标签:
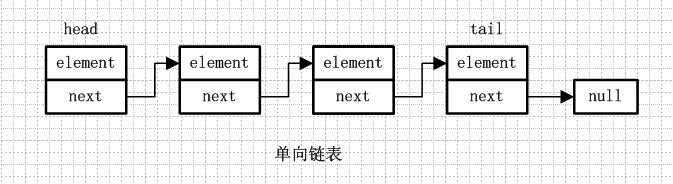
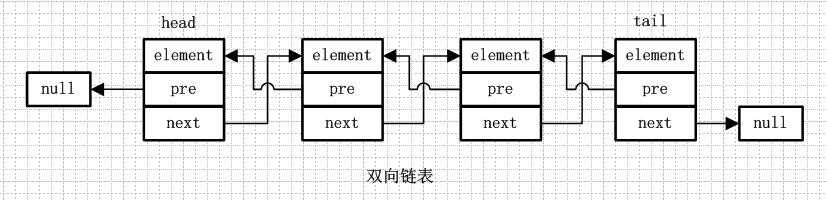
1 public interface Deque<E> extends Queue<E> { 2 void addFirst(E e); 3 boolean offerFirst(E e); 4 boolean offerLast(E e); 5 E removeFirst(); 6 E removeLast(); 7 E pollFirst(); 8 E pollLast(); 9 E getFirst(); 10 E getLast(); 11 E peekFirst(); 12 E peekLast(); 13 boolean removeFirstOccurrence(Object o); 14 boolean removeLastOccurrence(Object o); 15 // *** Queue methods *** 16 boolean add(E e); 17 boolean offer(E e); 18 E remove(); 19 E poll(); 20 E element(); 21 E peek(); 22 // *** Stack methods *** 23 void push(E e); 24 E pop(); 25 // *** Collection methods *** 26 boolean remove(Object o); 27 boolean contains(Object o); 28 public int size(); 29 Iterator<E> iterator(); 30 Iterator<E> descendingIterator(); 31 }
3.底层存储
1 private transient Entry<E> header = new Entry<E>(null, null, null); 2 private transient int size = 0;
LinkedList中提供了上面两个属性,其中size和ArrayList中一样用来计数,表示list的元素数量,而header则是链表的头结点,Entry则是链表的节点对象。
1 private static class Entry<E> { 2 E element; // 当前存储元素 3 Entry<E> next; // 下一个元素 4 Entry<E> previous; // 上一个元素 5 6 Entry(E element, Entry<E> next, Entry<E> previous) { 7 this.element = element; 8 this.next = next; 9 this.previous = previous; 10 } 11 }
1 /** 2 * 构造一个空的LinkedList . 3 */ 4 public LinkedList() { 5 //将header节点的前一节点和后一节点都设置为自身 6 header.next = header. previous = header ; 7 } 8 9 /** 10 * 构造一个包含指定 collection 中的元素的列表,这些元素按其 collection 的迭代器返回的顺序排列 11 */ 12 public LinkedList(Collection<? extends E> c) { 13 this(); 14 addAll(c); 15 }
1 public LinkedList() { 2 header.next = null; 3 header. previous = null; 4 }
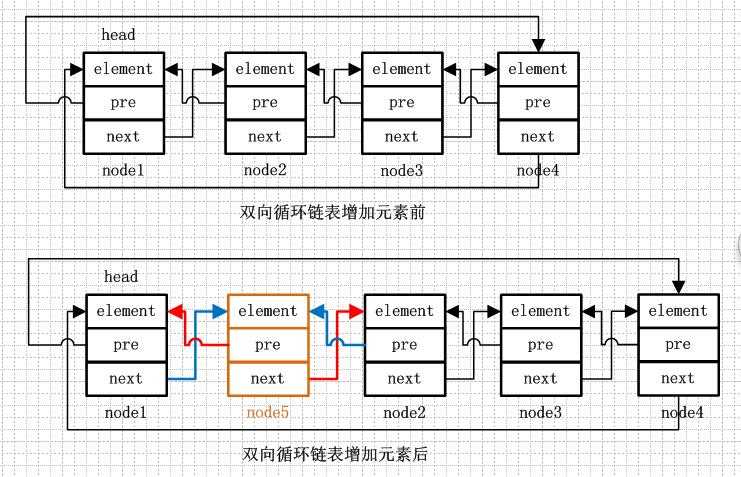
1 /** 2 * 将一个元素添加至list尾部 3 */ 4 public boolean add(E e) { 5 // 在header前添加元素e,header前就是最后一个结点啦,就是在最后一个结点的后面添加元素e 6 addBefore(e, header); 7 return true; 8 } 9 /** 10 * 在指定位置添加元素 11 */ 12 public void add(int index, E element) { 13 // 如果index等于list元素个数,则在队尾添加元素(header之前),否则在index节点前添加元素 14 addBefore(element, (index== size ? header : entry(index))); 15 } 16 17 private Entry<E> addBefore(E e, Entry<E> entry) { 18 // 用entry创建一个要添加的新节点,next为entry,previous为entry.previous,意思就是新节点插入entry前面,确定自身的前后引用, 19 Entry<E> newEntry = new Entry<E>(e, entry, entry.previous); 20 // 下面修改newEntry的前后节点的引用,确保其链表的引用关系是正确的 21 // 将上一个节点的next指向自己 22 newEntry. previous.next = newEntry; 23 // 将下一个节点的previous指向自己 24 newEntry. next.previous = newEntry; 25 // 计数+1 26 size++; 27 modCount++; 28 return newEntry; 29 }
1 /** 2 * 添加一个集合元素到list中 3 */ 4 public boolean addAll(Collection<? extends E> c) { 5 // 将集合元素添加到list最后的尾部 6 return addAll(size , c); 7 } 8 9 /** 10 * 在指定位置添加一个集合元素到list中 11 */ 12 public boolean addAll(int index, Collection<? extends E> c) { 13 // 越界检查 14 if (index < 0 || index > size) 15 throw new IndexOutOfBoundsException( "Index: "+index+ 16 ", Size: "+size ); 17 Object[] a = c.toArray(); 18 // 要插入元素的个数 19 int numNew = a.length ; 20 if (numNew==0) 21 return false; 22 modCount++; 23 24 // 找出要插入元素的前后节点 25 // 获取要插入index位置的下一个节点,如果index正好是lsit尾部的位置那么下一个节点就是header,否则需要查找index位置的节点 26 Entry<E> successor = (index== size ? header : entry(index)); 27 // 获取要插入index位置的上一个节点,因为是插入,所以上一个点击就是未插入前下一个节点的上一个 28 Entry<E> predecessor = successor. previous; 29 // 循环插入 30 for (int i=0; i<numNew; i++) { 31 // 构造一个节点,确认自身的前后引用 32 Entry<E> e = new Entry<E>((E)a[i], successor, predecessor); 33 // 将插入位置上一个节点的下一个元素引用指向当前元素(这里不修改下一个节点的上一个元素引用,是因为下一个节点随着循环一直在变) 34 predecessor. next = e; 35 // 最后修改插入位置的上一个节点为自身,这里主要是为了下次遍历后续元素插入在当前节点的后面,确保这些元素本身的顺序 36 predecessor = e; 37 } 38 // 遍历完所有元素,最后修改下一个节点的上一个元素引用为遍历的最后一个元素 39 successor. previous = predecessor; 40 41 // 修改计数器 42 size += numNew; 43 return true; 44 }
1 /** 2 * 删除第一个匹配的指定元素 3 */ 4 public boolean remove(Object o) { 5 // 遍历链表找到要被删除的节点 6 if (o==null) { 7 for (Entry<E> e = header .next; e != header; e = e.next ) { 8 if (e.element ==null) { 9 remove(e); 10 return true; 11 } 12 } 13 } else { 14 for (Entry<E> e = header .next; e != header; e = e.next ) { 15 if (o.equals(e.element )) { 16 remove(e); 17 return true; 18 } 19 } 20 } 21 return false; 22 } 23 24 private E remove(Entry<E> e) { 25 if (e == header ) 26 throw new NoSuchElementException(); 27 28 // 被删除的元素,供返回 29 E result = e. element; 30 // 下面修正前后对该节点的引用 31 // 将该节点的上一个节点的next指向该节点的下一个节点 32 e. previous.next = e.next; 33 // 将该节点的下一个节点的previous指向该节点的上一个节点 34 e. next.previous = e.previous; 35 // 修正该节点自身的前后引用 36 e. next = e.previous = null; 37 // 将自身置空,让gc可以尽快回收 38 e. element = null; 39 // 计数器减一 40 size--; 41 modCount++; 42 return result; 43 }
上面对于链表增加元素总结了,一句话就是“改变前后的互相指向关系”,删除也是同样的道理,由于节点被删除,该节点的上一个节点和下一个节点互相拉一下小手就可以了,注意的是“互相”,不能一厢情愿。
1 /** 2 * 修改指定位置索引位置的元素 3 */ 4 public E set( int index, E element) { 5 // 查找index位置的节点 6 Entry<E> e = entry(index); 7 // 取出该节点的元素,供返回使用 8 E oldVal = e. element; 9 // 用新元素替换旧元素 10 e. element = element; 11 // 返回旧元素 12 return oldVal; 13 }
1 /** 2 * 查找指定索引位置的元素 3 */ 4 public E get( int index) { 5 return entry(index).element ; 6 } 7 8 /** 9 * 返回指定索引位置的节点 10 */ 11 private Entry<E> entry( int index) { 12 // 越界检查 13 if (index < 0 || index >= size) 14 throw new IndexOutOfBoundsException( "Index: "+index+ 15 ", Size: "+size ); 16 // 取出头结点 17 Entry<E> e = header; 18 // size>>1右移一位代表除以2,这里使用简单的二分方法,判断index与list的中间位置的距离 19 if (index < (size >> 1)) { 20 // 如果index距离list中间位置较近,则从头部向后遍历(next) 21 for (int i = 0; i <= index; i++) 22 e = e. next; 23 } else { 24 // 如果index距离list中间位置较远,则从头部向前遍历(previous) 25 for (int i = size; i > index; i--) 26 e = e. previous; 27 } 28 return e; 29 }
1 /** 2 * Returns <tt>true</tt> if this list contains the specified element. 3 * More formally, returns <tt>true</tt> if and only if this list contains 4 * at least one element <tt>e</tt> such that 5 * <tt>(o==null ? e==null : o.equals(e))</tt>. 6 * 7 * @param o element whose presence in this list is to be tested 8 * @return <tt> true</tt> if this list contains the specified element 9 */ 10 public boolean contains(Object o) { 11 return indexOf(o) != -1; 12 } 13 14 /** 15 * Returns the index of the first occurrence of the specified element 16 * in this list, or -1 if this list does not contain the element. 17 * More formally, returns the lowest index <tt>i</tt> such that 18 * <tt>(o==null ? get(i)==null : o.equals(get(i)))</tt>, 19 * or -1 if there is no such index. 20 * 21 * @param o element to search for 22 * @return the index of the first occurrence of the specified element in 23 * this list, or -1 if this list does not contain the element 24 */ 25 public int indexOf(Object o) { 26 int index = 0; 27 if (o==null) { 28 for (Entry e = header .next; e != header; e = e.next ) { 29 if (e.element ==null) 30 return index; 31 index++; 32 } 33 } else { 34 for (Entry e = header .next; e != header; e = e.next ) { 35 if (o.equals(e.element )) 36 return index; 37 index++; 38 } 39 } 40 return -1; 41 } 42 43 /** 44 * Returns the index of the last occurrence of the specified element 45 * in this list, or -1 if this list does not contain the element. 46 * More formally, returns the highest index <tt>i</tt> such that 47 * <tt>(o==null ? get(i)==null : o.equals(get(i)))</tt>, 48 * or -1 if there is no such index. 49 * 50 * @param o element to search for 51 * @return the index of the last occurrence of the specified element in 52 * this list, or -1 if this list does not contain the element 53 */ 54 public int lastIndexOf(Object o) { 55 int index = size ; 56 if (o==null) { 57 for (Entry e = header .previous; e != header; e = e.previous ) { 58 index--; 59 if (e.element ==null) 60 return index; 61 } 62 } else { 63 for (Entry e = header .previous; e != header; e = e.previous ) { 64 index--; 65 if (o.equals(e.element )) 66 return index; 67 } 68 } 69 return -1; 70 }
1 /** 2 * Returns the number of elements in this list. 3 * 4 * @return the number of elements in this list 5 */ 6 public int size() { 7 return size ; 8 } 9 10 /** 11 * {@inheritDoc} 12 * 13 * <p>This implementation returns <tt>size() == 0 </tt>. 14 */ 15 public boolean isEmpty() { 16 return size() == 0; 17 }
1 /** 2 * Adds the specified element as the tail (last element) of this list. 3 * 4 * @param e the element to add 5 * @return <tt> true</tt> (as specified by {@link Queue#offer}) 6 * @since 1.5 7 */ 8 public boolean offer(E e) { 9 return add(e); 10 } 11 12 /** 13 * Retrieves and removes the head (first element) of this list 14 * @return the head of this list, or <tt>null </tt> if this list is empty 15 * @since 1.5 16 */ 17 public E poll() { 18 if (size ==0) 19 return null; 20 return removeFirst(); 21 } 22 23 /** 24 * Removes and returns the first element from this list. 25 * 26 * @return the first element from this list 27 * @throws NoSuchElementException if this list is empty 28 */ 29 public E removeFirst() { 30 return remove(header .next); 31 } 32 33 /** 34 * Retrieves, but does not remove, the head (first element) of this list. 35 * @return the head of this list, or <tt>null </tt> if this list is empty 36 * @since 1.5 37 */ 38 public E peek() { 39 if (size ==0) 40 return null; 41 return getFirst(); 42 } 43 44 /** 45 * Returns the first element in this list. 46 * 47 * @return the first element in this list 48 * @throws NoSuchElementException if this list is empty 49 */ 50 public E getFirst() { 51 if (size ==0) 52 throw new NoSuchElementException(); 53 54 return header .next. element; 55 } 56 57 /** 58 * Pushes an element onto the stack represented by this list. In other 59 * words, inserts the element at the front of this list. 60 * 61 * <p>This method is equivalent to {@link #addFirst}. 62 * 63 * @param e the element to push 64 * @since 1.6 65 */ 66 public void push(E e) { 67 addFirst(e); 68 } 69 70 /** 71 * Inserts the specified element at the beginning of this list. 72 * 73 * @param e the element to add 74 */ 75 public void addFirst(E e) { 76 addBefore(e, header.next ); 77 }
给jdk写注释系列之jdk1.6容器(2)-LinkedList源码解析
标签:
原文地址:http://www.cnblogs.com/tstd/p/5046819.html