标签:
相信大家在很多时候都遇见过乱码的问题,比如在浏览网页时,某个网页出现了乱码;做开发时,传递的数值在网页上乱码等等。
那么今天就跟大家分享一下文件的乱码问题。
很多时候出现乱码的根本原因就是:文件编码方式与浏览器解析方式出现了冲突 或者 是我们编写的文件在转换时出现编码不一致,使得乱码问题出现。要想处理这种乱码问题,我们首先就得先了解一下编码的方式种类。我这里就举一个小例子供大家了解乱码的根本原因所在。
文件编码方式与浏览器解析方式出现冲突:
这个首页采取的是utf-8编码方式:
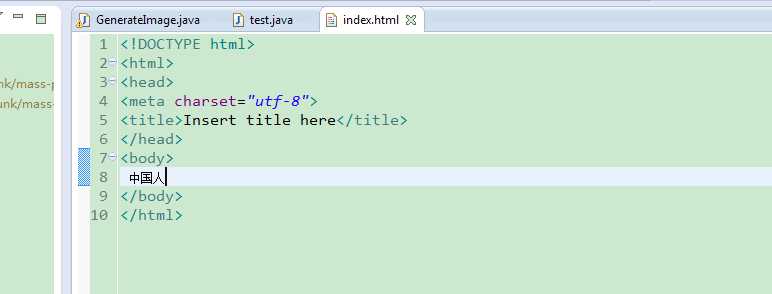
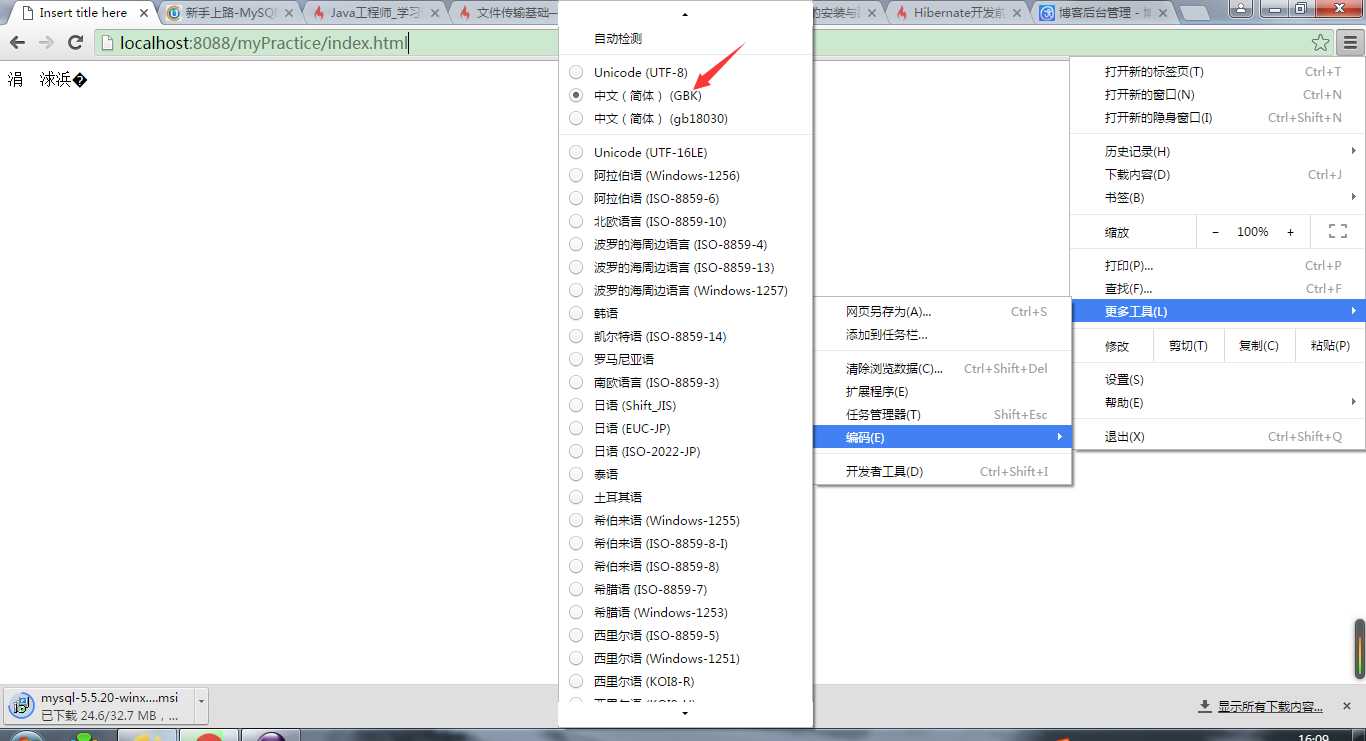
下面分别是浏览器采取utf-8、gbk编码方式显示页面的结果: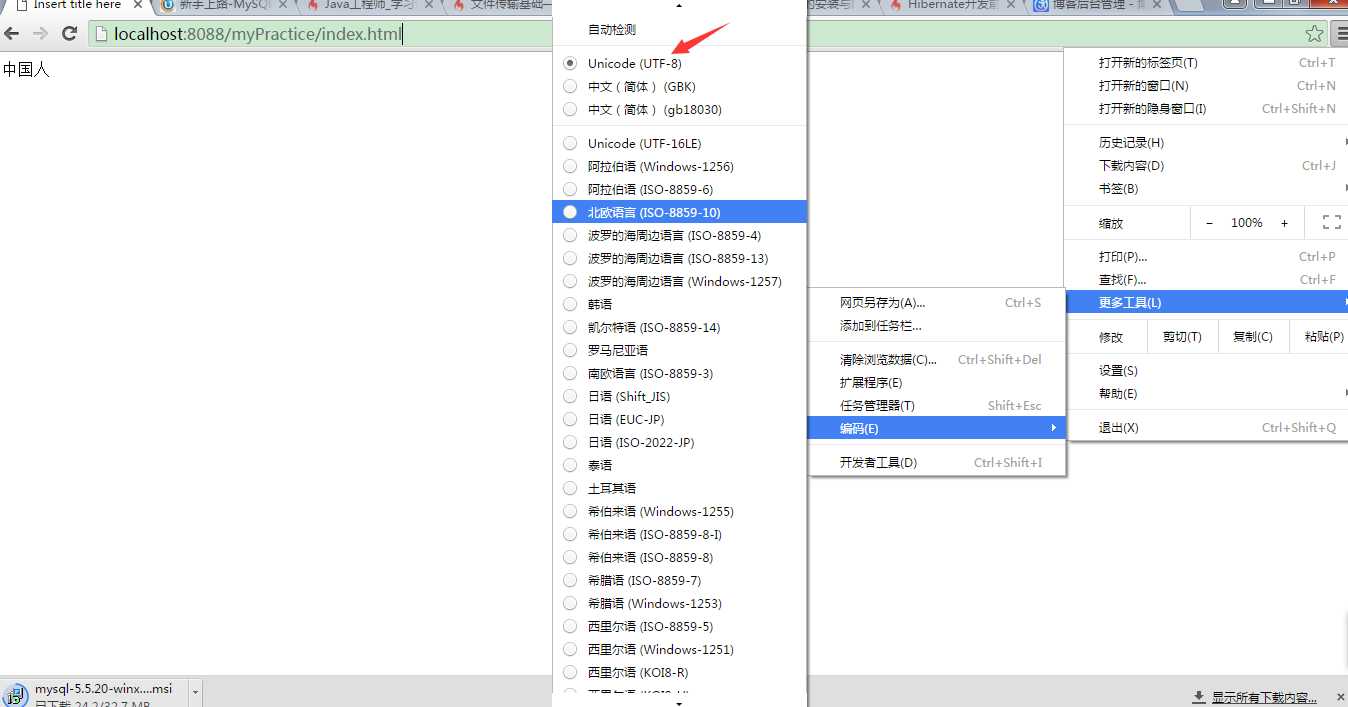
文件在转换时出现编码不一致:
package com.thinkive.bank.myPractice; public class test { public static void main(String[] args) throws Exception{ /*=========== gbk编码中文占用2个字节,英文占用1个字节 ===========*/ String s = "文祥ABC"; byte[] bytes1 = s.getBytes("gbk"); //这个项目默认的编码方式就是gbk,这里不写这个参数也对。 for (byte b : bytes1) { System.out.print(Integer.toHexString(b & 0xff)+" "); //以16进制的方式进行显示字节 } /*===================== end =========================*/ /*=========== utf-8编码中文占用3个字节,英文占用1个字节 ===========*/ System.out.println(""); byte[] bytes2 = s.getBytes("utf-8"); for (byte b : bytes2) { System.out.print(Integer.toHexString(b & 0xff)+" "); } /*===================== end =========================*/ /*=========== utf-16be编码中文占用2个字节,英文占用2个字节 ===========*/ System.out.println(""); byte[] bytes3 = s.getBytes("utf-16be"); for (byte b : bytes3) { System.out.print(Integer.toHexString(b & 0xff)+" "); } /*===================== end =========================*/ /** * 当字节序列使用某种编码时,这个时候想要把字节序列变成字符串,也需要使用同种编码方式,否则乱码. */ System.out.println(""); String s1=new String(bytes3,"utf-16be"); System.out.println(s1); /** * 文本文件 就是字节序列 * 可以是任何编码的字节序列 * 如果我们在中文机器上直接创建文本文件,那么该文本文件只认识ANSI编码 * 联通、联纯属一种巧合,它们正好符合utf-8的编码方式 */ } }
标签:
原文地址:http://www.cnblogs.com/wenxiangxu/p/5036410.html