反过来说,通过kmalloc()分配的内存,其物理页是连续的。
VMALLOC_START:非连续区的的起始地址。
VMALLOC_END:非连续区的的末尾地址
在非连续区中,物理内存映射的末端与第一个VMalloc之间有一个8MB的安全区,目的是为了“捕获”对内存的越界访问。处于同样的理由,插入其他4KB的安全区来隔离非连续区。
非连续区的分配调用VMalloc()函数。
vmalloc()与 kmalloc()都是在内核代码中用来分配内存的函数,但二者有何区别?
从前面的介绍已经看出,这两个函数所分配的内存都处于内核空间,即从3GB~4GB;但位置不同,kmalloc()分配的内存处于3GB~high_memory之间,这一段内核空间与物理内存的映射一一对应,而vmalloc()分配的内存在VMALLOC_START~4GB之间,这一段非连续内存区映射到物理内存也可能是非连续的。
vmalloc()工作方式与kmalloc()类似,其主要差别在于前者分配的物理地址无需连续,而后者确保页在物理上是连续的(虚地址自然也是连续的)。
尽管仅仅在某些情况下才需要物理上连续的内存块,但是,很多内核代码都调用kmalloc(),而不是用vmalloc()获得内存。这主要是出于性能的考虑。vmalloc()函数为了把物理上不连续的页面转换为虚拟地址空间上连续的页,必须专门建立页表项。还有,通过vmalloc()获得的页必须一个一个的进行映射(因为它们物理上不是连续的),这就会导致比直接内存映射大得多的缓冲区刷新。因为这些原因,vmalloc()仅在绝对必要时才会使用——典型的就是为了获得大块内存时,例如,当模块被动态插入到内核中时,就把模块装载到由vmalloc()分配的内存上。
vmalloc()函数用起来比较简单:
char *buf;
buf =vmalloc(16*PAGE_SIZE);
if (!buf)
在使用完分配的内存之后,一定要释放它:
vfree(buf);
1.I/O端口和I/O内存
设备驱动程序要直接访问外设或其接口卡上的物理电路,这部分通常都是以寄存器的形式出现。外设寄存器也称为I/O端口,通常包括:控制寄存器、状态寄存器和数据寄存器三大类。根据访问外设寄存器的不同方式,可以把CPU分成两大类。一类CPU(如M68K,PowerPC等)把这些寄存器看作内存的一部分,寄存器参与内存统一编址,访问寄存器就通过访问一般的内存指令进行,所以,这种CPU没有专门用于设备I/O的指令。这就是所谓的“I/O内存”方式。另一类CPU(典型地如X86)将外设的寄存器看成一个独立的地址空间,所以访问内存的指令不能用来访问这些寄存器,而要为对外设寄存器的读/写设置专用指令,如IN和OUT指令。这就是所谓的” I/O端口”方式。但是,用于I/O指令的“地址空间”相对来说是很小的。事实上,现在x86的I/O地址空间已经非常拥挤。
但是,随着计算机技术的发展,单纯的I/O端口方式无法满足实际需要了,因为这种方式只能对外设中的几个寄存器进行操作。而实际上,需求在不断发生变化,例如,在PC上可以插上一块图形卡,有2MB的存储空间,甚至可能还带有ROM,其中装有可执行代码。自从PCI总线出现后,不管是CPU的设计采用I/O端口方式还是I/O内存方式,都必须将外设卡上的存储器映射到内存空间,实际上是采用了虚存空间的手段,这样的映射是通过ioremap()来建立的。
2. 访问I/O端口
in、out、ins和outs汇编语言指令都可以访问I/O端口。内核中包含了以下辅助函数来简化这种访问:
inb( )、inw( )、inl( )
分别从I/O端口读取1、2或4个连续字节。后缀“b”、“w”、“l”分别代表一个字节(8位)、一个字(16位)以及一个长整型(32位)。
inb_p( )、inw_p( )、inl_p( )
分别从I/O端口读取1、2或4个连续字节,然后执行一条“哑元(dummy,即空指令)”指令使CPU暂停。
outb( )、outw( )、outl( )
分别向一个I/O端口写入1、2或4个连续字节。
outb_p( )、outw_p( )、outl_p( )
分别向一个I/O端口写入1、2或4个连续字节,然后执行一条“哑元”指令使CPU暂停。
insb( )、insw( )、insl( )
分别从I/O端口读入以1、2或4个字节为一组的连续字节序列。字节序列的长度由该函数的参数给出。
outsb( )、outsw( )、outsl( )
分别向I/O端口写入以1、2或4个字节为一组的连续字节序列。
虽然访问I/O端口非常简单,但是检测哪些I/O端口已经分配给I/O设备可能就不这么简单了,对基于ISA总线的系统来说更是如此。通常,I/O设备驱动程序为了探测硬件设备,需要盲目地向某一I/O端口写入数据;但是,如果其他硬件设备已经使用这个端口,那么系统就会崩溃。为了防止这种情况的发生,内核必须使用“资源”来记录分配给每个硬件设备的I/O端口。
资源表示某个实体的一部分,这部分被互斥地分配给设备驱动程序。在这里,资源表示I/O端口地址的一个范围。每个资源对应的信息存放在resource数据结构中:
struct resource {
resource_size_t start;
resource_size_t end;
const char *name;
unsigned long flags;
struct resource *parent,*sibling, *child;
};
其字段如表1所示。所有的同种资源都插入到一个树型数据结构(父亲、兄弟和孩子)中;例如,表示I/O端口地址范围的所有资源都包括在一个根节点为ioport_resource的树中。
表1: resource数据结构中的字段
类型 字段 描述
const char * name
资源拥有者的名字
unsigned long
start
资源范围的开始
unsigned long
end
资源范围的结束
unsigned long
flags
各种标志
struct resource *
parent
指向资源树中父亲的指针
struct resource *
sibling
指向资源树中兄弟的指针
struct resource *
child
指向资源树中第一个孩子的指针
节点的孩子被收集在一个链表中,其第一个元素由child指向。sibling字段指向链表中的下一个节点。
为 什么使用树?例如,考虑一下IDE硬盘接口所使用的I/O端口地址-比如说从0xf000 到0xf00f。那么,start字段为0xf000 且end字段为0xf00f的这样一个资源包含在树中,控制器的常规名字存放在name字段中。但是,IDE设备驱动程序需要记住另外的信息,也就是IDE链主盘使用0xf000 到 0xf007的子范围,从盘使用0xf008 到0xf00f的子范围。为了做到这点,设备驱动程序把两个子范围对应的孩子插入到从0xf000 到0xf00f的整个范围对应的资源下。一般来说,树中的每个节点肯定相当于父节点对应范围的一个子范围。I/O端口资源树(ioport_resource)的根节点跨越了整个I/O地址空间(从端口0到65535)。
任何设备驱动程序都可以使用下面三个函数,传递给它们的参数为资源树的根节点和要插入的新资源数据结构的地址:
request_resource( )
把一个给定范围分配给一个I/O设备。
allocate_resource( )
在资源树中寻找一个给定大小和排列方式的可用范围;若存在,将这个范围分配给一个I/O设备(主要由PCI设备驱动程序使用,可以使用任意的端口号和主板上的内存地址对其进行配置)。
release_resource( )
释放以前分配给I/O设备的给定范围。
内 核也为以上函数定义了一些应用于I/O端口的快捷函数:request_region()分配I/O端口的给定范围,release_region()释放以前分配给I/O端口的范围。当前分配给I/O设备的所有I/O地址的树都可以从/proc/ioports文件中获得。
3.把I/O端口映射到内存空间-访问I/O端口的另一种方式
映射函数的原型为:
void *ioport_map(unsigned long port, unsigned int count);
通过这个函数,可以把port开始的count个连续的I/O端口重映射为一段“内存空间”。然后就可以在其返回的地址上像访问I/O内存一样访问这些I/O端口。
但请注意,在进行映射前,还必须通过request_region( )分配I/O端口。
当不再需要这种映射时,需要调用下面的函数来撤消:
void ioport_unmap(void *addr);
在设备的物理地址被映射到虚拟地址之后,尽管可以直接通过指针访问这些地址,但是工程师宜使用Linux内核的如下一组函数来完成访问I/O内存:·读I/O内存
unsigned int ioread8(void *addr);
unsigned int ioread16(void *addr);
unsigned int ioread32(void *addr);
与上述函数对应的较早版本的函数为(这些函数在Linux 2.6中仍然被支持):
unsigned readb(address);
unsigned readw(address);
unsigned readl(address);
·写I/O内存
void iowrite8(u8 value, void *addr);
void iowrite16(u16 value, void *addr);
void iowrite32(u32 value, void *addr);
与上述函数对应的较早版本的函数为(这些函数在Linux 2.6中仍然被支持):
void writeb(unsigned value, address);
void writew(unsigned value, address);
void writel(unsigned value, address);
4. 访问I/O内存
Linux内核也提供了一组函数申请和释放某一范围的I/O内存:
struct resource*requset_mem_region(unsigned long start, unsigned long len,char*name);
这个函数从内核申请len个内存地址(在3G~4G之间的虚地址),而这里的start为I/O物理地址,name为设备的名称。注意,。如果分配成功,则返回非NULL,否则,返回NULL。
另外,可以通过/proc/iomem查看系统给各种设备的内存范围。
要释放所申请的I/O内存,应当使用release_mem_region()函数:
voidrelease_mem_region(unsigned long start, unsigned long len)
申请一组I/O内存后, 调用ioremap()函数:
void * ioremap(unsigned long phys_addr, unsigned long size,unsigned long flags);
其中三个参数的含义为:
phys_addr:与requset_mem_region函数中参数start相同的I/O物理地址;
size:要映射的空间的大小;
flags:要映射的IO空间的和权限有关的标志;
功能: 将一个I/O地址空间映射到内核的虚拟地址空间上(通过release_mem_region()申请到的)
为什么要申请虚拟内存然后才进行映射?
————————————————————————————————————
留给读者的思考:直接访问I/O端口、把I/O端口映射到内存进行访问,以及访问I/O内存,三者之间有什么区别,在驱动程序开发中如何具体应用?
标签:
原文地址:http://www.cnblogs.com/losing-1216/p/5035423.html