标签:
运行时刻内存被分为的典型方式为:
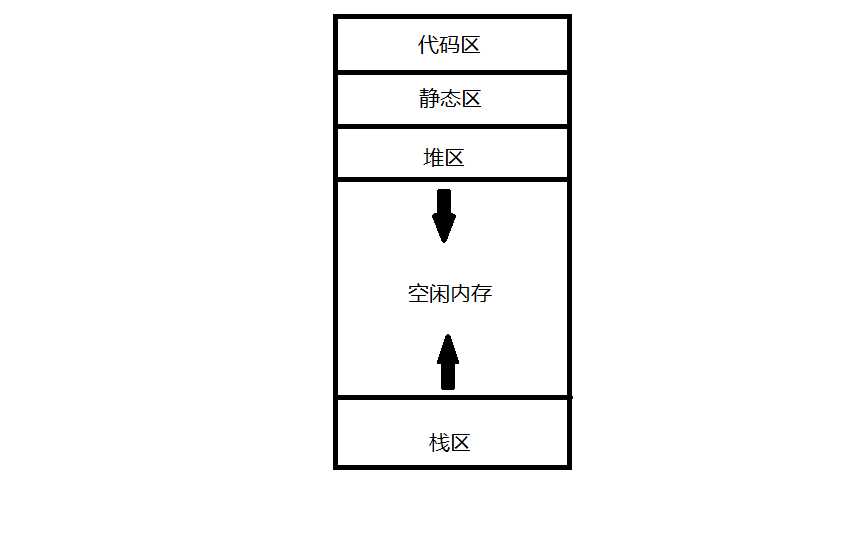
大概就是这样吧...
代码区:生成的目标代码的大小在编译时刻就已经固定下来了,因此编译器可以将可执行目标代码放在这个静态确定的区域。这个区域通常位于存储的低端。
静态区:程序的某些数据对象的大小可以在编译时刻知道,它们可以被防止在这个称为静态去的区域中,这个区域可以被静态确定。防止在这个区域内的数据对象包括 全局常量,编译器产生的数据,比如用于垃圾回收的信息等。之所以要将尽可能多的数据对象进行静态分配,是因为这些对象的地址可以被便已到目标代码中。
堆区: 许多程序语言支持通过程序控制人工分配和回收数据对象放在这个区域中。例如C语言的malloc和free函数用来获取及释放任意存储块,C++的 new和delete函数。堆区管理这种具有常生命周期的数据。
栈区: 用来存放成为活动记录的数据结构,这些活动记录在函数调用过程中生成。(也就是说系统调用的数据存在这里)例如程序计数器和机器存储器。栈向较低的方向增长。当控制从该次调用返回时,相关寄存器的值被恢复,程序计数器被设置成指向紧跟在这次调用之后的点,然后调用过程的活动就可以重新开始。如果一个数据对象的生命周期包含在一次活动的生命期中,那么该对象可以和其他相关于该活动的信息一起分配到栈区上。
为了将运行时刻的空间利用率最大化,堆和栈被放在剩余地址空间的相对两端。这些区域是动态的,它们的大小随着程序运行而改变。
参考文献: 编译原理
标签:
原文地址:http://www.cnblogs.com/keltoy/p/5046132.html