标签:
本教程使用Vultr的VPS搭建,主要实现HDFS和MapReduce两个功能。
master.hadoop - 45.32.90.100 slave1.hadoop - 45.32.92.47 slave2.hadoop - 45.32.89.205
一、准备
使用SSH登录到三台VPS
修改主机名,修改以下两个文件
/etc/hosts
/etc/sysconfig/network
并在/etc/hosts末尾,增加主机名:
45.32.90.100 master.hadoop 45.32.92.47 slave1.hadoop 45.32.89.205 slave2.hadoop
停用iptables防火墙
service iptables stop
二、配置SSH
配置SSH公私钥(无密码)登录
目标:master可以访问所有slave,每个slave可以访问master,每个机器可以访问自己
实现:可以使用ssh-keygen,生成公私钥,并将公钥id_rsa.pub追加到目标机器的./ssh/authorized_keys中
在master中分别访问自己和所有slave,并输入“yes”初始化公钥
ssh master.hadoop ssh slave1.hadoop ssh slave2.hadoop
在slave1中,访问自己和master,并输入“yes”
ssh master.hadoop ssh slave1.hadoop
在slave2中,访问自己和master,并输入“yes”
ssh master.hadoop ssh slave2.hadoop
三、安装Java JDK
1、下载java JDK
2、解压到/usr/lib/jdk
3、配置/etc/profile环境变量
export JAVA_HOME=/usr/lib/jdk export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
4、使环境变量生效
source /etc/profile
5、检查Java是否安装成功
java -version
如果正确显示版本号,即配置成功
java version "1.8.0_66" Java(TM) SE Runtime Environment (build 1.8.0_66-b17) Java HotSpot(TM) 64-Bit Server VM (build 25.66-b17, mixed mode)
四、安装Hadoop
1、下载Hadoop 1.2.1
wget https://archive.apache.org/dist/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz
2、解压到/usr/local/hadoop
3、创建文件系统目录/usr/local/hadoop/tmp
mkdir /usr/local/hadoop/tmp
4、配置环境变量/etc/profile
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
并使环境变量生效
source /etc/profile
5、检查Hadoop是否安装成功
hadoop version
五、配置Hadoop
进入/usr/local/hadoop/conf目录
1、修改masters文件
master.hadoop
2、修改slaves文件
slave1.hadoop
slave2.hadoop
3、配置hadoop-env.sh
加入Java JDK路径
export JAVA_HOME=/usr/lib/jdk
4、配置core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>temp dir</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master.hadoop:9000</value>
</property>
</configuration>
5、配置hdfs-site.xml
(因为只有2个slave,所以replication的值为1,多个机器可以增加)
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
6、配置mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>http://master.hadoop:9001</value>
</property>
</configuration>
六、启动Hadoop
1、格式化文件分区(仅需一次)
进入/usr/local/hadoop/bin目录,运行
/usr/local/hadoop/bin/hadoop namenode -format
格式化成功后在/usr/local/hadoop/tmp目录下会有dfs和mapred两个子目录
2、启动hadoop
/usr/local/hadoop/bin/start-all.sh
3、停止hadoop
/usr/local/hadoop/bin/stop-all.sh
4、查看hadoop运行状态
master上输入:jps
3798 Jps 3450 NameNode 3690 JobTracker 3596 SecondaryNameNode
slave上输入:jps
2148 Jps 1988 DataNode 2072 TaskTracker
七、任务查看
1、HDFS任务查看
在浏览器中输入
master ip:50070
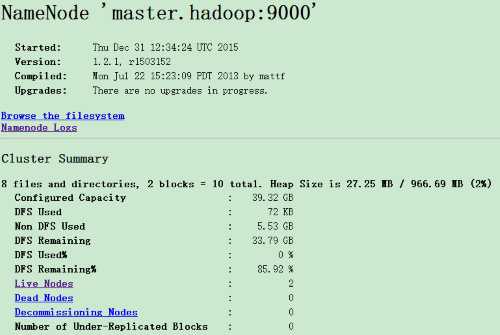
点击Live Nodes,可以看到

尝试建立一个500MB的文件,并传入HDFS文件系统
dd if=/dev/zero of=/root/test bs=1k count=512000 hadoop dfs -put ~/test test

Map/Reduce任务查看
master ip:50030
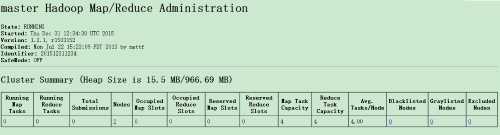
标签:
原文地址:http://www.cnblogs.com/imzye/p/5092597.html