标签:
wordCount例子
输入处理文件
hello me
hello you
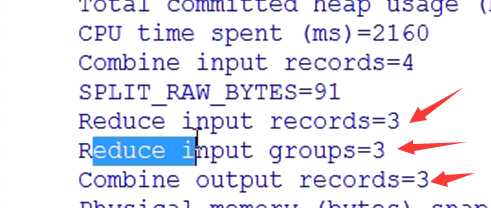
没有加入Combiner之前

设置combiner
//加入Combiner //map产生的输出在这个Combiner运行 运行完成交给myreduce job.setCombinerClass(MyReducer.class);
Combiner 位于map的reduce中间,会处理下数据
Combiner 位于map段的后面
================流程====================
原始
hello you
hello me
==================Map处理=================
hello 1
you 1
hello 1
me 1
====================排序=================
hello 1
hello 1
me 1
you 1
====================分组 4条记录三组==========
hello {1,1}
me {1}
you {1}
===============加入Combiner 会进行合并,变为 3条记录3组================
hello {2}
me {1}
you {1}
=====================Map段执行完成===========
Code:
package combiner; import java.io.IOException; import java.net.URI; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * hello you * hello me * * Map运行完成之后会进行 分区 排序 分组 * 这里讲分组之后的规约 * * 自定义规约 * * */ public class WordCountApp { //可以是文件夹或者文件 private static final String inputPaths = "hdfs://hadoop:9000/hello"; //只能是文件夹 private static final String OUT_PATH = "hdfs://hadoop:9000/out"; public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); FileSystem fileSystem = FileSystem.get(new URI(OUT_PATH), conf); boolean delete = fileSystem.delete(new Path(OUT_PATH), true); if (delete) { System.out.println("delete out_path ok"); } Job job = new Job(conf, WordCountApp.class.getSimpleName()); job.setJarByClass(WordCountApp.class); FileInputFormat.setInputPaths(job, inputPaths); job.setInputFormatClass(TextInputFormat.class); job.setMapperClass(MyMapper.class); //加入Combiner //map产生的输出在这个Combiner运行 运行完成交给myreduce job.setCombinerClass(MyReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); FileOutputFormat.setOutputPath(job, new Path(OUT_PATH)); //提交并等待运行结束 job.waitForCompletion(true); } /** * 输入的key 偏移量 LongWritable 类型 * 输入的value 行文本的内容 * 输出的key 输出的key 单词 * 输出的value 输出的value 次数 * */ public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ /** * 解析源文件会产生2个键值对,分别是<0,hello you><10,hello me>;所以map函数会被调用2次 */ @Override protected void map(LongWritable key, Text value, org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException { final String line = value.toString(); String[] split = line.split("\t"); for (String word : split) { context.write(new Text(word), new LongWritable(1)); } } } //map函数执行结束后,map输出的<K,V>一共有4个,分别是<hello,1>,<you,1>,<hello,1>,<me,1> //分区(类似分部门),默认只有一个区 //排序后的结果:<Hello,1>,<Hello,1>,<me,1>,<you,1> //分组(把相同key的value放在一起):<Hello,{1,1}>,<me,{1}>,<you,{1}> //规约(可选) //map产生的<k,v>分发到reduce的过程称作shuffle /** * 输入部分和map的输出部分一致,reduce接收的数据来自于map的输出 */ public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ /** * 相同key的value放在 Iterable<LongWritable> 中 * 每一组调用一次reduce函数,一共调用了3次 第一次过来的是 * 分组的数量与reduce函数的调用次数相等 */ @Override protected void reduce(Text key, Iterable<LongWritable> values, org.apache.hadoop.mapreduce.Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException { Long count=0l; for (LongWritable times : values) { count+=times.get(); } context.write(key, new LongWritable(count)); } } }
问:为什么使用combiner?
答:为了减少Map段的输出,意味着Shuffer时传输的数据量小,网络开销就小了
标签:
原文地址:http://www.cnblogs.com/thinkpad/p/5046096.html