标签:
了解了HDFS体系结构中的名字节点、数据节点和客户端以后,我们来分析HDFS实现的源代码结构。HDFS源代码都在org.apache.hadoop.hdfs包下,其结构如图6-3所示。
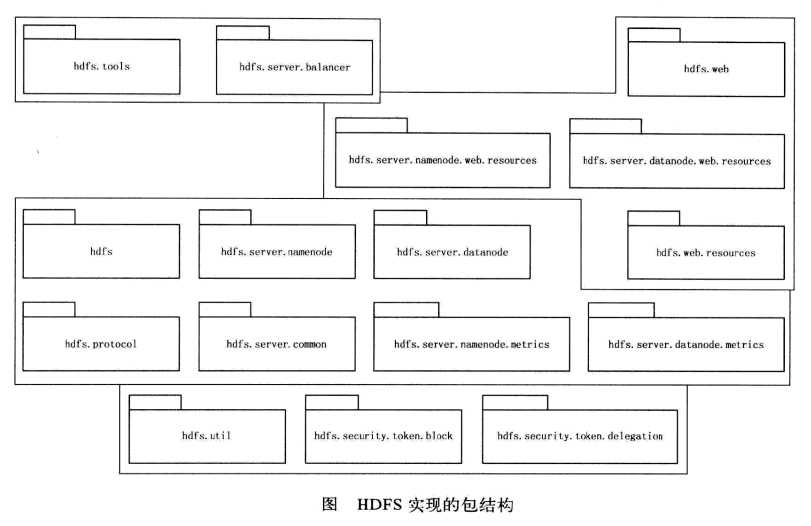
HDFS的源代码分布在I6个目录下,它们可以分为如下四类。
1.基础包
包括工具和安全包。其中,hdfs.util包含了一些HDFS实现需要的辅助数据结构:hdfs.security.token.hlock和hdfs.security.token.delegation结合Hadaop的安全框架,提供了安全访问HDFS的机制。该安全特性最先是由Yahoo开发的,集成了企业广泛应用的Kerberos标准,使得用户可以在一个集群管理各类商业敏感数据。
2.HDFS实体实现包
这是代码分析的重点,包含7个包:
hdfs.server.common包含了一些名字节点和数据节点共享的功能,如系统升级、存储空间信息等。
hdfs.protocol提供了HDFS各个实体间通过IPC交互的接口。hdfs.server.datanode和hdfs分别包含了名字节点、数据节点和客户端的实现。上述代码是HDFS代码分析的重点。
hdfs.server.namennde.metrics和hdfs.server.datanode.metrics实现了名字节点和数据节点上度量数据的收集功能。度量数据包括名字节点进程和数据节点进程上事件的计数,例如数据节点上就可以收集到写入字节数、被复制的块的数量等信息。
3.应用包
包括hdfs.tools和hdfs.server.balancer,这两个包提供查询HDFS状态信息工具dfsadmin、文件系统检查工具fsck和HDFS均衡器balancer(通过start-balancer. sh启动)的实现。
4. WebHDFS相关包
包括hdfs.web.resources, hdfs.server.namenode.web.resourees, hdfs.server.datanode.web.resources和hdfs.web共4个包。
WebHDFS是HDFS 1.0中引入的新功能,它提供了一个完整的、通过HTTP访问HDFS的机制。对比只读的hftp文件系统,WebHDFS提供了HTTP上读写HDFS的能力,并在此基础上实现了访问 HDFS的C客户端和用户空间文件系统〔FUSE)。
标签:
原文地址:http://www.cnblogs.com/zlslch/p/5089745.html