标签:
数据从外部进入Map时,可能这个文件是压缩的,对于常见的压缩不用关心,Map内部都是内置支持的。
当Map执行完成,产生输出到Reduce的时,这时候需要经过一个Shuffer过程,需要传输,十分消耗网络资源,那么在这种情况下数据传输量越小越好。
这时候我们可以对Map的输出进行压缩以减少文件的大小,减少传输量。
Reduce输出也可以做压缩
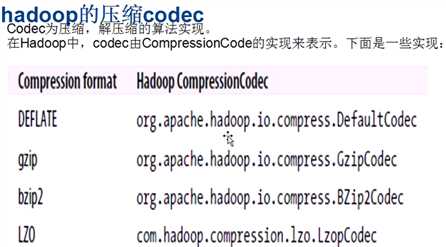
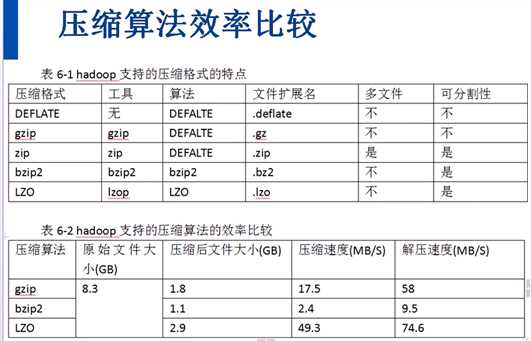
说明,可分割性: 如果文件不可分割,意味着整个文件将作为输入源处理。不能分割的话 即使一个T的数据也会将交给一个map处理

如何支持Map段的输出和Reduce端输出的压缩呢?

import java.io.IOException; import java.io.InputStream; import java.io.OutputStream; import java.net.URI; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.compress.CompressionCodec; import org.apache.hadoop.io.compress.CompressionCodecFactory; import org.apache.hadoop.io.compress.CompressionInputStream; import org.apache.hadoop.io.compress.CompressionOutputStream; import org.apache.hadoop.util.ReflectionUtils; public class CodecTest { public static void main(String[] args) throws Exception { compress("org.apache.hadoop.io.compress.BZip2Codec"); // compress("org.apache.hadoop.io.compress.GzipCodec"); // compress("org.apache.hadoop.io.compress.Lz4Codec"); // compress("org.apache.hadoop.io.compress.SnappyCodec"); // uncompress("text"); // uncompress1("hdfs://master:9000/user/hadoop/text.gz"); } // 压缩文件 public static void compress(String codecClassName) throws Exception { Class<?> codecClass = Class.forName(codecClassName); Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(conf); CompressionCodec codec = (CompressionCodec) ReflectionUtils.newInstance(codecClass, conf); //输入和输出均为hdfs路径 FSDataInputStream in = fs.open(new Path("/test.log")); FSDataOutputStream outputStream = fs.create(new Path("/test1.bz2")); System.out.println("compress start !"); // 创建压缩输出流 CompressionOutputStream out = codec.createOutputStream(outputStream); IOUtils.copyBytes(in, out, conf); IOUtils.closeStream(in); IOUtils.closeStream(out); System.out.println("compress ok !"); } // 解压缩 public static void uncompress(String fileName) throws Exception { Class<?> codecClass = Class .forName("org.apache.hadoop.io.compress.GzipCodec"); Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(conf); CompressionCodec codec = (CompressionCodec) ReflectionUtils .newInstance(codecClass, conf); FSDataInputStream inputStream = fs .open(new Path("/user/hadoop/text.gz")); // 把text文件里到数据解压,然后输出到控制台 InputStream in = codec.createInputStream(inputStream); IOUtils.copyBytes(in, System.out, conf); IOUtils.closeStream(in); } // 使用文件扩展名来推断二来的codec来对文件进行解压缩 public static void uncompress1(String uri) throws IOException { Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(URI.create(uri), conf); Path inputPath = new Path(uri); CompressionCodecFactory factory = new CompressionCodecFactory(conf); CompressionCodec codec = factory.getCodec(inputPath); if (codec == null) { System.out.println("no codec found for " + uri); System.exit(1); } String outputUri = CompressionCodecFactory.removeSuffix(uri, codec.getDefaultExtension()); InputStream in = null; OutputStream out = null; try { in = codec.createInputStream(fs.open(inputPath)); out = fs.create(new Path(outputUri)); IOUtils.copyBytes(in, out, conf); } finally { IOUtils.closeStream(out); IOUtils.closeStream(in); } } }
标签:
原文地址:http://www.cnblogs.com/thinkpad/p/5046996.html