标签:
MapReduce如何进行调优呢?
需要从Map阶段和Reduce阶段进行考虑。
1.如果存在大量的小数据,可以使用SequenceFile,自定义的CombineFileInputFormat
----------------------------------------------------------------------------------
小数据文件,每一个文件都会启动一个map任务,如果有大量小文件的话,就会有大量的map任务运行,这时候回造成资源浪费
map任务或者reduce任务都是java进程,如果启动java会耗费大量的资源,如果是小文件运行的话,有可能造成 数据真正处理的时间比启动结束的时间都要短
这时候要尽量避免小文件,如果有大量的小文件可以交给一个map进行处理,使用CombineFileInputFormat
也可以使用SequenceFile进行处理小文件
那么问题来了,是不是很多小文件用CombineFileInputFomat处理会比运行大量的map任务快呢,这个是不一定的,把很多小文件交给一个map处理和产生网络传输
这时候也会占用很多时间。
最好的解决方案就是不要使用大量的小文件!!!
2.推测执行在整个集群上关闭,特定需要的作业单独开启,一般可以节省5%~10%的集群资源
mapred.map.task.speculative.execution=false
mapred.reduce.task.speculative.execution=false
----------------------------------------------------------------------------------
推测执行,在作业进行运行的过程中,如果比较慢呢,那么机器就会启一个相同的任务运行相同的数据,谁先结束取谁的数据
推测执行会减少其他任务执行的机会,会浪费更多的资源。
什么时候开启好呢?在资源不紧张的情况下开启较好
3.开启JVM重用
mapred.job.reuse.jvm.num.tasks=-1
----------------------------------------------------------------------------------
map任务和reduce任务都是java进程,为了节省资源的暂占用,可以开启JVM的重用
即不用关闭jvm虚拟机,而只需要在jvm再开启就可以。就不必新启进程了。
4.增加InputSplit大小
mapred.min.split.size = 268435456
----------------------------------------------------------------------------------
一个InputSplit对应一个map任务,InputSplit少了,map就会减少,资源利用率就会有所提升,数据量会加大
一个map任务处理的数据量也会增大,吞吐量上升
5.增大map输出的缓冲
io.sort.mb=300
----------------------------------------------------------------------------------
map处理会产生输出,通过shuffle会送给reduce,那么数据在没有拿走之前,数据会在内存或者磁盘上存放
当map输出在内存装不下,就会放到磁盘,map处理数据量不断增加,就需要往磁盘上面写。吧map输出的缓冲增大,意味着一次写出去的缓冲就多了
6.增加合并spill文件数量
io.sort.factor=50
----------------------------------------------------------------------------------
spill? map输出在内存中的数据写到Linux磁盘的过程叫做spill
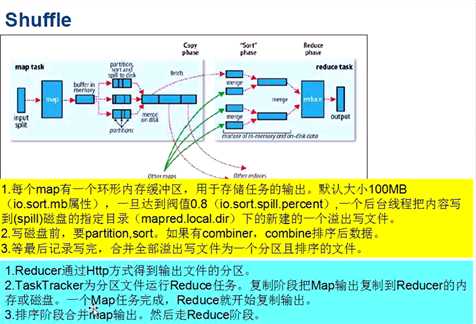
如果数据量较大,需要spill很多次,在磁盘上面就会产生很多的小文件。这种很多的小文件,
那么map端会把很多小文件合到一起合成一个文件,合的这个过程就是spill,如果合并的文件多的话,意味着合并次数少
磁盘合并会耗费内存和CPU,所以应该一次性输出到磁盘的大一些,合并的文件应该多一些,这样就会提高性能
7.map端输出压缩,推荐LZO压缩算法
mapred.compress.map.output=true
mapred.map.output.compression.codec=com.hadoop.compression.lzoCodec;
----------------------------------------------------------------------------------
map端输出进行压缩,占用磁盘少,shuffle数据量也少
8.增大shuffle复制线程数
mapred.reduce.parallel.copies=15
----------------------------------------------------------------------------------
shuffle是reduce端发起请求,然后啊map端的数据复制过去,如果并发线程多,吞吐量上去,会增加shuffle速度,减少时间,所以需要提高线程数
9.设置单个节点的map和reduce执行数量(默认是2)
mapred.tasktracker.map.tasks.maxinum=2
mapred.tasktracker.reduce.tasks.maxinum=2
----------------------------------------------------------------------------------
增大,意味着单机可以增加执行的数量,会对内存占用增加
标签:
原文地址:http://www.cnblogs.com/thinkpad/p/5048710.html