标签:
1.什么是哈希表?
哈希表是一种数据结构,它可以提供快速的插入和删除操作。如果存储在哈希表中的数据较好的满足了哈希表的要求,那么在哈希表中执行插入和操作只需要接近常量的时间,即时间复杂度为o(1),但哈希表也不是十全十美的,它也存在着缺点,这都会在下面慢慢谈到.
2.哈希表的存储方式
哈希表是通过数组来存储数据的,但数据并不是直接放入数组中(直接放入就是数组存储啦!)。说到这里就需要谈到哈希化,而哈希表的核心部分,我认为就是哈希化了:简而言之,将数据插入哈希表中的数组的相应位置的规则,就是哈希化,再简单来说,就是将数据通过某种方法(即哈希函数,可以自己定义)转化得到一个数据下标(这就是这个数据应该存储的位置),将该数据放入到该下标对应的数组位置中,使用哈希函数向数组中插入数据,得到的就是一个哈希表。这里来用一个简单的示例来向大家介绍哈希表:
如果我们需要存储5个数据:5 、 31、 58 、75 、87 存储在容量为10的哈希表中。
1.首先,我们需要定义一个哈希函数,我这里的定义的哈希函数为 arrayIndex = Number % arraySize;这里arrayIndex就对应着要插入的数组坐标位置;
2.计算数组下标,上面的数据计算结果为:5, 1, 8,5,7
3.向数组中插入数据,得到哈希表
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
|
31 |
|
|
|
5 |
75 |
87 |
58 |
|
这样子来看,是不是简单的!但事实上对于这几个数据来说确实挺简单的。但是这里我们还有很多东西没有去讨论,大家继续向下看:
大家注意到没有,5和75得到的数组下标都是5,它们产生了冲突,那它怎么插入到数组中的呢?对于这种情况有很多中方式处理,这里用的是开放地址法的线性探测方法。
这里就介绍这几中解决这种冲突的方法
3.冲突解决
这里解决的方法主要有两种:开放地址法和链地址法
一、开放地址法
开放地址法包括三种方法:线性探测(上面用到的)、二次探测、再哈希法。
1.线性探测
在线性探测的方法中,当冲突产生时会线性的查找空白单元。正如上面所提到的,当插入75时,因为当前数组下标为5的位置被数据 5 所占据,因此数组下标就会继续向下查找,此时下标为5的数组位置是空闲的,数据75就插入其中;如果此时我们再插入一个元素45,开始查询数组下标位置为5的数组位置,不为空---》查询数组下标为6:不为空---》查询数组下标为7:不为空---》查询数组下标为8:不为空---》查询数组下标为9:为空---》在数组下标为9的位置插入45.
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
|
31 |
|
|
|
5 |
75 |
87 |
58 |
45 |
哈希表中,一连串的已填充单元叫做填充序列,增加越来越多数据项,填充序列就越来越长,这叫做聚集。例如上图中的位置5-9中数据。这个时候就需要思考一个问题,如果数据大量聚集的话,会怎么样呢?对于线性探测来说,查找和插入的一个数据项就会花费更多的时间,事实上对于一个存储大量数据的哈希表来说,此时的效率非常低。
2.二次探测
在线性探测的方法中,易发生聚集。一旦聚集形成,它就会越来越大。那些后来哈希化后的落在聚集范围周围的数据,都要一步步移动,并且插入到聚集的最后,因此聚集再一次变大。聚集越大,会有更多的数据落在这个范围内,就这样会形成恶性循环,极大地影响哈希表的效率。
已填入哈希表中的数据项和表长的比率称为装填因子。有10000个数据,如果填入6667个数据,那么他的装填因子就是2/3。当装填因子不太大时,聚集就会比较连贯。哈希表的某个部分可能包含大量的聚集,而另一部分可能还很稀疏。
二次探测是防止聚集的一种尝试(并不能解决全部的聚集问题),思想不再是顺序探测下一个位置,而是间隔的探测下一个位置。如果原始下标是x,那么在线性探测中,探测的位置为x,x+1,x+2。。。;而在二次探测中探测的则是x+1,x+4,x+9。。。
二次探测消除了在线性探测中产生的聚集问题,这种聚集问题叫做原始聚集。可是我们想一想插入一些特殊的数据时:5,15,25,35。。。之类的数据,就会发现在探测空位置时,它们的探测的顺序总是一样的,这种情况也是一种聚集,只不过相比于线性探测,它更加不容易产生,这种现象叫做二次聚集。
3.再哈希法
为了消除原始聚集和二次聚集,可以使用另一个方法:再哈希法。
在再哈希法中,是把第一次产生的由哈希函数产生的哈希值(第一个数组下标),使用另一个哈希函数再次哈希化,得到的另一个新的值,来作为探测的步长。第二个哈希函数必须具备两个特点:1.和第一个哈希函数不同。2.不能输出为零(否则将没有步长,每次探测都会是相同位置)。专家们发现下面形式的哈希函数工作的非常好:stepSize = constant * (key % constant);其中constant是质数,且小于数组容量。例如:stepSize = 5 * (key % 5)。示例:
对于上面的例子:当我们插入5、75、45 时,5插入到下标为5的位置中(这里的二次哈希的函数用的是上面的示例),但是75用再哈希法得到的探测步长却为0,45得到的探测步长为也为0,这无疑不是一个好消息。此时就牵扯到另一个问题:数组的容量选取。对于哈希表中的容量,应该总是选取一个质数,例如上面的数组长度应该选取11来代替10(后面的例子就用数组长度11)。如果数组容量不是质数,就容易出现上面的探测步长为0情况,那么探测步长就会变得无限长。
如果此时用数组容量11来代替数组容量10 。插入5、75、45时,75得到的探测步长是20,45得到的探测步长为5。(如果只使用再哈希化法,在constant选取5时,对于除了第一次哈希为5的,剩下哈希化为5的插入就会报错)。
二、链地址法
在开放地址法中,通过在哈希表中寻找到一个空位来解决冲突问题。另一个方法是在哈希表中的每个单元中设置链表,某个数据项的关键字值还是像往常一样映射到哈希表的单元中,而数据项本身则插入到链表中。其他的产生冲突的数据项只需要加到链表中就可以了,不再去寻找空位。
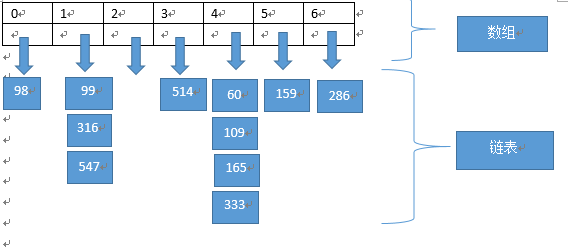
三、代码实现哈希表(java实现)
开放地址法:
定义的数据类:
/* * 存储的数据类 */ public class DataItem { private int iData; public DataItem(int i){ iData = i; } public int getkey(){ return iData; } }
线性探测和二次探测的只有一点点区别、这里贴出线性探测的代码:
package hash; /* *******************顺序哈希算法 ******************* */ public class HashTable { private DataItem[] hashArray; private int arraySize; private DataItem nonItem; //结构体 public HashTable(int size){ arraySize = size; hashArray = new DataItem[arraySize]; nonItem = new DataItem(-1); } //显示哈希表 public void displayTable(){ System.out.print("Table: "); for (int j = 0; j < arraySize; j++) { if (hashArray[j]!=null) { System.out.print(hashArray[j].getkey()+" "); }else { System.out.print("** "); } } System.out.println(""); } //hashFunc public int hashFunc(int key){ return key%arraySize; } //insert public void insert(DataItem item) { int key = item.getkey(); int hashVal = hashFunc(key); while(hashArray[hashVal]!=null&&hashArray[hashVal].getkey()!=-1){ ++hashVal; hashVal %= arraySize; } hashArray[hashVal] = item; } //delete public DataItem delete(int key){ int hashVal = hashFunc(key); while(hashArray[hashVal]!=null){ if (hashArray[hashVal].getkey()==key) { DataItem temp = hashArray[hashVal]; hashArray[hashVal] = nonItem; return temp; } ++hashVal; hashVal %= arraySize; } return null; } //find public DataItem find(int key){ int hashVal = hashFunc(key); while(hashArray[hashVal]!=null){ if (hashArray[hashVal].getkey()==key) { DataItem temp = hashArray[hashVal]; return temp; } ++hashVal; hashVal %= arraySize; } return null; }
}
再哈希法:
package hashDouble; /* * 哈希表的使用:再哈希存储 */ public class HashTable { private DataItem[] hashArray; private int arraySize; private DataItem nonItem; //contruct public HashTable(int size){ arraySize = size; hashArray = new DataItem[arraySize]; nonItem = new DataItem(-1); } //displayTable public void displayTable(){ System.out.print("Table: "); for (int i = 0; i < arraySize; i++) { if (hashArray[i]!=null) { System.out.print(hashArray[i].getKey() + " "); }else { System.out.print("** "); } } } //hashFuc public int hashFuc(int key){ return key%arraySize; //arraySize为哈希表的长度 } public int hashFuc2(int key){ return 5-key%5; } //insert public void insert(int key, DataItem item){ int hashVal = hashFuc(key); int stepSize = hashFuc2(key); while (hashArray[hashVal]!=null&&hashArray[hashVal].getKey()!=-1) { hashVal += stepSize; hashVal %=arraySize; } hashArray[hashVal]=item; } //delete public DataItem delete(int key){ int hashVal = hashFuc(key); int stepSize = hashFuc2(key); while (hashArray[hashVal]!=null) { if (hashArray[hashVal].getKey()==key) { DataItem temp = hashArray[hashVal]; hashArray[hashVal]=nonItem; return temp; } hashVal += stepSize; hashVal %= arraySize; } return null; } //find public DataItem find(int key){ int hashVal = hashFuc(key); int stepSize = hashFuc2(key); while (hashArray[hashVal]!=null) { if (hashArray[hashVal].getKey()==key) { return hashArray[hashVal]; } hashVal += stepSize; hashVal %= arraySize; } return null; } }
操作Mian主类(看下方)
链地址法较为复杂,希望大家能好好看看:
数据类:
package linkHash; /* * 定义的链表中存储的数据 */ public class Link { private int iData; public Link next; public Link(int item){ iData = item; } public int getKey(){ return iData; } public void disPlayItem(){ System.out.print(iData + " "); } }
链表的定义:
package linkHash; /* * 排序链表的实现 */ public class SortedList { private Link first; //构造体 public SortedList(){ first = null; } //插入链表 public void insert(Link theLink){ int key = theLink.getKey(); Link previous = null; Link current = first; while (current != null && key > current.getKey()) { previous = current; current = current.next; } if (previous == null) { first = theLink; }else{ previous.next = theLink; } theLink.next = current; } //删除链表 public void delete(int key) { Link previous = null; Link current = first; while(current!=null && key != current.getKey()){ previous = current; current = current.next; } if (previous == null) { first = first.next; }else { previous.next = current.next; } } //find public Link find(int key){ Link current = first; while (current != null && key >= current.getKey()) { if (current.getKey()==key) { return current; } current = current.next; } return null; } //displayList public void displayList(){ Link current = first; System.out.print("List(first--->last):"); while (current != null) { current.disPlayItem(); current = current.next; } System.out.println(""); } }
哈希表的定义:
package linkHash; public class HashTable { private SortedList[] hashList; private int arraySize; //HashTable() public HashTable(int size){ arraySize = size; hashList = new SortedList[arraySize]; for (int j = 0; j < arraySize; j++) { hashList[j] = new SortedList(); } } //hashFunc public int hashFunc(int key) { return key%arraySize; } //insert public void insert(Link theLink){ int key = theLink.getKey(); int hashVal = hashFunc(key); hashList[hashVal].insert(theLink); } //delete public void delete(int key){ int hashVal = hashFunc(key); hashList[hashVal].delete(key); } //find public Link find(int aKey){ int hashVal = hashFunc(aKey); Link theLink = hashList[hashVal].find(aKey); return theLink; } //displayTable public void displayTable(){ for (int j = 0; j < arraySize; j++) { System.out.print(j + "."); hashList[j].displayList(); } } }
操作主类:
package linkHash; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; public class linkHashApp { public static void main(String[] args) throws IOException { int aKey; Link aDataItem; int size,n,keysPerCell = 100; System.out.print("Enter size of hash table:"); size = getInt(); System.out.print("Enter initial number of items:"); n = getInt(); HashTable theHashTable = new HashTable(size); for (int j = 0; j < n; j++) { aKey = (int)(java.lang.Math.random() * keysPerCell * size); aDataItem = new Link(aKey); theHashTable.insert(aDataItem); } while (true) { System.out.print("Enter first letter of show, insert, delete, find:"); char choice = getChar(); switch (choice) { case ‘s‘: theHashTable.displayTable(); break; case ‘i‘: System.out.print("Enter a key to insert:"); aKey = getInt(); aDataItem = new Link(aKey); theHashTable.insert(aDataItem); break; case ‘d‘: System.out.print("Enter a key to delete:"); aKey = getInt(); theHashTable.delete(aKey); break; case ‘f‘: System.out.println("Enter a key to find:"); aKey = getInt(); aDataItem = theHashTable.find(aKey); if (aDataItem != null) { System.out.println("Found " + aKey); }else{ System.out.println("Can‘t found " + aKey); } break; default: break; } } } public static String getString() throws IOException{ InputStreamReader in = new InputStreamReader(System.in); BufferedReader buff = new BufferedReader(in); String s = buff.readLine(); return s; } public static int getInt() throws IOException { return Integer.parseInt(getString()); } public static char getChar() throws IOException{ return getString().charAt(0); } }
---------------------------------------------------------------------------------------------------------------
总结所得,里面有什么谬误的地方,欢迎大家指正。如果有什么建议和看法,欢迎大家留言。
标签:
原文地址:http://www.cnblogs.com/mercuryli/p/5084294.html