标签:
1.集群调用失败时,Dubbo提供了多种容错方案。
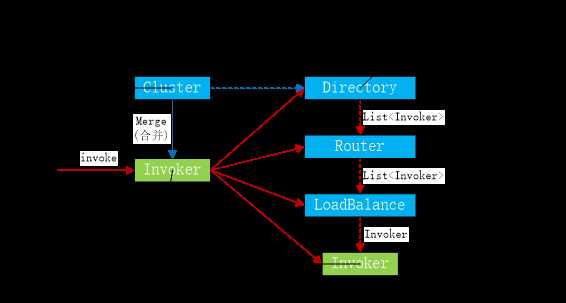
各节点关系:
2.集群容错模式(可自行扩展集群容错策略,详见http://dubbo.io/Developer+Guide-zh.htm#DeveloperGuide-zh-%E9%9B%86%E7%BE%A4%E6%89%A9%E5%B1%95):
Failover Cluster
失败自动切换,当出现失败,重试其它服务器。(缺省)
通常用于读操作,但重试会带来更长延迟。
可通过retries="2"来设置重试次数(不含第一次)。
Failfast Cluster
快速失败,只发起一次调用,失败立即报错。
通常用于非幂等性的写操作,比如新增记录。
Failsafe Cluster
失败安全,出现异常时,直接忽略。
通常用于写入审计日志等操作。
Failback Cluster
失败自动恢复,后台记录失败请求,定时重发。
通常用于消息通知操作。
Forking Cluster
并行调用多个服务器,只要一个成功即返回。
通常用于实时性要求较高的读操作,但需要浪费更多服务资源。
可通过forks="2"来设置最大并行数。
Broadcast Cluster
广播调用所有提供者,逐个调用,任意一台报错则报错。(2.1.0开始支持)
通常用于通知所有提供者更新缓存或日志等本地资源信息。
3.重试次数配置(Failover集群模式生效)如下:
1 <dubbo:service retries="2" />
或
1 <dubbo:reference retries="2" />
或
1 <dubbo:reference>
2 <dubbo:method name="findFoo" retries="2" />
3 </dubbo:reference>
4.集群模式配置如下:
1 <dubbo:service cluster="failsafe" />
或
1 <dubbo:reference cluster="failsafe" />
标签:
原文地址:http://www.cnblogs.com/songjie-xuan/p/5075185.html