标签:
kafkautil:

import java.util.Properties; import kafka.javaapi.producer.Producer; import kafka.producer.ProducerConfig; import org.springframework.beans.factory.annotation.Value; public class KafkaUtil { @Value("#{sys[‘connect‘]}") private static String zkConnect ; @Value("#{sys[‘metadata.broker.list‘]}") private static String brokerList; @Value("#{sys[‘request.required.acks‘]}") private static String ack; private static Producer<String, String> producer = null; /*static{ Properties p = PropertiesUtil.getProperties("kafka.properties"); zkConnect = (String) p.get("zk.connect"); brokerList = (String) p.get("metadata.broker.list"); ack = (String) p.get("request.required.acks"); topic = (String) p.get("topic.imeidata"); } */ public static Producer<String,String> getProducer(){ if(producer == null){ Properties p = PropertiesUtil.getProperties("kafka.properties"); zkConnect = (String) p.get("zk.connect"); brokerList = (String) p.get("metadata.broker.list"); ack = (String) p.get("request.required.acks"); Properties props = new Properties(); props.put("zk.connect", zkConnect); props.put("metadata.broker.list", brokerList); props.put("serializer.class", "kafka.serializer.StringEncoder"); props.put("request.required.acks", ack); props.put("producer.type", "async");//是否同步 sync:同步 async:异步 props.put("partitioner.class", "com.kafka.SendPartitioner");//发送到多个分区进行分布式存储的分区算法类 props.put("request.timeout.ms", "50000"); props.put("queue.buffering.max.ms", "10000");//默认值5000 异步模式下,每隔此时间间隔会将缓冲的消息提交一次 props.put("batch.num.messages", "1000");//默认值200 异步模式下,一次批量提交消息的条数, //但如果间隔时间超过 queue.buffering.max.ms 的值,不管有没有达到批量提交的设值,都会进行一次提交 ProducerConfig config = new ProducerConfig(props); producer = new Producer<String, String>(config); } return producer; } }
kafka消息发送类的属性:
1:zk.connect:zk服务端连接地址
2:metadata.broker.list:zk客户端地址
3:serializer.class:kafka消息发送序列化格式
4:request.required.acks:是否确认消息消费机制 它有三个选项:1,0,-1
0,意味着producer永远不会等待一个来自broker的ack,这就是0.7版本的行为。这个选项提供了最低的延迟,但是持久化的保证是最弱的,当server挂掉的时候会丢失一些数据。经测试,每10K消息大约会丢几百条消息。
1,意味着在leader replica已经接收到数据后,producer会得到一个ack。这个选项提供了更好的持久性,因为在server确认请求成功处理后,client才会返回。如果刚写到leader上,还没来得及复制leader就挂了,那么消息才可能会 丢失。
-1,意味着在所有的ISR都接收到数据后,producer才得到一个ack。这个选项提供了最好的持久性,只要还有一个replica存活,那么数据就不会丢失。经测试,100W条消息没有丢消息。
5:request.timeout.ms:请求超时
6:producer.type 是否同步 它有两个选项 sync:同步 async:异步 同步模式下,每发送一次消息完毕才会返回 在异步模式下,可以选择异步参数。
7:queue.buffering.max.ms:默认值5000 异步模式下,每隔此时间间隔会将缓冲的消息提交一次
8:batch.num.messages:默认值200 异步模式下,一次批量提交消息的条数,但如果间隔时间超过 queue.buffering.max.ms 的值,不管有没有达到批量提交的设值,都会进行一次提交
9:partitioner.class:自定义分区算法
在一个kafka集群中,每一个节点称为一个broker,所以进入zk通过/ls命令查看根目录有个brokers目录(kafka默认安装配置文件是放在zk根目录,我更喜欢入在自定义目录下),这里保存了当前kafka集群在正在运行的节点名:

只有将所有消息最大限度平均的发送到每个broker上去,才能达到最好的集群效果。那么kafka是通过什么来保证这一点的呢。
kafka消息类KeyedMessae中有一个方法,参数分别为将要发送消息的队列,和消息KEY,VALUE。通过对KEY的HASH值求broker的个数求模,将会得到broker值,它就是将接收消息的节点。
可以自定义分区实现类,并在属性中指明:
import kafka.producer.Partitioner; import kafka.utils.VerifiableProperties; public class SendPartitioner implements Partitioner{ public SendPartitioner(VerifiableProperties verifiableProperties) {} @Override public int partition(Object key, int numPartitions) { try { return Math.abs(key.hashCode() % numPartitions); } catch (Exception e) { return Math.abs(key.hashCode() % numPartitions); } } }
numPartitions 指的是kafka集群节点数,不用显式指定,它可以通过zk实时得到此值。
以上属性大都可以通过kafka的安装配置文件来指定。但一个kafka集群可能并不止服务一个队列或者一个项目。不同的项目具体业务需求不同,所以最好是在各个项目提定具体的参数。
Storm:
storm与kafka集成有第三方框架,叫做storm-kafka.jar。简而言之,它其实只做了一件事情。就是已经写好了storm的spout,我们只需要编写bolt和提交topology即可实现storm.
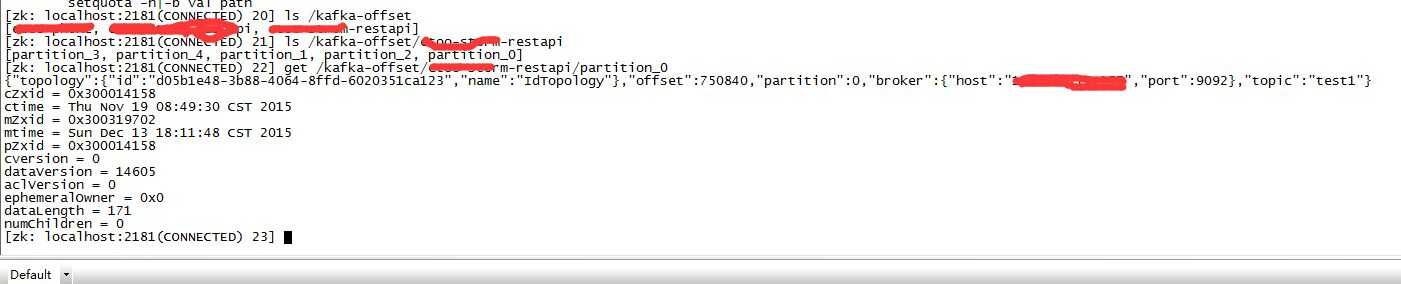
它帮我们实现了kafka消费端相对难把握的一件事情,就是偏移量offset的问题。如果你不想每次启动都重头读取kafka消息,尽量避免消息重复消费,那必须要保证良好的偏移量机制。特别是在多个用户组和队列的情况下。
代码:
import com.util.PropertiesUtil; import storm.kafka.KafkaSpout; import storm.kafka.SpoutConfig; import storm.kafka.StringScheme; import storm.kafka.ZkHosts; import backtype.storm.Config; import backtype.storm.LocalCluster; import backtype.storm.StormSubmitter; import backtype.storm.spout.SchemeAsMultiScheme; import backtype.storm.topology.TopologyBuilder; public class Topology { private static String topic; private static String brokerZkStr; private static String brokerZkPath; private static String offset; private static String app; static{ Properties p = PropertiesUtil.getProperties("storm.properties"); brokerZkStr = (String) p.get("brokerZkStr"); brokerZkPath = (String) p.get("brokerZkPath"); topic = (String) p.get("kafka.topic"); offset = (String) p.get("kafka.offset"); app = (String) p.get("kafka.app"); } public static void main(String[] args) throws InterruptedException { ZkHosts zk = new ZkHosts(brokerZkStr,brokerZkPath); SpoutConfig spoutConf = new SpoutConfig(zk, topic, offset,//偏移量 offset 的根目录 app);//对应一个应用 List<String> zkServices = new ArrayList<>(); for(String str : zk.brokerZkStr.split(",")){ zkServices.add(str.split(":")[0]); } spoutConf.zkServers = zkServices; spoutConf.zkPort = 2181; spoutConf.forceFromStart = false;// true:从头消费 false:从offset处消费 spoutConf.socketTimeoutMs = 60 * 1000; spoutConf.scheme = new SchemeAsMultiScheme(new StringScheme()); TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("spout", new KafkaSpout(spoutConf),4); //builder.setSpout("spout", new TestSpout(),5); builder.setBolt("bolt1", new GetMsgBolt(),4).shuffleGrouping("spout"); Config config = new Config(); config.setDebug(false); config.setNumWorkers(4); if(args.length>0){ try { StormSubmitter.submitTopology(args[0], config, builder.createTopology()); } catch (Exception e) { e.printStackTrace(); } }else{ LocalCluster cluster = new LocalCluster(); cluster.submitTopology("MyTopology", config, builder.createTopology()); } } }
属性:
1:brokerZkPath kafka集群在zk里的根目录,默认是brokers
2:kafka.offset kafka消息队列偏移量记录在zk中的位置
3:kafka.app 实际上就是kafka.offset的子目录,父级目录规定了kafka集群消息offset的总位置,子目录是具体每个队列或者应用消息的偏移量,避免在多用户组多队列情况下偏移量错乱的情况。
标签:
原文地址:http://www.cnblogs.com/eryuan/p/5043208.html