标签:
一直以为spark区分几种集群的模式是由配置更改而改变.
经过使用发现,区分这几种模式的在于启动命令时指定的master.
现在保持我的配置文件不变.
#公共配置 export SCALA_HOME=/usr/local/scala/ export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.65.x86_64/ export SPARK_LOCAL_DIRS=/usr/local/spark-1.5.1/ export SPARK_CONF_DIR=$SPARK_LOCAL_DIRS/conf/ export SPARK_PID_DIR=$SPARK_LOCAL_DIRS/pid_file/ #YARN export HADOOP_HOME=/usr/local/hadoop-2.6.0 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop/ #standalone #export SPARK_MASTER_IP=a01.dmp.ad.qa.vm.m6 #export SPARK_MASTER_PORT=7077 #每个Worker进程所需要的CPU核的数目 #export SPARK_WORKER_CORES=4 #每个Worker进程所需要的内存大小 #export SPARK_WORKER_MEMORY=6g #每个Worker节点上运行Worker进程的数目 #export SPARK_WORKER_INSTANCES=1 #work执行任务使用本地磁盘的位置 #export SPARK_WORKER_DIR=$SPARK_LOCAL_DIRS/local #web ui端口 export SPARK_MASTER_WEBUI_PORT=8099 #Spark History Server配置 export SPARK_HISTORY_OPTS="-Dspark.history.retainedApplications=20 -Dspark.history.fs.logDirectory=hdfs://a01.dmp.ad.qa.vm.m6:9000/user/spark/applicationHistory"
我们使用standalone的方式起了一个spark-shell
在命令行执行如下命令:
$ spark-shell --master spark://a01.dmp.ad.qa.vm.m6.youku:7077
先看spark UI页面
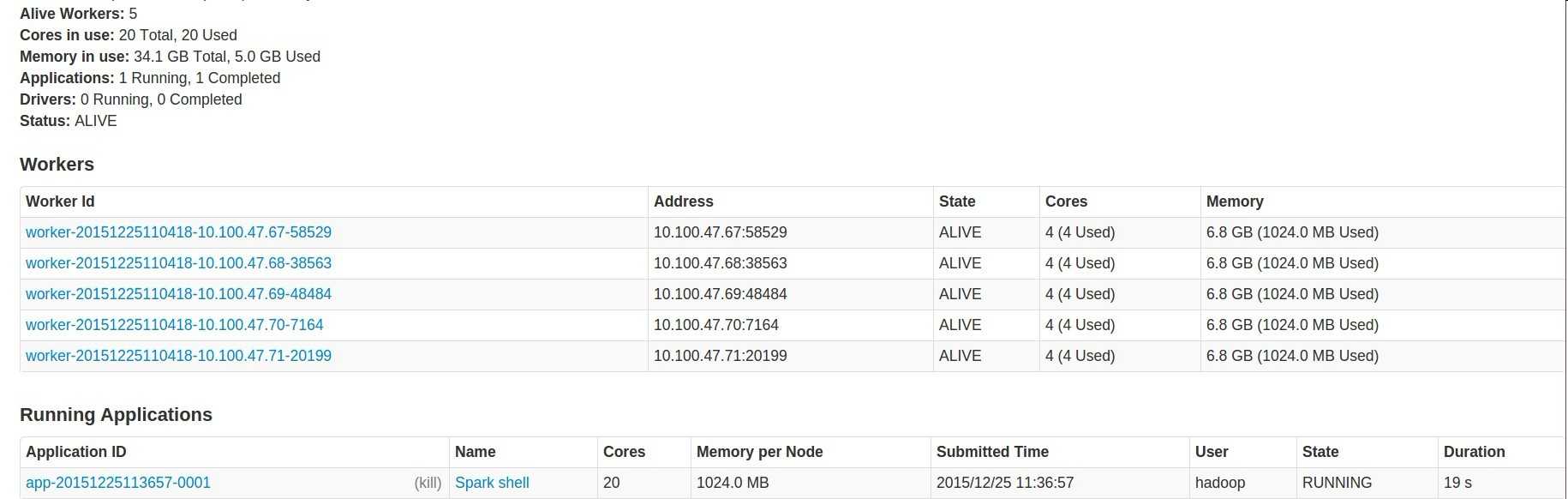 在spark ui的running Applicatioin中看到刚才启动的那个shell.
在spark ui的running Applicatioin中看到刚才启动的那个shell.
看hadoop 任务管理页面
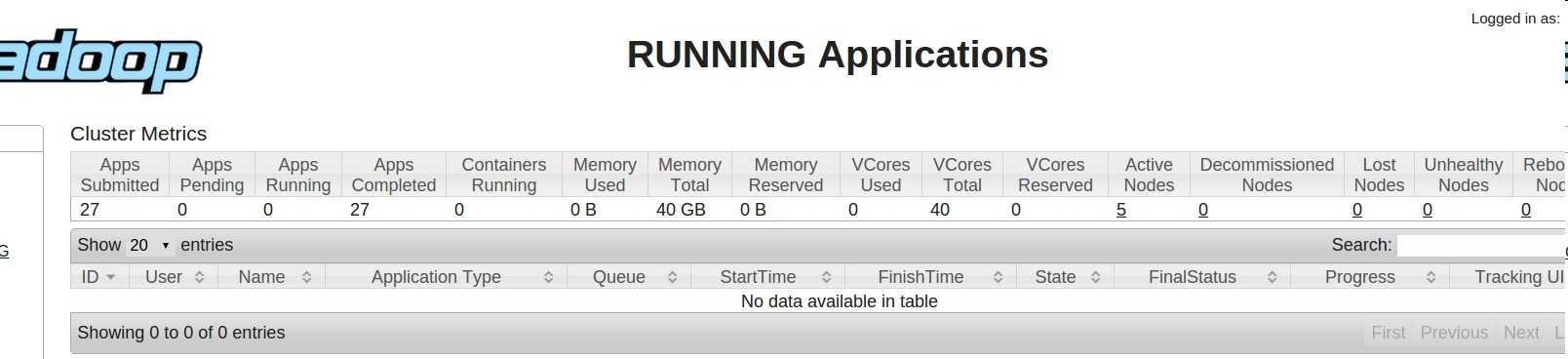
没有运行中的任务.
使用spark on YARN的方式再起一个spark-shell
$ spark-shell --master yarn-client
再看刚才上面那2个页面.发现yarn的作业管理界面现在有一个running app,而spark作业管理页面是没有running app的.
至此,我知道了.我们常说的 #你的spark是装的standalone的么#,#你的spark是装的on yarn的么# 这种说法都是不正确的.
spark任务已什么方式提交,是看提交命令时指定的master,而非配置控制的
标签:
原文地址:http://www.cnblogs.com/pingjie/p/5075477.html