标签:
Link:http://www.cnblogs.com/Gavin_Liu/archive/2011/04/13/2011214.html
Keywords: Dynamic Programming; Recursive Methods
[这系列文章里会用到的一下符号和公式] 漫谈算法(番外篇) 符号标记以及基本数学公式
动态规划,Dynamic Programming。这里的programming没有翻译成编程,是因为,这里的programming的意思是指一个tabular method。其实这也暗示了DP的本质,用一个table保存子问题的中间结果。(后面会有例子具体介绍)
和分治算法比较类似,但不同的是分治算法把原问题划归为几个相互独立的子问题,从而一一解决,而动态规划则是针对子问题有重叠的情况的一种解决方案。
目前design DP主要有两个思路:
一个是利用recursive method,即首先把问题用递归的方法解决,然后用一个table保存recursive中的中间结果,这不就避免了递归中重复计算的低效了吗?遇到需要计算以前计算过的东西,直接查表就OK,总之一句话,先写recursive,然后比葫芦画瓢基本就能把DP的方法写出来。这里的难点是如何找到recursive。算法导论里面也给的是这个思路。下面的前三个例子全部出自《算法导论》。
另一个思路是exhaust search,这个好像是我们老师发明的方法,这里有篇Kirk的论文, How to design dynamic programming algorithms sans recursion 有兴趣的大家可以仔细研究一下,我下面也会简单举例介绍一下这个方法。
下面的例子中多数代码都是伪代码,旨在illustrate idea。同时节省时间。代码中都省去了backtrack的过程,即只得到了optimal solution的值,省去了如何construct optimal solution的过程。这个一般用一个数组记录一下就OK了。
先来个比较简单的例子(其实后面的也不难O(∩_∩)O~)
例:Rod-cutting problem(切木头问题。感觉翻译过来怎么就变了味呢?囧。。。)
Input:有一个长n米的木头,和一个price table,table如下:
长度 i 1 2 3 4 5 6 。。。
价格 Pi 1 5 8 9 10 17。。。
意思很明显,就是长度为1米的木头可以买1元,长5米的可以卖10元,依次类推
Output:找一个cut的方法,使最后赚的钱最多。
很显然,这个递归的主要思路是我切一刀之后,分成两段,一段我按table的价钱卖了,另一段我当成一个新的子问题,继续作为我的函数的新的参数,这样不就递归了吗?(*^__^*) 但是问题是这一刀怎么切,没错,我们就来个找最大值,即max_{i =1 to n} Pi + Cut(n-i).
所以,递归函数应该是:
Cut(P, n){ //P 就是我的table,n是木头长度
if n == 0
return 0;
q = -infinity
for i = 1 to n
q = max(q,P[i]+Cut(P,n-i))
return q;
}
然后,根据这个recursive写DP
Cut(P, n){
for(int i = 1; i<=n; i++){
q = -infinity;
for(int j = 1; j<=i; j++)
q = max(q, P[j] + r[i-j]);
r[i] = q;
}
return r[n];
}
例 最长公共字串 Longest common subsequence problem
问题描述:这个,很。。。显而易见吧,不知道的,。。。看这里 http://en.wikipedia.org/wiki/Longest_common_subsequence_problem
当然这里,我们也是要先找递归的。假设我的两个sequence,一个是X,长度为n;另一个是Y,长度为m。
现在假设我有两个point,一个是i,指在X的最后一个元素上,另一个是j,指在Y的最后一个元素上。我们的递归应该是分三种情况的。
1)如果X[i] == Y[j] 那么LCS(X[i],Y[j]) = LCS(X[i-1],Y[j-1]) + 1
这个很明显,因为发现了一组公共元素,就看剩下的有多少公共元素。
2) 如果X[i] != Y[j] 那么 LCS(X[i],Y[j]) = max( LCS(X[i-1], Y[j]), LCS(X[i], Y[j-1]) )
这个其实也很容易相同,就是如果发现不同的,就去掉X或Y的最后一个,然后和另一个完整的比较,这样去掉X还是Y的最后一个,就有两种可能,所以就是要找中间max的一个。
3) 如果 i=0 或者 j=0,就return 0
因为有一个sequence已经完了。
所以递归这里还是比较明显的:
LCS(n,m){
if m==0 || n==0
return 0;
if(X[n] == Y[m])
return LCS(n-1,m-1)+1;
else
return max( LCS(n,m-1), LCS(n-1,m) );
}
现在有了递归,我们就应该能把它写成tabular的DP。
初始化:Table LCS的第一行第一列都设为0。
for i = 1 to m
for j = 1 to n
if(X[i]==Y[j])
LCS[i,j] = LCS[i-1,j-1]+1;
else
LCS[i,j] = max(LCS[i,j-1], LCS[i-1,j] );
例 矩阵链相乘,求最小的乘法次数的问题
问题具体描述,看这里 http://en.wikipedia.org/wiki/Matrix_chain_multiplication
先形式化一下我们的input,矩阵链{A1,A2,...,An},其中对于矩阵Ai,它是一个Pi-1 * Pi的矩阵。m[i,j] 表示{Ai,Ai+1,..., Aj}相乘的最小的乘法次数(强烈呼吁出现一个类似Latex功能的插件)
这个递归的思路其实和第一个问题有点类似,先看怎么递归。
首先我们要找出一个点来分隔这个链,相当于这个点把这个问题转换为了 该点前一部分的矩阵链的最小的乘法次数问题和该点后一部分的矩阵链的最小的乘法次数问题。
但是这个点怎么找呢?和第一个例子一样,我们直接遍历的来找。
所以我们的递归应该是这样的:
m[i,j] = min_{i<= k <=j} (m[i,k] + m[k+1,j] + Pi-1*Pk*Pj)
当然,这是对于i!=j的情况,当i==j的时候呢?显然 是0了,因为我们的矩阵链就一个矩阵。
即
Matrix-chain(i,j){
if(i==j)
return 0;
q = infinity;
for k = i to j
q = min(q, Matrix-chain(i,k)+Matrix-chain(k+1,j)+Pi-1*Pk*Pj );
return q;
}
现在就是把这个recursive的东西搞成DP了。算法导论上有具体的代码,这里只写个简要的。
之类就假设我们保存中间结果的是一个n*n的table m.
初始化:m的对角元素初始化为0.
for l = 2 to n
for i=1 to n-l+1
j = i+l-1
m[i,j] = infinity
for k=i to j-1
q = m[i,k]+m[k+1,j]+Pi-1*Pk*Pj;
if(q < m[i,j])
m[i,j] = q;
return m
参照上面的recursive的例子,这个DP的代码应该不难理解。
例 最长回文序列
回文序列就是从左往右读和从右往左读是一样的。比如civic,racecar, and aibohphobia。其中长度为1的所有string都是回文的。
目标就是给一个string,找出这个string中最长的回文序列,比如给character,找出carac。
下面主要介绍一下,我们老师发明的那个方法,穷尽搜索加减枝~还是exhaust search with pruning好听 O(∩_∩)O~
这个方法的主要思想也就是首先通过构造一棵树,使得树的叶子节点成为一个可能的最终的解,换句话说也就是最后的答案一定蕴育在树的最下面一层的某个叶子节点中。很显然,一般情况下这个树还是比较好构造的,毕竟不用考虑什么条件,就是一个exhaust 展开的过程,但是随着这个树的展开,分枝越来越多,这样肯定是不make sense的,所以需要找到一些pruning rules,来修剪这棵树。其实说了半天,肯定也比较模糊,还是先看个例子吧,我觉得看完例子,在看这段话肯定比较有感觉。
例 最长递增字串
问题描述:http://en.wikipedia.org/wiki/Longest_increasing_subsequence_problem (其实显而易见)
假设我的一串input是 X1,X2,X3,。。。,Xn,按下图构造我们的树(enumeration tree)。
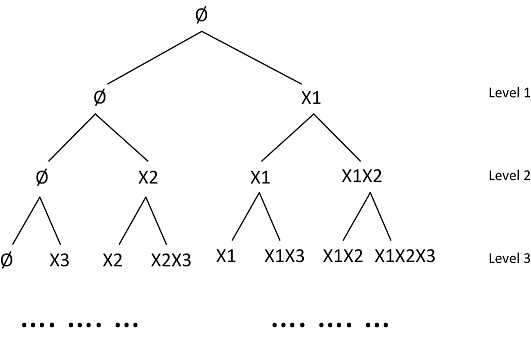
如何构造这棵树通过上面这个图,我想应该显而易见了吧,最终我的的解一定是在某个叶子节点上的。
在这里,最主要的是找到prunning rules。
当然对于这个LIS问题来说,什么才是我们的prunning rules呢?
1)很显然,如果某个节点的序列不是递增的,我们应该直接剪掉,因为。。。显然啊~
2)对于同一层的节点来说,如果同一层的某两个节点具有相同的递增长度,我们应该保留 那个序列,他的最后一个元素的数值最小。(怎么感觉说的这么别扭。怒)比如在某一层上 一个节点是 2 4 7, 另一个节点是 3 4 6,他们的递增长度都是3,但是因为6<7,所以我们应该保留3 4 6,把2 4 7这个节点直接剪掉。
3)对于同一层的节点来说,如果某两个节点最后一个元素的数值一样,我们应该保留长度较长的那个节点,剪掉较短的那个。举例:一个节点 2 3 6,一个节点 3 6, 我们保留 2 3 6,剪掉 3 6。
其实我们可以发现,(2)(3)实际上说的是一回事,所以,我们可以根据(1)(2)写出我们的DP,也可以根据(1)(3)写出我们的DP。
神马?这样就可以了?Yes, it‘s too simple, sometimes naive???!!!
根据(1)(2)
A[l,s] 这个是我们table A里面的一个cell,l表示树的level,s表示长度,A[l,s]表示在该节点的最后一个元素的数值。
for l = 1 to n
for s = 1 to l
if A[l,s] then
A[l+1,s] = min(A[l+1,s], A[l,s])
if A[l,s] < X_{l+1} then
A[l+1,s+1] = min(A[l+1,s+1], X_l+1)
根据(1)(3)
A[l,s] 这个是我们table A里面的一个cell,l表示树的level,s表示该节点的最后一个元素的下标,即最后一个元素是Xs,A[l,s]表示长度。
for l = 1 to n
for s = 1 to l
if A[l,s] then
A[l+1,s] = max(A[l+1,s], A[l,s])
if Xs < X_{l+1} //如果在l+1层新添加的元素可以增加我们的序列的长度
//A[l+1,s]+1 表示在原来的基础上在加上这个新元素
//A[l+1,l+1] 表示在以新来的的元素X_{l+1}结尾的序列中,找一个最长的出来。
A[l+1,l+1] = max(A[l+1,l+1], A[l+1,s]+1)
例 找零钱问题
Input: 若干个Coins, X1,X2,..., Xn 和一个 数值 L
Output: 能不能用上面的若干面值的Coins 凑成 正好是L的金额。
同样,在这个问题中,和前面LIS中构造树的方法一样。
现在来看看我们的prunning rules。
1)如果某个节点的面值总和大于L,直接剪掉。
2)同一个level上,如果有两个节点的面额一样,随便剪掉一个。
恩,这个剪枝规则更简单了。
下面写DP。
用sum(l,s)=1 来表示在第l层,面额s是可以取到的。
for l = 1 to n
for s = 1 to L
if sum(l,s) then
sum(l+1,s) = 1
if sum(l,s) + X_{l+1} < L
sum(l+1,s+X_{l+1}) = 1
例 背包问题
Input:若干个物品,X1,X2,...,Xn,他们的价值是V1,V2,...,Vn,他们的重量是W1,W2,...,Wn,和给你一个重量的limit L,
Output:在weight总和less than L的情况下,拿哪些物品,使他们的value最大。
同样,在这个问题中,和前面LIS中构造树的方法一样。
现在来看看我们的prunning rules。
1)如果某个节点的重量的总和超过了L,剪掉。
2)在同一层,如果某两个节点具有相同的weight,剪掉value小的。
3)在同一层,如果某两个节点具有相同的value,剪掉weight大的。
和LIS的例子一样,我们可以用(1)(2)也可以用(1)(3)
下面写DP。
根据(1)(2)
sum(l,s)表示在l层重量为s的某个节点的value
for l = 1 to n
for s = 1 to \sum_{i=1}^l Wi (latex的标记方法,无奈,这个editor里没法打数学公式)
if sum(l,s) then
sum(l+1,s) = max( sum(l+1,s), sum(l,s) )
if sum(l,s) + X_{l+1} < L then
sum(l+1, s+X{l+1}) = max( sum(l+1, s+X{l+1}), sum(l,s) + V_{l+1})
根据(1)(3)的这里就不写了,和上面的原理一样,比葫芦画瓢就应该能写出来。
例:字符串pattern匹配
Input: 一序列字符串X[m],每个字符带cost: A(3) B(4) B(6) A(2) C(2) C(5) A(1) ....,假设该字符串长为m;一个待匹配的pattern Y[n]: A B A C...,假设pattern的长为n
Output: 找到一个cost和最小的字符串,匹配pattern(这里的匹配各个字符在原字符串中是可以有间隔的,例如字符串是A(3) B(4) B(6) A(2) C(2) C(5) A(1),pattern是ABAC,我可以取A(3) B(6) A(2) C(5),这样总cost是3+6+2+5 = 16 )
作为最后一个例子,将用上面提到的两种方法来解决这个问题。
首先,我们来找找递归的方法。
其实这个思路和找最长公共字串的问题有一些相似。这里扫描给定的字符串序列还是pattern都是从最后一个字符开始往前扫描。
Cost(i, j) 有这么几种情况,
1)i == 0,直接返回infinity。因为这也就表示我们没有在给定的字符串X中找到我们的pattern Y。
2)j == 0,直接返回0。表示我们找到了目标。
3)if X[i] != Y[j],return Cost(i-1,j)这个时候,由于我们的pattern没有匹配,所以我们只能进行探索X下一个字符。注意这里j没有减一,很显然,因为pattern没有匹配(再多啰嗦一句)
4)if X[i] == Y[j],return min(Cost(i-1,j-1)+c(X[i]), Cost(i-1,j) ) 这里的min表示,当我们遇到一个匹配的时候,我们有两个选择,用这个X中的字符当作我们最后匹配中的一个,也可以是我们放弃这次匹配,继续往下找。
下面把这个recursive写完整。
Cost(m,n){
if(m == 0)
return infinity;
if (n == 0)
return 0;
if(X[m] != Y[n])
return Cost(m-1, n);
else
return min( Cost(m-1,n-1)+c(X[i]), Cost(m-1,n) );
}
下面老规矩,根据recursive call 写DP。
假设我们的table是一个m*n的table,那么
当然很显然,在这个问题的初始化的时候,我们要把m=0的那一行初始化为无穷大,把n=0的那一列初始化为0. 在初始化完后,
for(int i = 0; i < m; i++)
for(int j = 0; j< n; j++){
if X[i] != Y[j]
Cost[i,j] = Cost[i-1,j];
else
Cost[i,j] = min( Cost[i-1,j-1]+c(X[i]), Cost[i-1,j] );
}
现在我们来考虑怎么用exhaust search的方法解决这个问题。
还是和上面的那个图一样的树。我们知道X的size是m,所以我们可以穷举中他的字串,一共2^m个,我们最后匹配的pattern一定是这2^m中的一个,所以我们按照这个思路构造我们的树,这棵树一共有m层。每一层得节点A[l,s]表示在l层,匹配了pattern中s个字符的最小cost。
很显然,我们的prunning rules是 对于同一层中的两个节点,如果他们匹配的长度相等,即s相等,我们应该prune掉那个cost大的。
for(int l = 0; l < m; l++)
for(int s = 0; s < l; s++){
if A[l,s] then
A[l+1,s] = min( A[l+1,s], A[l,s]);
if X[l+1] == Y[s+1]
A[l+1,s+1] = min( A[l+1,s+1], A[l+1, s] + cost(X[l+1]))
}
最后啰嗦一句,这个exhaust search的方法其实也不是一下子很容易让人理解,所以,还是推荐看一下老师的一个tutorial的论文 How to design dynamic programming algorithms sans recursion 。
标签:
原文地址:http://www.cnblogs.com/lucky-star-star/p/5053448.html