标签:
---恢复内容开始---
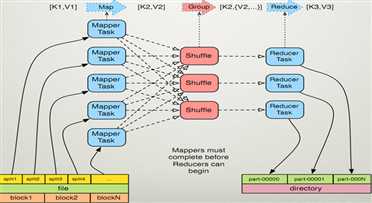
什么是MapReduce?
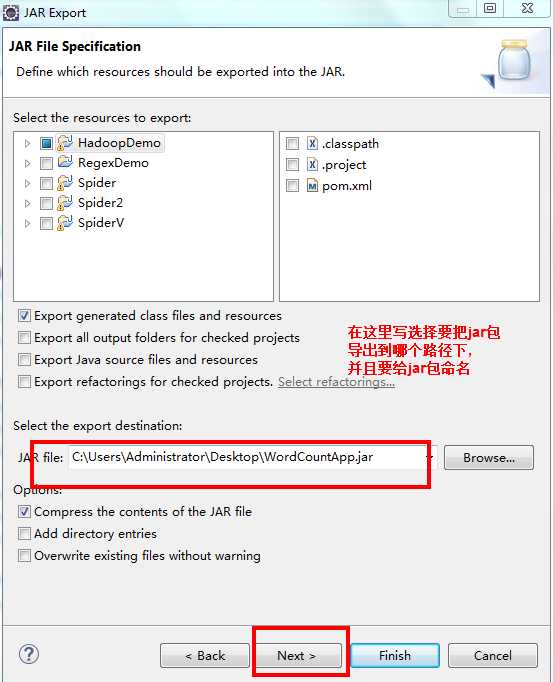
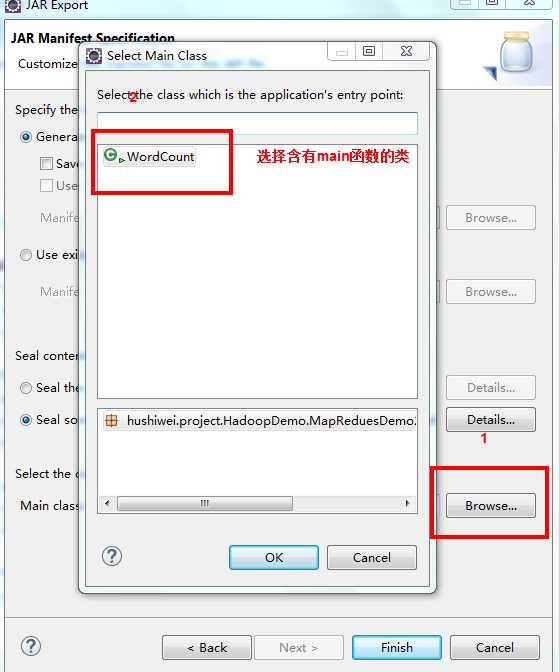
public class WordCountApp { //自定义的mapper,目的是实现自己的业务逻辑,所以继承org.apache.hadoop.mapreduce.MapperpublicstaticclassMyMapperextends org.apache.hadoop.mapreduce.Mapper<LongWritable,Text,Text,LongWritable>{//k1表示//v1表示一行的文本内容@Overrideprotectedvoid map(LongWritable key,Text value,Mapper<LongWritable,Text,Text,LongWritable>.Context context)throwsIOException,InterruptedException{//转换成String类型,目的是使用String的方法String line = value.toString();String[] splited = line.split("\t");for(String word : splited){ context.write(newText(word),newLongWritable(1));}}}//经过mapper操作后,产生4个<k2,v2>,分别是<hello,1>、<you,1>、<hello,1>、<me,1>//按照k2进行排序//通过框架分组,产生3个组,分别是<hello,{1,1}><me,{1}><you,{1}>publicstaticclassMyReducerextends org.apache.hadoop.mapreduce.Reducer<Text,LongWritable,Text,LongWritable>{//函数被调用3次,传入的形参分别是<hello,{1,1}>、<me,{1}>、<you,{1}>@Overrideprotectedvoid reduce(Text k2,Iterable<LongWritable> v2s,Reducer<Text,LongWritable,Text,LongWritable>.Context context)throwsIOException,InterruptedException{long count =0L;for(LongWritable v2 : v2s){ count += v2.get();}LongWritable v3 =newLongWritable(count); context.write(k2, v3);}}//客户端代码,写完交给ResourceManager框架去执行publicstaticvoid main(String[] args)throwsException{Configuration conf =newConfiguration();Job job =Job.getInstance(conf,WordCountApp.class.getSimpleName());//打成jar执行 job.setJarByClass(WordCountApp.class);//数据在哪里?FileInputFormat.setInputPaths(job, args[0]);//使用哪个mapper处理输入的数据? job.setMapperClass(MyMapper.class);//map输出的数据类型是什么? job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class);//使用哪个reducer处理输入的数据? job.setReducerClass(MyReducer.class);//reduce输出的数据类型是什么? job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class);//数据输出到哪里?FileOutputFormat.setOutputPath(job,newPath(args[1]));//交给yarn去执行,直到执行结束才退出本程序 job.waitForCompletion(true);}}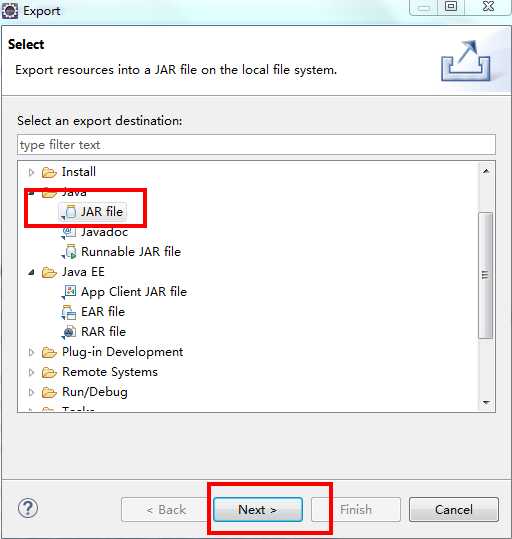

[root@node134 hadoop-2.6.0]# bin/hdfs dfs -put hello.txt /15/12/3117:44:05 WARN util.NativeCodeLoader:Unable to load native-hadoop library for your platform... using builtin-java classes where applicable[root@node134 hadoop-2.6.0]# bin/hdfs dfs -ls /15/12/3117:44:08 WARN util.NativeCodeLoader:Unable to load native-hadoop library for your platform... using builtin-java classes where applicableFound4 itemsdrwxr-xr-x - root supergroup 02015-12-3117:21/dir1-rw-r--r--1 root supergroup 192015-12-3117:44/hello.txtdrwx------- root supergroup 02015-12-3117:23/tmpdrwx------- root supergroup 02015-12-3117:28/user[root@node134 hadoop-2.6.0]# bin/hadoop jar APPS/WordCountApp.jar /hello.txt /out 
publicstaticvoid main(String[] args)throwsException{Configuration conf =newConfiguration();//加载配置文件Job job =newJob(conf);//创建一个job,供JobTracker使用 job.setJarByClass(WordCountApp.class); job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class);FileInputFormat.setInputPaths(job,newPath("hdfs://192.168.1.10:9000/input"));FileOutputFormat.setOutputPath(job,newPath("hdfs://192.168.1.10:9000/output")); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.waitForCompletion(true);}




---恢复内容结束---
什么是MapReduce?
public class WordCountApp { //自定义的mapper,目的是实现自己的业务逻辑,所以继承org.apache.hadoop.mapreduce.MapperpublicstaticclassMyMapperextends org.apache.hadoop.mapreduce.Mapper<LongWritable,Text,Text,LongWritable>{//k1表示//v1表示一行的文本内容@Overrideprotectedvoid map(LongWritable key,Text value,Mapper<LongWritable,Text,Text,LongWritable>.Context context)throwsIOException,InterruptedException{//转换成String类型,目的是使用String的方法String line = value.toString();String[] splited = line.split("\t");for(String word : splited){ context.write(newText(word),newLongWritable(1));}}}//经过mapper操作后,产生4个<k2,v2>,分别是<hello,1>、<you,1>、<hello,1>、<me,1>//按照k2进行排序//通过框架分组,产生3个组,分别是<hello,{1,1}><me,{1}><you,{1}>publicstaticclassMyReducerextends org.apache.hadoop.mapreduce.Reducer<Text,LongWritable,Text,LongWritable>{//函数被调用3次,传入的形参分别是<hello,{1,1}>、<me,{1}>、<you,{1}>@Overrideprotectedvoid reduce(Text k2,Iterable<LongWritable> v2s,Reducer<Text,LongWritable,Text,LongWritable>.Context context)throwsIOException,InterruptedException{long count =0L;for(LongWritable v2 : v2s){ count += v2.get();}LongWritable v3 =newLongWritable(count); context.write(k2, v3);}}//客户端代码,写完交给ResourceManager框架去执行publicstaticvoid main(String[] args)throwsException{Configuration conf =newConfiguration();Job job =Job.getInstance(conf,WordCountApp.class.getSimpleName());//打成jar执行 job.setJarByClass(WordCountApp.class);//数据在哪里?FileInputFormat.setInputPaths(job, args[0]);//使用哪个mapper处理输入的数据? job.setMapperClass(MyMapper.class);//map输出的数据类型是什么? job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class);//使用哪个reducer处理输入的数据? job.setReducerClass(MyReducer.class);//reduce输出的数据类型是什么? job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class);//数据输出到哪里?FileOutputFormat.setOutputPath(job,newPath(args[1]));//交给yarn去执行,直到执行结束才退出本程序 job.waitForCompletion(true);}}[root@node134 hadoop-2.6.0]# bin/hdfs dfs -put hello.txt /15/12/3117:44:05 WARN util.NativeCodeLoader:Unable to load native-hadoop library for your platform... using builtin-java classes where applicable[root@node134 hadoop-2.6.0]# bin/hdfs dfs -ls /15/12/3117:44:08 WARN util.NativeCodeLoader:Unable to load native-hadoop library for your platform... using builtin-java classes where applicableFound4 itemsdrwxr-xr-x - root supergroup 02015-12-3117:21/dir1-rw-r--r--1 root supergroup 192015-12-3117:44/hello.txtdrwx------- root supergroup 02015-12-3117:23/tmpdrwx------- root supergroup 02015-12-3117:28/user[root@node134 hadoop-2.6.0]# bin/hadoop jar APPS/WordCountApp.jar /hello.txt /out publicstaticvoid main(String[] args)throwsException{Configuration conf =newConfiguration();//加载配置文件Job job =newJob(conf);//创建一个job,供JobTracker使用 job.setJarByClass(WordCountApp.class); job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class);FileInputFormat.setInputPaths(job,newPath("hdfs://192.168.1.10:9000/input"));FileOutputFormat.setOutputPath(job,newPath("hdfs://192.168.1.10:9000/output")); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.waitForCompletion(true);}标签:
原文地址:http://www.cnblogs.com/hsw-time/p/5092822.html