标签:
找出相同单词的所有单词。现在,是拿取部分数据集(如下)来完成本项目。
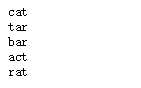
项目需求
一本英文书籍包含成千上万个单词或者短语,现在我们需要在大量的单词中,找出相同字母组成的所有anagrams(字谜)。
基于以上需求,我们通过以下几步完成:
1、在 Map 阶段,对每个word(单词)按字母进行排序生成sortedWord,然后输出key/value键值对(sortedWord,word)。
2、在 Reduce 阶段,统计出每组相同字母组成的所有anagrams(字谜)。
1 首先,打开MyEclipse,
在com.dajiangtai.hadoop.test包下,新建Anagram类。添加main方法。
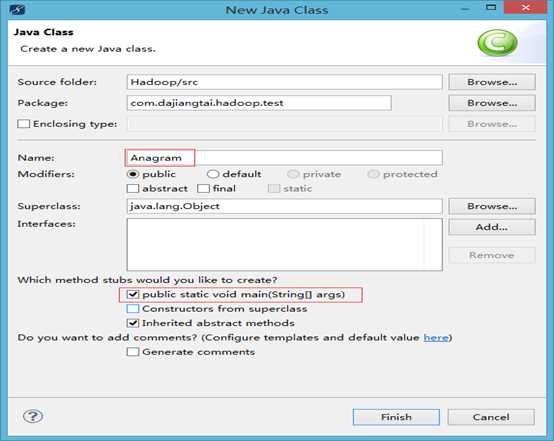
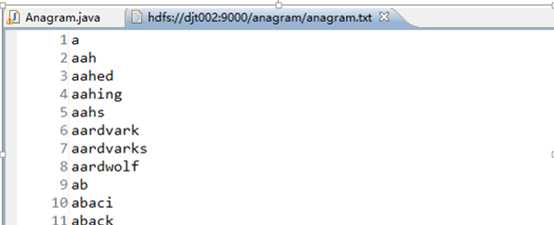
2 、在如下文件夹下,新建anagram文件夹
3 上传数据源anagram.txt
在anagram文件夹的位置,右键,upload fles to DFS,
4 、编写Anagram.java里的代码。见Anagram.java.txt
代码编写完成后,然后就可以进行Run as -> 1 java application 。
刷新后,如下。
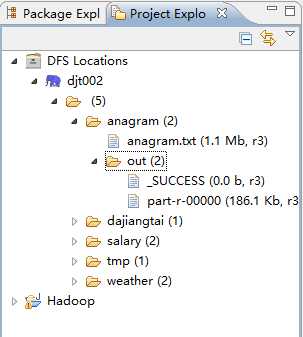
5 、接下来,点击part-r-00000(186.1 kb,r3),则出现。
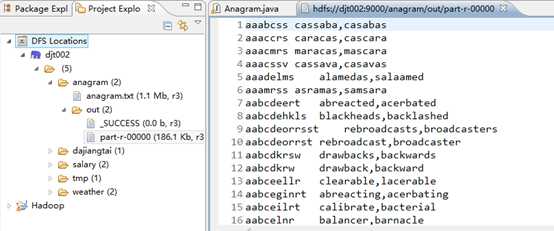
那么,此刻,在本地上已经成功运行。
6 、现在,需要到集群上去成功运行,这该怎么做呢?
Hadoop -> Export -> Export,
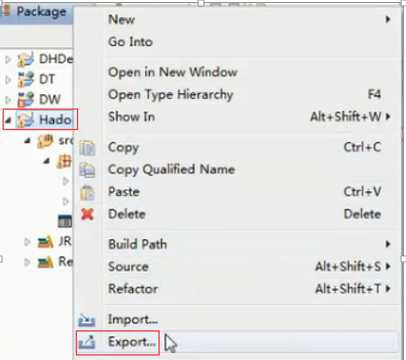
Java -> JAR file -> next
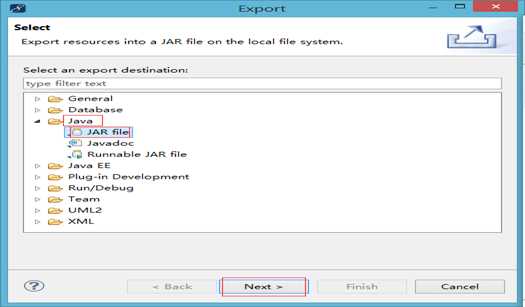
7 、因为,在hadoop里,这些依赖的架包是存在的,所以我们就不需要再多此一举再打包了。
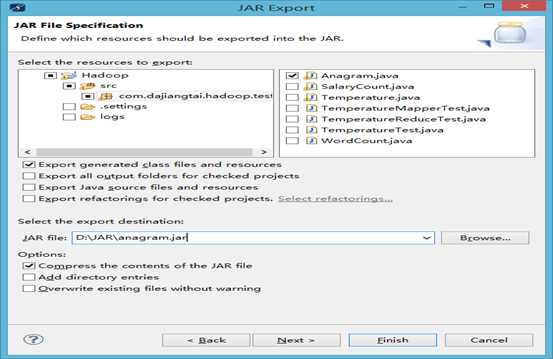
为架包取一个名称,为anagram.jar,先在D盘新建文件夹JAR,存放在D:\JAR\anagram.jar,点击finish。
8、 接下来,用xshell来连接CentOS。
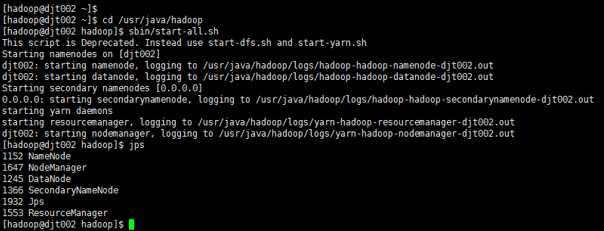

9 、rz,打开D:\JAR\anagram.jar ,上传至CentOS

10、执行命令
hadoop jar anagram.jar com.dajiangtai.hadoop.test.Anagram /anagram/ /anagram/out/

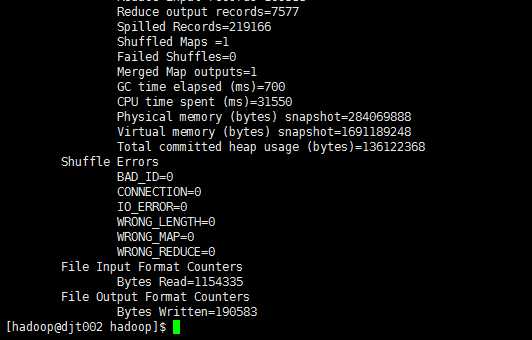
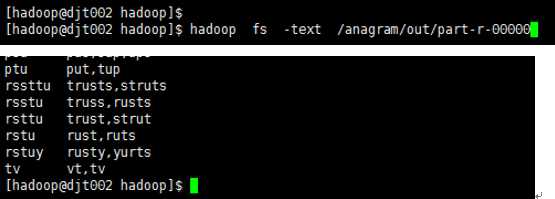
11、 查看结果
hadoop fs -text /anagram/out/part-r-00000
标签:
原文地址:http://www.cnblogs.com/zlslch/p/5078072.html