标签:
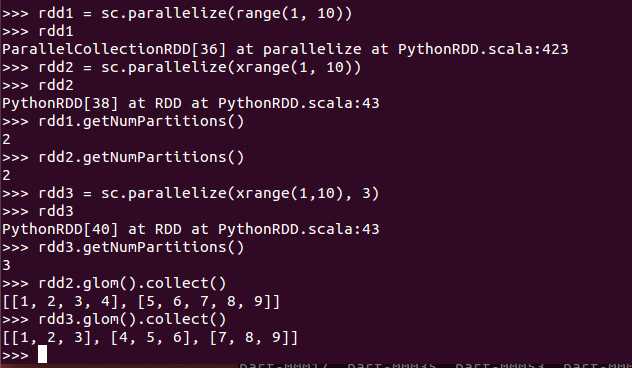
sc.parallelize():创建RDD,建议使用xrange
getNumPartitions():获取分区数
glom():以分区为单位返回list
collect():返回list(一般是返回driver program)
例子:
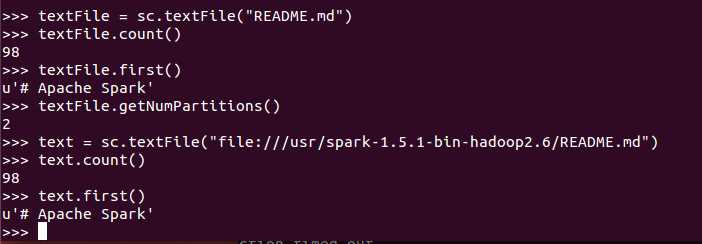
sc.textFile(path):读取文件,返回RDD
官网函数:textFile(name, minPartitions=None, use_unicode=True)
支持读取文件:a text file from HDFS, a local file system (available on all nodes), or any Hadoop-supported file system URI, and return it as an RDD of Strings.
例子(本地文件读取)
Spark Programming--Fundamental operation
标签:
原文地址:http://www.cnblogs.com/loadofleaf/p/5090134.html