标签:
Introduction ------------ The Heap Only Tuple (HOT) feature eliminates redundant index entries and allows the re-use of space taken by DELETEd or obsoleted UPDATEd tuples without performing a table-wide vacuum. It does this by allowing single-page vacuuming, also called "defragmentation". Note: there is a Glossary at the end of this document that may be helpful for first-time readers. Technical Challenges -------------------- Page-at-a-time vacuuming is normally impractical because of the costs of finding and removing the index entries that link to the tuples to be reclaimed. Standard vacuuming scans the indexes to ensure all such index entries are removed, amortizing the index scan cost across as many dead tuples as possible; this approach does not scale down well to the case of reclaiming just a few tuples. In principle one could recompute the index keys and do standard index searches to find the index entries, but this is risky in the presence of possibly-buggy user-defined functions in functional indexes. An allegedly immutable function that in fact is not immutable might prevent us from re-finding an index entry (and we cannot throw an error for not finding it, in view of the fact that dead index entries are sometimes reclaimed early). That would lead to a seriously corrupt index, in the form of entries pointing to tuple slots that by now contain some unrelated content. In any case we would prefer to be able to do vacuuming without invoking any user-written code. HOT solves this problem for a restricted but useful special case: where a tuple is repeatedly updated in ways that do not change its indexed columns. (Here, "indexed column" means any column referenced at all in an index definition, including for example columns that are tested in a partial-index predicate but are not stored in the index.) An additional property of HOT is that it reduces index size by avoiding the creation of identically-keyed index entries. This improves search speeds. Update Chains With a Single Index Entry --------------------------------------- Without HOT, every version of a row in an update chain has its own index entries, even if all indexed columns are the same. With HOT, a new tuple placed on the same page and with all indexed columns the same as its parent row version does not get new index entries. This means there is only one index entry for the entire update chain on the heap page. An index-entry-less tuple is marked with the HEAP_ONLY_TUPLE flag. The prior row version is marked HEAP_HOT_UPDATED, and (as always in an update chain) its t_ctid field links forward to the newer version.
注:注意在update chain中,HEAP_ONLY_TUPLE的位置是在update chain的末端,而从root tuple到HEAP_ONLY_TUPLE之间的均为HEAP_HOT_UPDATED,也包括root typle.在update chain是通过ctid来在不同的版本之间穿行的。
要想深入了解HOT结构,可以参考下面的ppt:
HOT Inside: The Technical Architecture (application/vnd.ms-powerpoint - 1.6 MB)
For example: Index points to 1 lp [1] [2] [111111111]->[2222222222] In the above diagram, the index points to line pointer 1, and tuple 1 is marked as HEAP_HOT_UPDATED. Tuple 2 is a HOT tuple, meaning it has no index entry pointing to it, and is marked as HEAP_ONLY_TUPLE. Although tuple 2 is not directly referenced by the index, it can still be found by an index search: after traversing from the index to tuple 1, the index search proceeds forward to child tuples as long as it sees the HEAP_HOT_UPDATED flag set. Since we restrict the HOT chain to lie within a single page, this requires no additional page fetches and doesn‘t introduce much performance penalty. Eventually, tuple 1 will no longer be visible to any transaction. At that point its space could be reclaimed, but its line pointer cannot, since the index still links to that line pointer and we still need to be able to find tuple 2 in an index search. HOT handles this by turning line pointer 1 into a "redirecting line pointer", which links to tuple 2 but has no actual tuple attached. This state of affairs looks like Index points to 1 lp [1]->[2] [2222222222] If now the row is updated again, to version 3, the page looks like this: Index points to 1 lp [1]->[2] [3] [2222222222]->[3333333333] At some later time when no transaction can see tuple 2 in its snapshot, tuple 2 and its line pointer can be pruned entirely: Index points to 1 lp [1]------>[3] [3333333333] This is safe because no index entry points to line pointer 2. Subsequent insertions into the page can now recycle both line pointer 2 and the space formerly used by tuple 2. If an update changes any indexed column, or there is not room on the same page for the new tuple, then the HOT chain ends: the last member has a regular t_ctid link to the next version and is not marked HEAP_HOT_UPDATED. (In principle we could continue a HOT chain across pages, but this would destroy the desired property of being able to reclaim space with just page-local manipulations. Anyway, we don‘t want to have to chase through multiple heap pages to get from an index entry to the desired tuple, so it seems better to create a new index entry for the new tuple.) If further updates occur, the next version could become the root of a new HOT chain.
注:在原则上,我们可以继续使HOT chain跨多个页,但这会破换设想的按页释放空间和维护的特性。总而言之,我们不想通过跨页来通过单一index entry查询目标行,创建新index entry要更好一些。如果跨页继续更新,将会是新的HOT chain了。
Line pointer 1 has to remain as long as there is any non-dead member of the chain on the page. When there is not, it is marked "dead". This lets us reclaim the last child line pointer and associated tuple immediately. The next regular VACUUM pass can reclaim the index entries pointing at the line pointer and then the line pointer itself. Since a line pointer is small compared to a tuple, this does not represent an undue space cost.
注:当line pointer 1后面有非dead成员,那 line pointer 1将会保持,当没有非dead成员时,在vacuum时会回收dead空间、index entry和line pointer.
Note: we can use a "dead" line pointer for any DELETEd tuple, whether it was part of a HOT chain or not. This allows space reclamation in advance of running VACUUM for plain DELETEs as well as HOT updates. The requirement for doing a HOT update is that none of the indexed columns are changed. This is checked at execution time by comparing the binary representation of the old and new values. We insist on bitwise equality rather than using datatype-specific equality routines. The main reason to avoid the latter is that there might be multiple notions of equality for a datatype, and we don‘t know exactly which one is relevant for the indexes at hand. We assume that bitwise equality guarantees equality for all purposes. Abort Cases ----------- If a heap-only tuple‘s xmin is aborted, then it can be removed immediately: it was never visible to any other transaction, and all descendant row versions must be aborted as well. Therefore we need not consider it part of a HOT chain. By the same token, if a HOT-updated tuple‘s xmax is aborted, there is no need to follow the chain link. However, there is a race condition here: the transaction that did the HOT update might abort between the time we inspect the HOT-updated tuple and the time we reach the descendant heap-only tuple. It is conceivable that someone prunes the heap-only tuple before that, and even conceivable that the line pointer is re-used for another purpose. Therefore, when following a HOT chain, it is always necessary to be prepared for the possibility that the linked-to item pointer is unused, dead, or redirected; and if it is a normal item pointer, we still have to check that XMIN of the tuple matches the XMAX of the tuple we left. Otherwise we should assume that we have come to the end of the HOT chain. Note that this sort of XMIN/XMAX matching is required when following ordinary update chains anyway. (Early versions of the HOT code assumed that holding pin on the page buffer while following a HOT link would prevent this type of problem, but checking XMIN/XMAX matching is a much more robust solution.) Index/Sequential Scans ---------------------- When doing an index scan, whenever we reach a HEAP_HOT_UPDATED tuple whose xmax is not aborted, we need to follow its t_ctid link and check that entry as well; possibly repeatedly until we reach the end of the HOT chain. (When using an MVCC snapshot it is possible to optimize this a bit: there can be at most one visible tuple in the chain, so we can stop when we find it. This rule does not work for non-MVCC snapshots, though.) Sequential scans do not need to pay attention to the HOT links because they scan every item pointer on the page anyway. The same goes for a bitmap heap scan with a lossy bitmap. Pruning ------- HOT pruning means updating item pointers so that HOT chains are reduced in length, by collapsing out line pointers for intermediate dead tuples. Although this makes those line pointers available for re-use, it does not immediately make the space occupied by their tuples available. Defragmentation --------------- Defragmentation centralizes unused space. After we have converted root line pointers to redirected line pointers and pruned away any dead intermediate line pointers, the tuples they linked to are free space. But unless that space is adjacent to the central "hole" on the page (the pd_lower-to-pd_upper area) it cannot be used by tuple insertion. Defragmentation moves the surviving tuples to coalesce all the free space into one "hole". This is done with the same PageRepairFragmentation function that regular VACUUM uses.
如下page结构:
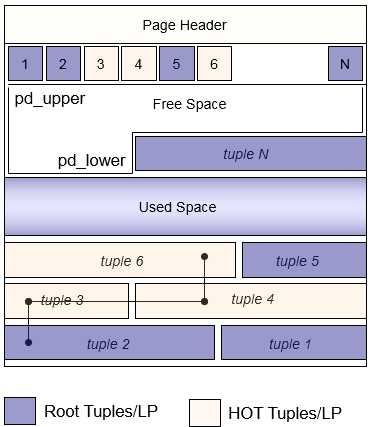
When can/should we prune or defragment? --------------------------------------- This is the most interesting question in HOT implementation, since there is no simple right answer: we must use heuristics to determine when it‘s most efficient to perform pruning and/or defragmenting. We cannot prune or defragment unless we can get a "buffer cleanup lock" on the target page; otherwise, pruning might destroy line pointers that other backends have live references to, and defragmenting might move tuples that other backends have live pointers to. Thus the general approach must be to heuristically decide if we should try to prune or defragment, and if so try to acquire the buffer cleanup lock without blocking. If we succeed we can proceed with our housekeeping work. If we cannot get the lock (which should not happen often, except under very heavy contention) then the housekeeping has to be postponed till some other time. The worst-case consequence of this is only that an UPDATE cannot be made HOT but has to link to a new tuple version placed on some other page, for lack of centralized space on the original page. Ideally we would do defragmenting only when we are about to attempt heap_update on a HOT-safe tuple. The difficulty with this approach is that the update query has certainly got a pin on the old tuple, and therefore our attempt to acquire a buffer cleanup lock will always fail. (This corresponds to the idea that we don‘t want to move the old tuple out from under where the query‘s HeapTuple pointer points. It might be possible to finesse that, but it seems fragile.) Pruning, however, is potentially useful even when we are not about to insert a new tuple, since shortening a HOT chain reduces the cost of subsequent index searches. The currently proposed heuristic is to prune and defrag when accessing a page with HOT updated tuples and with less than a certain threshold of free space (typically less than the average tuple size for that table). XXX there is much argument about this. We have effectively implemented the "truncate dead tuples to just line pointer" idea that has been proposed and rejected before because of fear of line pointer bloat: we might end up with huge numbers of line pointers and just a few actual tuples on a page. To limit the damage in the worst case, and to keep various work arrays as well as the bitmaps in bitmap scans reasonably sized, the maximum number of line pointers per page is arbitrarily capped at MaxHeapTuplesPerPage (the most tuples that could fit without HOT pruning). VACUUM ------ There is little change to regular vacuum. It removes dead HOT tuples, like pruning does, and cleans up any dead line pointers. VACUUM FULL ----------- To make vacuum full work, any DEAD tuples in the middle of an update chain need to be removed (see comments at the top of heap_prune_hotchain_hard() for details). XXX there is no such function in the current patch, and I can‘t find any comments defending a need for this, either. Vacuum full performs a more aggressive pruning that not only removes dead tuples at the beginning of an update chain, but scans the whole chain and removes any intermediate dead tuples as well. It also removes redirected line pointers by making them directly point to the first tuple in the HOT chain. This causes a user-visible change in the tuple‘s CTID, but since VACUUM FULL has always moved tuple CTIDs, that should not break anything.
注:vacuum full会破坏掉HOT chain中的多版本,引起用户所见的变更。它会清理掉any intermediate dead tuples和redirected line pointers。
XXX any extra complexity here needs justification --- a lot of it. Statistics ---------- XXX: How do HOT-updates affect statistics? How often do we need to run autovacuum and autoanalyze? As the latest patch stands, we track dead-space in the relation and trigger autovacuuum based on the percentage of dead space in the table. We don‘t have any mechanism to account for index bloat yet. Autoanalyze does not change. CREATE INDEX ------------ CREATE INDEX presents a problem for HOT updates. While the existing HOT chains all have the same index values for existing indexes, the columns in the new index might change within a pre-existing HOT chain, creating a "broken" chain that can‘t be indexed properly. To address this issue, regular (non-concurrent) CREATE INDEX makes the new index usable only by transactions newer than the CREATE INDEX command. This prevents transactions that can see the inconsistent HOT chains from trying to use the new index and getting incorrect results. New transactions can only see the rows visible after the index was created, hence the HOT chains are consistent for them. Entries in the new index point to root tuples (tuples with current index pointers) so that our index uses the same index pointers as all other indexes on the table. However the row we want to index is actually at the *end* of the chain, ie, the most recent live tuple on the HOT chain. That is the one we compute the index entry values for, but the TID we put into the index is that of the root tuple. Since transactions that will be allowed to use the new index cannot see any of the older tuple versions in the chain, the fact that they might not match the index entry isn‘t a problem. (Such transactions will check the tuple visibility information of the older versions and ignore them, without ever looking at their contents, so the content inconsistency is OK.) Subsequent updates to the live tuple will be allowed to extend the HOT chain only if they are HOT-safe for all the indexes. Because we have ShareLock on the table, any DELETE_IN_PROGRESS or INSERT_IN_PROGRESS tuples should have come from our own transaction. Therefore we can consider them committed since if the CREATE INDEX commits, they will be committed, and if it aborts the index is discarded. An exception to this is that early lock release is customary for system catalog updates, and so we might find such tuples when reindexing a system catalog. In that case we deal with it by waiting for the source transaction to commit or roll back. (We could do that for user tables too, but since the case is unexpected we prefer to throw an error.) Practically, we prevent old transactions from using the new index by setting pg_index.indcheckxmin to TRUE. Queries are allowed to use such an index only after pg_index.xmin is below their TransactionXmin horizon, thereby ensuring that any incompatible rows in HOT chains are dead to them. (pg_index.xmin will be the XID of the CREATE INDEX transaction. The reason for using xmin rather than a normal column is that the regular vacuum freezing mechanism will take care of converting xmin to FrozenTransactionId before it can wrap around.) This means in particular that the transaction creating the index will be unable to use the index. We alleviate that problem somewhat by not setting indcheckxmin unless the table actually contains HOT chains with RECENTLY_DEAD members. (In 8.4 we may be able to improve the situation, at least for non-serializable transactions, because we expect to be able to advance TransactionXmin intratransaction.) Another unpleasant consequence is that it is now risky to use SnapshotAny in an index scan: if the index was created more recently than the last vacuum, it‘s possible that some of the visited tuples do not match the index entry they are linked to. This does not seem to be a fatal objection, since there are few users of SnapshotAny and most use seqscans. The only exception at this writing is CLUSTER, which is okay because it does not require perfect ordering of the indexscan readout (and especially so because CLUSTER tends to write recently-dead tuples out of order anyway). CREATE INDEX CONCURRENTLY ------------------------- In the concurrent case we must take a different approach. We create the pg_index entry immediately, before we scan the table. The pg_index entry is marked as "not ready for inserts". Then we commit and wait for any transactions which have the table open to finish. This ensures that no new HOT updates will change the key value for our new index, because all transactions will see the existence of the index and will respect its constraint on which updates can be HOT. Other transactions must include such an index when determining HOT-safety of updates, even though they must ignore it for both insertion and searching purposes. We must do this to avoid making incorrect index entries. For example, suppose we are building an index on column X and we make an index entry for a non-HOT tuple with X=1. Then some other backend, unaware that X is an indexed column, HOT-updates the row to have X=2, and commits. We now have an index entry for X=1 pointing at a HOT chain whose live row has X=2. We could make an index entry with X=2 during the validation pass, but there is no nice way to get rid of the wrong entry with X=1. So we must have the HOT-safety property enforced before we start to build the new index. After waiting for transactions which had the table open, we build the index for all rows that are valid in a fresh snapshot. Any tuples visible in the snapshot will have only valid forward-growing HOT chains. (They might have older HOT updates behind them which are broken, but this is OK for the same reason it‘s OK in a regular index build.) As above, we point the index entry at the root of the HOT-update chain but we use the key value from the live tuple. We mark the index open for inserts (but still not ready for reads) then we again wait for transactions which have the table open. Then we take a second reference snapshot and validate the index. This searches for tuples missing from the index, and inserts any missing ones. Again, the index entries have to have TIDs equal to HOT-chain root TIDs, but the value to be inserted is the one from the live tuple. Then we wait until every transaction that could have a snapshot older than the second reference snapshot is finished. This ensures that nobody is alive any longer who could need to see any tuples that might be missing from the index, as well as ensuring that no one can see any inconsistent rows in a broken HOT chain (the first condition is stronger than the second). Finally, we can mark the index valid for searches. Limitations and Restrictions ---------------------------- It is worth noting that HOT forever forecloses alternative approaches to vacuuming, specifically the recompute-the-index-keys approach alluded to in Technical Challenges above. It‘ll be tough to recompute the index keys for a root line pointer you don‘t have data for anymore ... Glossary -------- Broken HOT Chain A HOT chain in which the key value for an index has changed. This is not allowed to occur normally but if a new index is created it can happen. In that case various strategies are used to ensure that no transaction for which the older tuples are visible can use the index. Cold update A normal, non-HOT update, in which index entries are made for the new version of the tuple. Dead line pointer A stub line pointer, that does not point to anything, but cannot be removed or reused yet because there are index pointers to it. Semantically same as a dead tuple. It has state LP_DEAD. HEAPTUPLE_DEAD_CHAIN New return value for HeapTupleSatisfiesVacuum, which means that the tuple is not visible to anyone, but it has been HOT updated so we cannot remove it yet because the following tuples in the chain would become inaccessible from indexes. Heap-only tuple A heap tuple with no index pointers, which can only be reached from indexes indirectly through its ancestral root tuple. Marked with HEAP_ONLY_TUPLE flag. HOT-safe A proposed tuple update is said to be HOT-safe if it changes none of the tuple‘s indexed columns. It will only become an actual HOT update if we can find room on the same page for the new tuple version. HOT update An UPDATE where the new tuple becomes a heap-only tuple, and no new index entries are made. HOT-updated tuple An updated tuple, for which the next tuple in the chain is a heap-only tuple. Marked with HEAP_HOT_UPDATED flag. Indexed column A column used in an index definition. The column might not actually be stored in the index --- it could be used in a functional index‘s expression, or used in a partial index predicate. HOT treats all these cases alike. Redirecting line pointer A line pointer that points to another line pointer and has no associated tuple. It has the special lp_flags state LP_REDIRECT, and lp_off is the OffsetNumber of the line pointer it links to. This is used when a root tuple becomes dead but we cannot prune the line pointer because there are non-dead heap-only tuples further down the chain. Root tuple The first tuple in a HOT update chain; the one that indexes point to. Update chain A chain of updated tuples, in which each tuple‘s ctid points to the next tuple in the chain. A HOT update chain is an update chain (or portion of an update chain) that consists of a root tuple and one or more heap-only tuples. A complete update chain can contain both HOT and non-HOT (cold) updated tuples.
参考:
http://www.postgresql.org/message-id/27473.1189896544@sss.pgh.pa.us
http://www.pgcon.org/2008/schedule/attachments/54_PGCon2008-HOT.ppt
标签:
原文地址:http://www.cnblogs.com/xiaotengyi/p/5046943.html